מדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.
-
@jc324118983 כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש לי Ollama ואני רוצה לדעת האם יש הבדל גדול ביו זה לLM Studio
יש הבדל גדול, והוא מפורט במדריך למעלה.
@jc324118983 כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
וכמו כן אולי כדאי גם כן להרחיב על מודל תמונות
זה תחום אחר לגמרי, אולי בהמשך אני יוסיף את זה.
@א.מ.ד. כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש הבדל גדול, והוא מפורט במדריך למעלה.
סליחה. אבל מה שהתכונתי לשאול זה לאחד שהוא רק רוצה שאלות ותשובות וכדומה האם יש הבדל ביניהם.
ותודה על המדריך זה עשה לי סדר בכל הבלגן -
ביקשו ממני בכמה מקומות לכתוב מדריך על הרצת מודלי AI באופן מקומי, וסקירות על מודלים מתאימים, יחד עם אינספור שאלות כמו מה כדאי להריץ על חומרה כזאת וכזאת, איזה מודל טוב בעברית, וכו'.
מכיוון שלפי חוקי הפורום חל איסור על העלאת כלים ומודלים להרצה אופליין בשל פריצת סינונים, המדריך לא יכלול קישורים אליהם (ייתכן שיהיה אפשרי להוסיף רק קישורים רשמיים שמן הסתם חסומים בנטפרי, אבדוק בעז"ה מול מנהלי הפורום). אין מה לבקש באישי מודלים בדרייב, כי אני לא מתכוון להעלות.
אם יהיה שינוי בחוקי הפורום בנושא, המדריך יעודכן בהתאם.ביקשתי מ-Gemini שייצור לי אינפוגרפיקות להמחשה על בסיס קטעי המדריך שהעליתי לו, לנוחותכם.
רקע: המהפכה המקומית
במקביל לצמיחת מהפכת ה-AI בשנים האחרונות, מתרחשת מהפכה מעניינת לא פחות - מהפכת ה-AI המקומי.

למה בעצם אנשים מתאמצים להריץ מודלים מקומיים, כשאפשר פשוט להיכנס לדפדפן או לאפליקציה ולשוחח עם Gemini או GPT?יש לזה כמה סיבות, רובן פחות רלוונטיות עבורנו. הנה חלקן:
-
פרטיות: במודלי ענן, כל הנתונים נשלחים לשרת כלשהו במרחבי האינטרנט, ואנחנו לא יכולים להיות רגועים ב-100% שהם מאובטחים ולא מועברים הלאה. בשכבות השימוש החינמיות הנתונים בדרך כלל משמשים לאימון הגרסה הבאה של המודלים.
ועוד לא דיברנו על חברות, עמותות וארגונים ממשלתיים, שמובן מאליו שלא תמיד יכולים להשתמש במודל ענן, מטעמי חיסיון וצנעת הפרט, סודות מסחריים ועוד, ויש חשיבות גבוהה במיוחד לפרטיות, ומודל מקומי שרץ בתוך המשרד או החברה הוא הפיתרון היחיד. -
עלות: כשמשתמשים ב-AI במסות עצומות, העלות גבוהה מאד. גם כשמקודדים פרוייקטים שלמים ב-AI בפלטפורמות כמו קלוד קוד וכדומה, זה יכול להגיע לסכומים מאוד גבוהים, וכשמריצים מודל מספיק איכותי באופן מקומי העלות היחידה היא "רק" החומרה והחשמל.
-
אופליין: להסקה ללא חיבור לאינטרנט. מתאים למטיילים במקומות ללא אינטרנט, טסים במטוס, תת קרקע ואחרים ללא חיבור לאינטרנט.
מן הסתם זו הסיבה הנפוצה ביותר בקרב המגזר החרדי... -
עקיפת צנזורות: במדינות שבהן קיים פיקוח הדוק על תכני הרשת, כמו סין, רוסיה, איראן ועוד, יש ביקוש נרחב למודלי שפה פתוחים יותר שזמינים בכיס.
