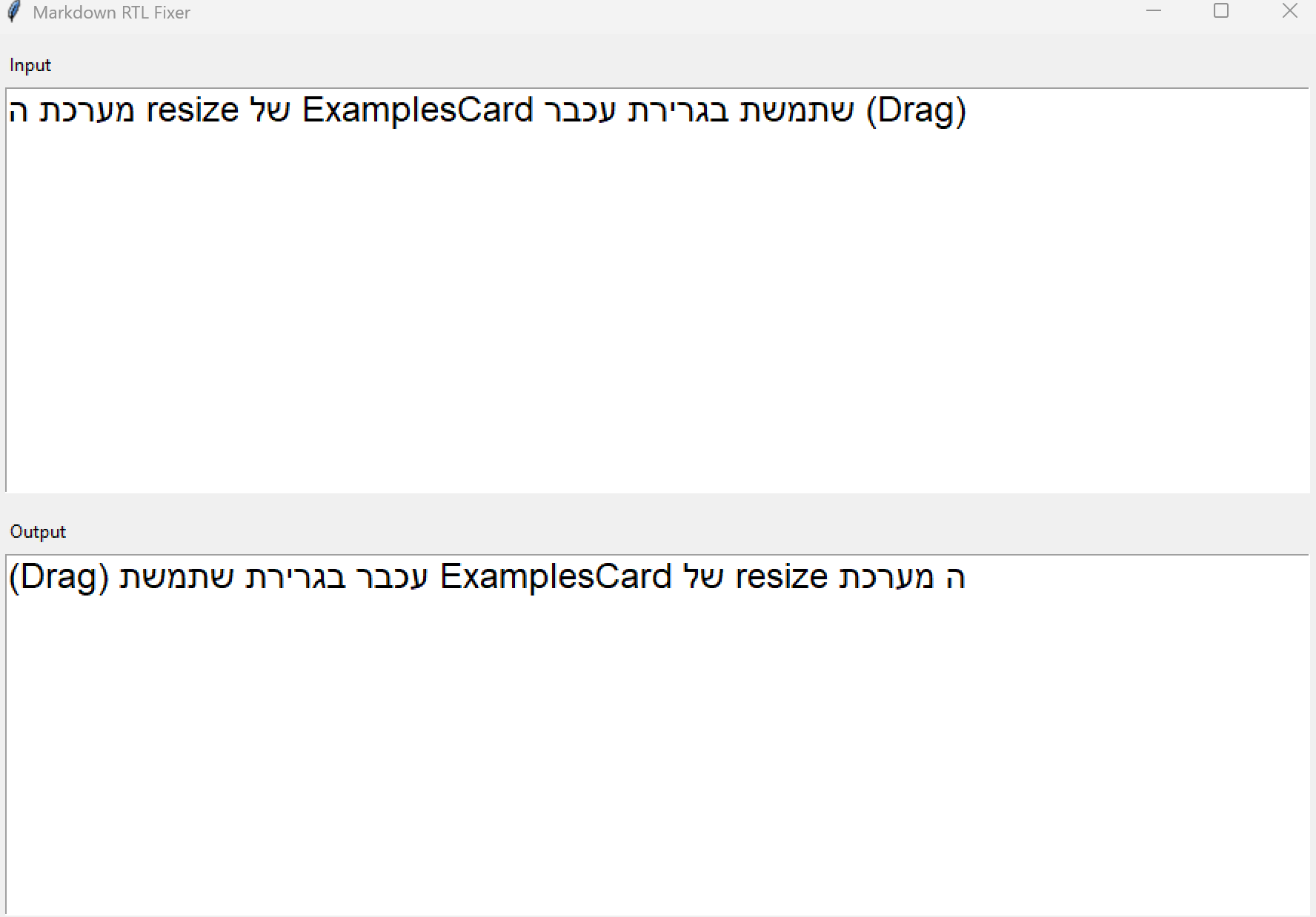
@אבינדב כתב:
עכשיו הרצתי את זה ככה
for i in range(1, 51):
if i % 10 == 0:
print(i // 10)
else:
print(i/10, end=" ")
וזה יצא אותו דבר.
