מדריך | ספרי ספריא ותורת אמת בepub בעזרת python + calibre
-
עדכון:
העליתי את תורת אמת לכאן:
https://github.com/zevisvei/epub-Jewish-books/tree/main
הועלו גם שאר המאגרים חוץ מספריא, אני אעבוד על ספריא בבין הזמנים בלי נדרכידוע יש הרבה ספרי חול בפורמט epub , חיפשתי בנרות ספרי קודש ומצאתי רק מתי מעט, להלן רשימה של מה שמצאתי:
- https://github.com/yparitcher/kindle-seforim
- https://www.toratemetfreeware.com/index.html?downloads;10;
- https://www.daat.ac.il/EPUB/home.asp
וגם בחלקם כיוון הדפדוף הוא משמאל לימין
יש ספרי טקסט מספריא שאפשר להמיר אותם בעזרת קליבר, אבל הבעיה היא - א'- הטקסט מיושר לשמאל, ב'- כיוון הגלילה הוא משמאל לימין, ג' - אין תוכן עניינים
למעשה כתבתי שני סקריפטים שאמורים לסדר את הבעיה:
א': המרת ספרי הטקסט לhtml ,יישור לימין והוספת תגיות כותרתimport os def convert_in_folder(folder_path): for root, _, files in os.walk(folder_path): for file_name in files: if file_name.endswith('.html'): file_path = os.path.join(root, file_name) process_html_file(file_path) elif file_name.endswith(".txt"): old_path = os.path.join(root, file_name) new_path = os.path.join(root, file_name[:-4] + ".html") os.rename(old_path, new_path) process_html_file(new_path) def get_book_title_and_author(input_file): # Read the second and fourth lines of the HTML file with open(input_file, 'r', encoding='utf-8') as file: lines = file.readlines() title = lines[1].strip() if len(lines) >= 2 else 'Untitled Book' return title def process_html_file(input_file, input_encoding='utf-8'): with open(input_file, 'r', encoding=input_encoding) as f: html_content = f.read() processed_lines = [] processed_lines_2 = [f'''<html xmlns="http://www.w3.org/1999/xhtml" lang="he" xml:lang="he" dir="rtl"> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <head> <title>'''+get_book_title_and_author(input_file)+f'''</title> <meta http-equiv="content-type" content="text/html;charset=utf-8" /> <meta http-equiv="content-language" content="he" /> </head> <body lang="he-IL" xml:lang="he-IL"> <div class="Basic-Text-Frame" dir="rtl">'''] # Split lines and process each line lines = html_content.splitlines() lest_line = 0 line_index = 0 first = False for line in lines: # Process lines with #, @, ~ if line.startswith('#') and len(line) <= 20: processed_lines.append(f'<h1 class="bookTitle">{line[2:]}</h1>') lest_line=1 first = True elif line.startswith('@') and len(line) <= 20: if not first: processed_lines.append(f'<h1 class="subbookTitle">{line[2:]}</h1>') lest_line = 1 elif first: processed_lines.append(f'<h2 class="chapter">{line[2:]}</h2>') lest_line = 2 elif line.startswith('~') and len(line) <= 20: if lest_line > 1: processed_lines.append(f'<h3 class="section">{line[2:]}</h3>') lest_line=3 elif lest_line == 1: processed_lines.append(f'<h2 class="chapter">{line[2:]}</h2>') elif lest_line == 0: processed_lines.append(f'<h1 class="bookTitle">{line[2:]}</h1>') elif line != "": processed_lines.append('<p class="text">' + line + '</p>') for line in processed_lines: try: line_index+=1 next_line = processed_lines[line_index] if line.startswith(f'<h') and next_line.startswith(f'<h') and line[:14] == next_line[:14]: pass else: processed_lines_2.append(line) except IndexError: processed_lines_2.append(line) processed_lines_2.append(f''' </head> </div> <body> </html>''') # Join the processed lines back into HTML content processed_html = '\n'.join(processed_lines_2) # Write the modified HTML content to the output file with open(input_file, 'w', encoding='utf-8') as f: f.write(processed_html) folder_path = r'.\נתיב יחסי' convert_in_folder(folder_path)ב': תיקון כיוון הסיבוב
import os import zipfile def edit_in_folder(folder_path): for root, _, files in os.walk(folder_path): for file_name in files: if file_name.endswith('.epub'): file_path = os.path.join(root, file_name) edit_epub_spine(file_path) def edit_epub_spine(srcfile): a = b'<spine toc="ncx">' b = b'<spine toc="ncx" page-progression-direction="rtl">' c = b'<spine>' temp_file = srcfile + "_temp" with zipfile.ZipFile(srcfile, "r") as inzip, zipfile.ZipFile(temp_file, "w") as outzip: for inzipinfo in inzip.infolist(): with inzip.open(inzipinfo) as infile: if inzipinfo.filename == "content.opf": content = infile.read().replace(a, b).replace(c, b) outzip.writestr(inzipinfo.filename, content) else: outzip.writestr(inzipinfo.filename, infile.read()) os.remove(srcfile) os.rename(temp_file, srcfile) folder_path = r'.\נתיב יחסי' edit_in_folder(folder_path)מריצים את הסקריפט הראשון, נכנסים לקליבר ובוחרים הוסף ספרים, הוסף ספרים מתיקייה ותתי תיקיות בוחרים "לא" על השאלה האם מדובר באותם קבצים בפורמטים שונים, בוחרים את התיקייה ומוסיפים את הספרים לקליבר
אח"כ בוחרים את כל הספרים ובוחרים "המר ספרים"
שימו לב לבחור המר אחד אחר השני כי אחרת צריך להמיר כל ספר בנפרד
בוחרים את סוג הפלט [epub] ונכנסים ללשונית תוכן עניינים
צריך להכניס שם את הטקסט שנמצא בצילו"מ הבא:
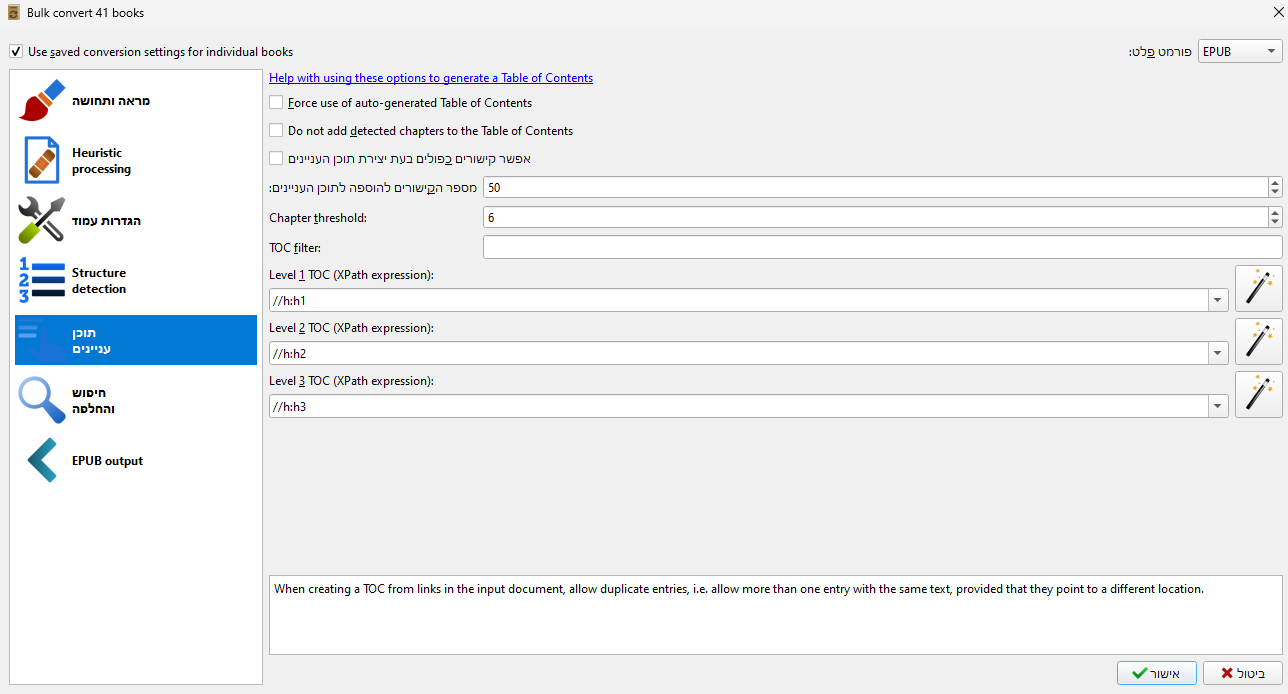
וממירים
אחרי ההמרה מריצים את הסקריפט השני
וזהו
עקרונית זה אמור לעבוד על כל קובץ טקסט, אבל הסקריפט הראשון לוקח את שם הספר משורה 2, כך שבמקרה ובשורה 2 יש טקסט אחר זה יהיה שמו של הספר
את ספרי הטקסט של ספריא ניתן להוריד מספריא אקספורט או מכאן
הסקריפט בונה את תגיות הכותרות לפי הסימוני כותרות של תורת אמת, כך שצריך להריץ את הקידודון של @pcinfogmach לפני כל התהליך
רמות כותרות מנפקמות לתוכן העניינים
הסקריפטים רצים על תיקיות ותתי תיקיות, עדיף לשים בנתיב נתיב יחסי [הסקריפט השני עושה לפעמים בעיות בנתיבים מסויימים אם מכניסים נתיב מוחלט]
נ.ב.