-
שעשוע נחמד
 : להנות מהמחשבה שיש לך GPT קטנטן בתוך הכיס... לראות את הפלאפון השברירי שלך פולט תשובות, מספר סיפורים ועוד, וכל זה ללא אינטרנט...
: להנות מהמחשבה שיש לך GPT קטנטן בתוך הכיס... לראות את הפלאפון השברירי שלך פולט תשובות, מספר סיפורים ועוד, וכל זה ללא אינטרנט...
(גילוי נאות: זו הסיבה האהובה עלי, ומה שגורם לי להשקיע בזה הרבה משעות הפנאי שלי...)
חומרה: RAM ו-VRAM
כדי להריץ מודל באופן מקומי, תנאי הסף הוא חומרה מספקת. ישנם שני מרכיבים עיקריים בחומרה שקריטיים להרצת מודלים:
-
RAM: הזיכרון הזמני של המחשב, שמשמש את המעבד לאחסון זמני של נתונים בזמן העיבוד. מחשבים סטנדרטיים מחזיקים ב-16 GB RAM, אחרים 8 או 32.
-
VRAM: זיכרון וירטואלי. קיים בשבבי GPU (כרטיסי מסך) חזקים. בעיקרון נועד למשימות גרפיות מיוחדות, כמו עריכת וידאו מקצועית או גיימינג, אבל בשנים האחרונות משמש גם להאצה משמעותית של הרצת מודלי AI בשל מהירות העיבוד הרבה שהוא מאפשר וגישה מהירה לזיכרון הוירטואלי. בדרך כלל לא קיים במחשבים סטנדרטיים.
(ישנם עוד מרכיבים חשובים מאוד, כמו רוחב פס ועוד, אבל זה פחות רלוונטי לעכשיו.)
בדרך כלל כשמריצים מודל על חומרה סטנדרטית (RAM בלבד) בפלאפונים ומחשבים, הגודל המומלץ של המודל צריך להיות כמחצית מסך ה-RAM הכולל, כדי להשאיר מספיק זיכרון לפעילות מערכת ההפעלה ותהליכי מערכת אחרים. לדוגמא, אם יש במחשב 16 RAM, הגודל המומלץ של המודל יהיה 7-8GB, אלא אם כן ישנן תוכנות כבדות שפתוחות במקביל להרצת המודל ותופסת מקום משלהן.
כמו כן, ככל שיש יותר RAM מעבר לסטנדרט, לדוגמא במחשבי פרימיום עם 32 RAM, מתפנה הרבה יותר מקום פנוי ב-RAM עבור הרצת המודל, ואפשר להריץ אפילו מודלים ששוקלים 24GB ויותר.

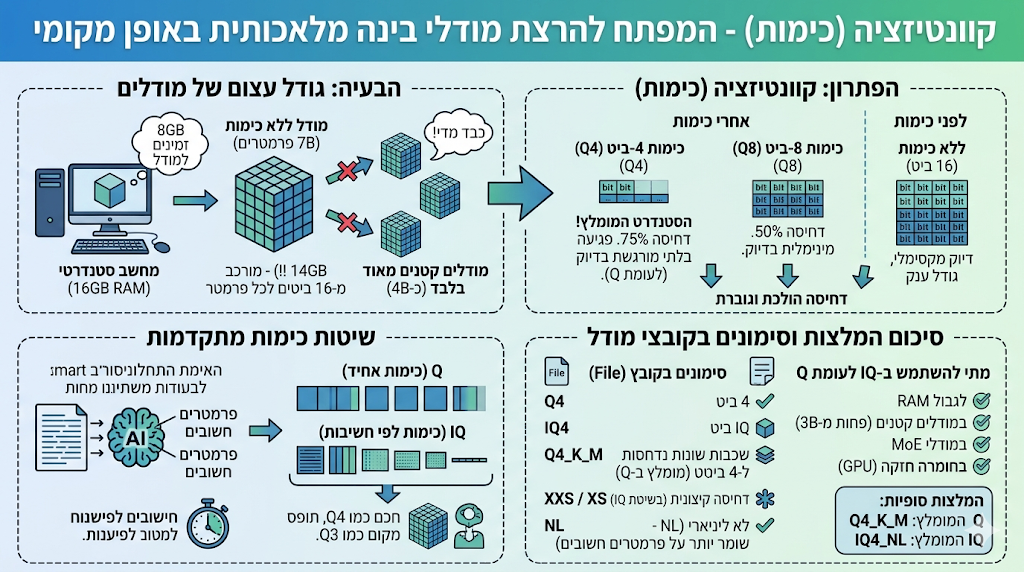
קוונטיזציה (כימות)
כמו שכתבתי בקטע הקודם, אם יש לי במחשב 16 RAM, מתפנה לי כ-8GB עבור הרצת מודל מקומי. הבעיה היא, שמודל AI ללא כימות שוקל בערך פי שניים ממספר הפרמטרים שלו, לדוגמא מודל של 7B שוקל בערך 14GB...