כי פה לא עיצבת מחרוזת מיוחדת ה־f היה נחוץ רק אם רצית לשלוט בדיוק על מספר הספרות אחרי הנקודה
@מענין-לשמוע פירוק קוד פייתון "מקומפל" אפשרי רק אם ארזת את זה עם כלי אריזה כמו pyinstaller py2exe או cx_Freeze
במצב כזה אפשר לפרק את ה exe עם הסקריפט pyinstxtractor שהובא כאן (יעיל ל pyinstaller בלבד - לאחרים יש כלים שונים) ואז לחפש את קבצי ה pyc שמכילים את הקוד שכתבת
בדרך כלל יהיה קובץ ראשי בתיקייה הראשית ואם היו קבצים אחרים שכתבת וייבאת לתוכו הם יהיו בתוך קובץ ה pyz
קבצי ה pyc מכילים את "קוד המכונה" של פייתון שנוצר מהקוד שאותו כתבת
יש כלים שמנסים לבנות מאותו קוד מכונה קוד פייתון קריא שלרוב ייצא מאוד דומה לקוד שכתבת במקור
בדרך כלל הם נכשלים בלולאות מורכבות או בלוקים של try - except
כלים נפוצים כאלו הם pycdc או האתר pylingual.io
לחילופין אתה יכול להביא לבינה כלשהי את ה bytecodes עצמם (אתה יכול להוציא את זה עם הספרייה dis שמגיעה כחלק מהספרייה הסטנדרטית של פייתון) כדי שתפיק לך מזה קוד שלם וקריא - בתנאי שזה לא ארוך מידי ושיש לך בינה מלאכותית טובה
אם ארזת עם כלים אחרים כמו nuitka אין דרך טובה לחלץ את הקוד
@hartkhartk כתב בבקשת מידע | אין כזה דבר עיצוב בפייתון? במה אתם משתמשים?:
אני כמפתח פולסטאק אני עושה את הממשק בנפרד עם ריאקט כך שהעיצוב זה html + css
כמו רובם.
אבל
כתב בבקשת מידע | אין כזה דבר עיצוב בפייתון? במה אתם משתמשים?:
@קלוצמך לא צריך שרת.
מספיק לעשות WebView.
ואמרתי כמה סיבות למה אני לא רוצה את זה.
אחת מהם (בשבילך @חובבן-מקצועי ) היא הגודל, אבל יש עוד כמה סיבות.
תודה בכל מקרה לכל העונים!
@אלישע-מואב-0 זה פשוט מאוד.
יש כזה דבר אפליקציית Web, שבה אתה משתמש בעיצוב של דף אינטרנט - html css js כשאתה רוצה לעדכן את העיצוב בעיקרון עד היום היית צריך לקמפל מחדש את התוכנה כלומר להוציא קובץ exe חדש,
ובא @css-0 וחידש שיש אפשרות לעדכן את העיצוב בלי לעדכן את הקובץ אקסה בעצמו...
רק חשוב לומר, את הקוד של הלוגיקה [לדוג' פייתון] לא ייתן לעדכן כך, וכן יצטרכו ליצור קובץ exe חדש.
@מד כתב במדריך | מדריך לקמפול אפליקציות ווב ל EXE.:
neutralino לכאורה יותר פשוט.
מומלץ מאוד! ביחוד בגלל שהגודל קובץ שיוצא הוא מזערי.
וכן זה תומך בכול הפלטפורמות.
@רק-טוב-לשני כתב בשאלה | התקנת ספריות בפייתון:
@מנעמע כתב בשאלה | התקנת ספריות בפייתון:
אני רוצה להתקין את כל ספריות הפייתון הקיימות-לצורך עבודה אופליין
{או לפחות את הנפוצות}
השאלות הם
א}האם בכלל זה אפשרי
ב}האם זה אמור מאוד להכביד על המחשב??
אשמח לעזור בענין במייל hayacoene@gmail.com
פשיייי
רק נרשמת לפורום וכבר עוזרת!!
שאפווווו
@עידו300 כתב בבעיה | זקוק בדחיפות לעזרת המומחים ב-stripe (ספרייט):
יוצרים קשר עם חברה כמו נדרים פלוס/טרנזילה/קארדקום וכו' ומבקשים לפתוח חשבון סליקה - ומודיעים את המטרה, זה חשוב מאוד! אחרת זה יכול להיות הלבנת הון!
אפילו בלי להיכנס לפן החוקי, בלי שהמקבלים יוציאו חשבונית לא תוכל להכיר בזה כהוצאה ותשלם המון מס

 { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}