הסקריפט עובד על קבצי טקסט בקידוד utf-8
ניתן להמיר ansi ל utf-8 בעזרת הקידודון, וכך בעצם לחסוך את עבודת הקידוד אם ניקח את הספרים מתורת אמת [אם כי אני לא יודע אם שם הקובץ מופיע בשורה 2 תמיד]
משום מה כשאני מנסה לפתוח קובץ epub שנוצר בצורה זו בעזרת sigil הוא טוען שיש בעיה בקידוד הhtml, אני לא מבין בhtml, אולי צריך לשנות את הסקריפט קצת, בכל מקרה הספרים נפתחים
הספרים בספריית קליבר נשמרים בסייר הקבצים עם שמות מחורבשים, ניתן תיאורטית לייצא לxml את הקטלוג ואז לשנות את שם הקובץ לפי הכותרת, ראו עוד כאן
אם יש לכם ספרים באנגלית או כל שפה אחרת שנקראת משמאל לימין הסקריפט השני ישנה את כיוון הסיבוב, שימו לב לשנות ספריה לפני שאתם מוסיפים את ספרי ספריא כדי שהם יהיו בתיקייה אחרת
תיאורטית ניתן להשתמש בסקריפט השני גם לחיפוש והחלפה בקבצי וורד מרובים [גם לשנות את המטא-דאטה] וכן בכל סוג קובץ מבוסס zip
כמובן שהיה עדיף לשמור על מבנה התיקיות של ספריא, אבל לא מצאתי עדיין דרך להמיר את הספרים בלי להוסיף אותם לקליבר
הסיבה שאני לא מעלה את הקבצים שלי היא משום שעוד לא מצאתי זמן לסדר את רמות הכותרות עם הקידודון
רעיונות לעתיד: להעביר את הטקסט שבתחילת הספרים להערות הספר בעזרת הספרייה EbookLib או משהו בסגנון
הסקריפט הראשון גם מסיר כותרות ריקות [מצוי מאוד בספריא] -
עדכון: כתבתי סקריפט לספרי תורת אמת באופן ספציפי [כולל גם המרת קידוד וכותרות שקיימות רק שם ולא בקידודון, כגון $,^ ו!
import os def convert_in_folder(folder_path): for root, _, files in os.walk(folder_path): for file_name in files: if file_name.lower().endswith(".txt"): old_path = os.path.join(root, file_name) new_path = os.path.join(root, file_name[:-4] + ".html") os.rename(old_path, new_path) convert_encoding(new_path) def convert_encoding(file_path): try: with open(file_path, 'r', encoding='windows-1255') as ansi_file: content = ansi_file.read() # Remove un convertible characters content = content.encode('utf-8', 'ignore').decode('utf-8') with open(file_path, 'w', encoding='utf-8') as utf8_file: utf8_file.write(content) print(f"Converted: {file_path}") process_html_file(file_path) except Exception as e: print(f"Error converting {file_path}: {e}") os.remove(file_path) def process_html_file(input_file, input_encoding='utf-8'): with open(input_file, 'r', encoding=input_encoding) as f: html_content = f.read() processed_lines = [] lines = f.readlines() # Split lines and process each line lines = html_content.splitlines() lest_line = 0 lest_line_2 = "" line_index = 0 first = False bookTitle = 'Untitled Book' for line in lines[1:]: # Process lines with #, @, ~ if line.startswith('#'): processed_lines.append(f'<h1 class="bookTitle">{line[2:]}</h1>') lest_line=1 first = True elif line.startswith('^'): processed_lines.append(f'<h1 class="bbookTitle">{line[2:]}</h1>') lest_line=1 first = True elif line.startswith('@'): if not first: processed_lines.append(f'<h1 class="subbookTitle">{line[2:]}</h1>') lest_line = 1 elif first: processed_lines.append(f'<h2 class="chapter">{line[2:]}</h2>') lest_line = 2 elif line.startswith('~'): if lest_line > 1: processed_lines.append(f'<h3 class="section">{line[2:]}</h3>') lest_line=3 elif lest_line == 1: processed_lines.append(f'<h2 class="chapter">{line[2:]}</h2>') elif lest_line == 0: processed_lines.append(f'<h1 class="bookTitle">{line[2:]}</h1>') elif line.startswith("!"): lest_line_2 = line[2:] elif line.startswith("$"): if len(line) >= 2: bookTitle = line[2:] elif line != "": if lest_line_2 != "": processed_lines.append('<p class="text">'+ lest_line_2 + " " + line + '</p>') lest_line_2 = "" else: processed_lines.append('<p class="text">' + line + '</p>') processed_lines_2 = [f'''<html xmlns="http://www.w3.org/1999/xhtml" lang="he" xml:lang="he" dir="rtl"> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <head> <title>'''+bookTitle+f'''</title> <meta http-equiv="content-type" content="text/html;charset=utf-8" /> <meta http-equiv="content-language" content="he" /> </head> <body lang="he-IL" xml:lang="he-IL"> <div class="Basic-Text-Frame" dir="rtl">'''] for line in processed_lines: try: line_index+=1 next_line = processed_lines[line_index] if line.startswith(f'<h') and next_line.startswith(f'<h') and line[:15] == next_line[:15]: pass else: processed_lines_2.append(line) except IndexError: processed_lines_2.append(line) processed_lines_2.append(f''' </head> </div> <body> </html>''') # Join the processed lines back into HTML content processed_html = '\n'.join(processed_lines_2) # Write the modified HTML content to the output file with open(input_file, 'w', encoding='utf-8') as f: f.write(processed_html) print(f"processed: {input_file}") folder_path = r'.\Books' convert_in_folder(folder_path)פשוט מעתיקים את תיקיית books מתיקיית ההתקנה של תורת אמת ומריצים על זה את הסקריפט
אח"כ מוסיפים לקליבר ,ממירים ואז מריצים את הסקריפט השני
שימו לב שהסקריפט משנה את הקבצים, כך שאין להריץ את הסקריפט על התיקייה המקורית בתורת אמת
שימו לב שיש שם ספרים שרק משמשים כחיבור בין הספר למפרשיו, הספרים עם טעמים לא מוצגים כראוי מכיון שבתורת אמת יש קידוד מיוחד לטעמים ושבתחילת כל ספר יש טקסט באנגלית, אולי ל @pcinfogmach יש רשימה של הספרים שלא מכילים כלום ואולי יש לו גם רעיון איך להסיר את הטקסט חסר המשמעות בתחילת הספרים -
עדכון: כתבתי סקריפט לספרי תורת אמת באופן ספציפי [כולל גם המרת קידוד וכותרות שקיימות רק שם ולא בקידודון, כגון $,^ ו!
import os def convert_in_folder(folder_path): for root, _, files in os.walk(folder_path): for file_name in files: if file_name.lower().endswith(".txt"): old_path = os.path.join(root, file_name) new_path = os.path.join(root, file_name[:-4] + ".html") os.rename(old_path, new_path) convert_encoding(new_path) def convert_encoding(file_path): try: with open(file_path, 'r', encoding='windows-1255') as ansi_file: content = ansi_file.read() # Remove un convertible characters content = content.encode('utf-8', 'ignore').decode('utf-8') with open(file_path, 'w', encoding='utf-8') as utf8_file: utf8_file.write(content) print(f"Converted: {file_path}") process_html_file(file_path) except Exception as e: print(f"Error converting {file_path}: {e}") os.remove(file_path) def process_html_file(input_file, input_encoding='utf-8'): with open(input_file, 'r', encoding=input_encoding) as f: html_content = f.read() processed_lines = [] lines = f.readlines() # Split lines and process each line lines = html_content.splitlines() lest_line = 0 lest_line_2 = "" line_index = 0 first = False bookTitle = 'Untitled Book' for line in lines[1:]: # Process lines with #, @, ~ if line.startswith('#'): processed_lines.append(f'<h1 class="bookTitle">{line[2:]}</h1>') lest_line=1 first = True elif line.startswith('^'): processed_lines.append(f'<h1 class="bbookTitle">{line[2:]}</h1>') lest_line=1 first = True elif line.startswith('@'): if not first: processed_lines.append(f'<h1 class="subbookTitle">{line[2:]}</h1>') lest_line = 1 elif first: processed_lines.append(f'<h2 class="chapter">{line[2:]}</h2>') lest_line = 2 elif line.startswith('~'): if lest_line > 1: processed_lines.append(f'<h3 class="section">{line[2:]}</h3>') lest_line=3 elif lest_line == 1: processed_lines.append(f'<h2 class="chapter">{line[2:]}</h2>') elif lest_line == 0: processed_lines.append(f'<h1 class="bookTitle">{line[2:]}</h1>') elif line.startswith("!"): lest_line_2 = line[2:] elif line.startswith("$"): if len(line) >= 2: bookTitle = line[2:] elif line != "": if lest_line_2 != "": processed_lines.append('<p class="text">'+ lest_line_2 + " " + line + '</p>') lest_line_2 = "" else: processed_lines.append('<p class="text">' + line + '</p>') processed_lines_2 = [f'''<html xmlns="http://www.w3.org/1999/xhtml" lang="he" xml:lang="he" dir="rtl"> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <head> <title>'''+bookTitle+f'''</title> <meta http-equiv="content-type" content="text/html;charset=utf-8" /> <meta http-equiv="content-language" content="he" /> </head> <body lang="he-IL" xml:lang="he-IL"> <div class="Basic-Text-Frame" dir="rtl">'''] for line in processed_lines: try: line_index+=1 next_line = processed_lines[line_index] if line.startswith(f'<h') and next_line.startswith(f'<h') and line[:15] == next_line[:15]: pass else: processed_lines_2.append(line) except IndexError: processed_lines_2.append(line) processed_lines_2.append(f''' </head> </div> <body> </html>''') # Join the processed lines back into HTML content processed_html = '\n'.join(processed_lines_2) # Write the modified HTML content to the output file with open(input_file, 'w', encoding='utf-8') as f: f.write(processed_html) print(f"processed: {input_file}") folder_path = r'.\Books' convert_in_folder(folder_path)פשוט מעתיקים את תיקיית books מתיקיית ההתקנה של תורת אמת ומריצים על זה את הסקריפט
אח"כ מוסיפים לקליבר ,ממירים ואז מריצים את הסקריפט השני
שימו לב שהסקריפט משנה את הקבצים, כך שאין להריץ את הסקריפט על התיקייה המקורית בתורת אמת
שימו לב שיש שם ספרים שרק משמשים כחיבור בין הספר למפרשיו, הספרים עם טעמים לא מוצגים כראוי מכיון שבתורת אמת יש קידוד מיוחד לטעמים ושבתחילת כל ספר יש טקסט באנגלית, אולי ל @pcinfogmach יש רשימה של הספרים שלא מכילים כלום ואולי יש לו גם רעיון איך להסיר את הטקסט חסר המשמעות בתחילת הספרים@האדם-החושב כתב במדריך | ספרי ספריא ותורת אמת בepub בעזרת python + calibre:
אולי ל @pcinfogmach יש רשימה של הספרים שלא מכילים כלום
בגדול זה קבצים שמכילים בתוך השם שלהם את אחד מהמילים דלהלן
Interleave|merged|DebugMix@האדם-החושב כתב במדריך | ספרי ספריא ותורת אמת בepub בעזרת python + calibre:
ואולי יש לו גם רעיון איך להסיר את הטקסט חסר המשמעות בתחילת הספרים
בגדול זה השורה הראשונה במסמך כך שאם תעקוף את השורה הראשונה והשניה זה כבר יעזור אבל לא תמיד.
אישית אני עושה את זה על ידי איתור השורה הראשונה בה יש קידוד כותרות.מצו"ב רשימה של הטעמים והחלפותיהם (יש להקפיד על הסדר):
text = text.Replace(@"+\++\++\++\+", "֦"); text = text.Replace(@"\\\+\++\\\++", "֟"); text = text.Replace(@"+\+\\++++++\", "֝֗"); text = text.Replace(@"\++\\\+++++\\++\\\", "͘͘"); text = text.Replace(@"\++\\\\++\\\", "͘"); text = text.Replace(@"+\++\+\\\\++", "A8;A5;"); text = text.Replace(@"\+\\++", "֪"); text = text.Replace(@"+\\\\+", "֙"); text = text.Replace(@"\\\\++", "֙"); text = text.Replace(@"++\+\+", "֣"); text = text.Replace(@"\\\\\+", "֘"); text = text.Replace(@"\+\++\", "֒"); text = text.Replace(@"+++++\", "֗"); text = text.Replace(@"\\+++\", "֔"); text = text.Replace(@"+\+++\", "֕"); text = text.Replace(@"+\++\+", "֥"); text = text.Replace(@"\++++\", "֖"); text = text.Replace(@"+\\++\", "֑"); text = text.Replace(@"+\\+\+", "֡"); text = text.Replace(@"+\\\++", "֩"); text = text.Replace(@"\\\+\+", "֠"); text = text.Replace(@"\\+\\+", "֜"); text = text.Replace(@"\++\\+", "֞"); text = text.Replace(@"++++\+", "֧"); text = text.Replace(@"++\\\+", "֛"); text = text.Replace(@"\\++\+", "֤"); text = text.Replace(@"++\++\", "֓"); text = text.Replace(@"++\++\", "֚"); text = text.Replace(@"\+\\\+", "֚"); text = text.Replace(@"\++\++", "֮"); text = text.Replace(@"++\\++", "֫"); text = text.Replace(@"+\+\++", "֭"); text = text.Replace(@"+\+\\+", "֝"); text = text.Replace(@"\\+\++", "֬"); text = text.Replace(@"\\+\++", "֬"); -
א. האם אפשר הדרכה למי שלא מתמצא כלל בשורות קוד?
ב. האם אפשר להמיר קובץ pdf עם צורה מסוימת (כגון תלמוד-צורת הדף) לפורמט epub ושהצורה תישאר?
תודה@DAVID-3 כתב במדריך | ספרי ספריא ותורת אמת בepub בעזרת python + calibre:
א. האם אפשר הדרכה למי שלא מתמצא כלל בשורות קוד?
קצת מסובך, אני עובד כרגע על גיר' סופית ואני אעלה את הקבצים עצמם בלנ"ד לגיטהאב
ב. האם אפשר להמיר קובץ pdf עם צורה מסוימת (כגון תלמוד-צורת הדף) לפורמט epub ושהצורה תישאר?
תודהעקרונית אפשר בהמרה בתור תמונה, אבל למה שלא תשתמש בpdf עצמו?
-
@DAVID-3 כתב במדריך | ספרי ספריא ותורת אמת בepub בעזרת python + calibre:
א. האם אפשר הדרכה למי שלא מתמצא כלל בשורות קוד?
קצת מסובך, אני עובד כרגע על גיר' סופית ואני אעלה את הקבצים עצמם בלנ"ד לגיטהאב
ב. האם אפשר להמיר קובץ pdf עם צורה מסוימת (כגון תלמוד-צורת הדף) לפורמט epub ושהצורה תישאר?
תודהעקרונית אפשר בהמרה בתור תמונה, אבל למה שלא תשתמש בpdf עצמו?
-
@האדם-החושב
ראשית תודה רבה
קובץ PDF לא נוח לי כיון שאי אפשר לרשום עליו הערות באפליקציית קורא ספרים אלקטרוני -
@DAVID-3
אולי אפשר לעשות embedding Tת הקובץ pdf בתוך html -
@pcinfogmach
מה זה?אין לי זמן כרגע להאריך הנה תשובה מאת מכרנו chatgpt
הטכניקה הנפוצה להטבעת קבצי PDF בתוך דף HTML היא באמצעות תג <iframe>. ניתן להשתמש בתג זה כדי להציג את קובץ ה-PDF בתוך חלון בדף HTML.הנה דוגמה לכיצד לעשות זאת:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Embed PDF</title> </head> <body> <iframe src="example.pdf" width="600" height="780" style="border: none;"></iframe> </body> </html>בדוגמה זו:
- ה-<iframe> מצביע לכתובת של קובץ ה-PDF באמצעות ה-attribut ה-
src. widthו-heightמגדירים את גודל ה-<iframe>.- ה-style "border: none;" מוסיף עיצוב נקי לקובץ ה-PDF.
כדי להשתמש בקובץ PDF מהמערכת שלך, פשוט כתוב את הנתיב המלא של הקובץ במקום "example.pdf" בתוך ה-attribut של
src. - ה-<iframe> מצביע לכתובת של קובץ ה-PDF באמצעות ה-attribut ה-
-
אין לי זמן כרגע להאריך הנה תשובה מאת מכרנו chatgpt
הטכניקה הנפוצה להטבעת קבצי PDF בתוך דף HTML היא באמצעות תג <iframe>. ניתן להשתמש בתג זה כדי להציג את קובץ ה-PDF בתוך חלון בדף HTML.הנה דוגמה לכיצד לעשות זאת:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Embed PDF</title> </head> <body> <iframe src="example.pdf" width="600" height="780" style="border: none;"></iframe> </body> </html>בדוגמה זו:
- ה-<iframe> מצביע לכתובת של קובץ ה-PDF באמצעות ה-attribut ה-
src. widthו-heightמגדירים את גודל ה-<iframe>.- ה-style "border: none;" מוסיף עיצוב נקי לקובץ ה-PDF.
כדי להשתמש בקובץ PDF מהמערכת שלך, פשוט כתוב את הנתיב המלא של הקובץ במקום "example.pdf" בתוך ה-attribut של
src. - ה-<iframe> מצביע לכתובת של קובץ ה-PDF באמצעות ה-attribut ה-
-
@pcinfogmach
אין לי מושג בכתיבת קוד
איפה אני צריך להעתיק את השורות הנ״ל?
בשורת הפקודה? -
@DAVID-3
תיצור מסמך טקסט
העתק אליו את הקוד עקוב אחר כל ההוראות של מכרנו
ואח"כ שנה את הסיומת שלו מ-.txt
ל-.html -
@pcinfogmach
ואז מה לעשות עם קובץ הhtml? -
@DAVID-3
תפתח אותו ותראה אם הוא עובד ואם הוא עושה את מה שרצית -
@pcinfogmach
לא עשה שום דבר
חוץ מלפתוח חלון אינטרנט.@DAVID-3
תנסה לחקור את הנושא בעצמך אין לי מושג בעצמי רק שמעתי על זה פעם ואמרתי אולי ה עובד
https://pdf.wondershare.com/how-to/embed-pdf-in-html.html -
@DAVID-3 כתב במדריך | ספרי ספריא ותורת אמת בepub בעזרת python + calibre:
א. האם אפשר הדרכה למי שלא מתמצא כלל בשורות קוד?
קצת מסובך, אני עובד כרגע על גיר' סופית ואני אעלה את הקבצים עצמם בלנ"ד לגיטהאב
ב. האם אפשר להמיר קובץ pdf עם צורה מסוימת (כגון תלמוד-צורת הדף) לפורמט epub ושהצורה תישאר?
תודהעקרונית אפשר בהמרה בתור תמונה, אבל למה שלא תשתמש בpdf עצמו?
@האדם-החושב כתב במדריך | ספרי ספריא ותורת אמת בepub בעזרת python + calibre:
א. האם אפשר הדרכה למי שלא מתמצא כלל בשורות קוד?
קצת מסובך, אני עובד כרגע על גיר' סופית ואני אעלה את הקבצים עצמם בלנ"ד לגיטהאב
עדכון:
העליתי את תורת אמת לכאן:
https://github.com/zevisvei/epub-Jewish-books/tree/main -
הועלו גם שאר המאגרים חוץ מספריא, אני אעבוד על ספריא בבין הזמנים בלי נדר
-
@האדם-החושב אפשר אולי שתעשה את זה על סידור חבד של ספריא? אני פשוט לא הצלחתי
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}