למתקדמים: פרמטר הוא בעצם מספר עשרוני (לדוגמא 0.12345678-). ללא כימות הוא מורכב מ-16 ביטים (סיביות).
כל בייט (בית) באחסון מכיל 8 ביטים (סיביות), ולעומת זאת כאמור כל פרמטר במודל מורכב מ-16 ביטים, כך שכל פרמטר מורכב משני בייטים.
אם נכפיל את הפרמטרים, אז מודל של 7B יהיה מורכב מ-14 מיליארד בייטים ששווים לבערך 14GB (ליתר דיוק קצת פחות, כי בשטח אחסון הכפולות הן של 1024 ולא 1000).זה משאיר לנו להשתמש רק במודלים קטנים מאוד, בדוגמא שלנו - 4B בערך...
בשביל זה נועד הכימות, או קוונטיזציה בלועזית: דחיסה של פרמטרי המודל.
חוקרי ה-AI גילו שעיגול של הספרות האחרונות שאחרי הנקודה בכל פרמטר, עד רמה מסוימת אינו פוגע משמעותית בדיוק של המודל, אבל כתוצאה מכך המודל הופך לקטן ומהיר יותר.
לדוגמא, כימות של 8 ביט, כלומר שכל פרמטר מורכב מ-8 ביטים במקום מ-16, חותך את גודל המודל ב-50% (יחס של 1:1 בין הפרמטרים לבייטים), תוך פגיעה מינימלית בדיוק.
כימות של 4 ביט, חותך את גודל המודל ב-75% (יחס של 1:0.5) בין הפרמטרים לבייטים), תוך פגיעה בלתי מורגשת לעין אנושית בדיוק.
הסטנדרט בהרצה מקומית הוא כימות של 4 ביט. כימות חזק יותר כבר פוגע משמעותית בדיוק של המודל (ראה בסקירת המודלים השונים בהמשך אודות מודלי Bonsai החדשניים בעלי כימות של 1 ביט - חיסכון של 93% בגודל המודל!!!).ככה שאם יש לנו 8GB פנויים להרצת המודל, נוכל להריץ עליהם אפילו מודלים של 13-14B בכימות של 4 ביט!
הכימות מוצג בשם קובץ המודל אחרי האות Q (קיצור של Quantization) - כימות של 8 ביט: Q8, כימות של 4 ביט: Q4 וכן הלאה.
בנוסף לעובדה שהירידה בדיוק המודלים היא מינורית, פותחה שיטת כימות חדשה שמצמצמת את הירידה בדיוק עוד יותר: IQ (Importance Quantization = כימות לפי חשיבות).
בשיטה הזאת, הכימות אינו אגרסיבי ואחיד לכלל הפרמטרים במודל, אלא האלגוריתם, באמצעות הרצה של המודל על טקסט ארוך ומגוון מזהה אילו פרמטרים "נדלקים" הכי הרבה - מה שאומר שהם קריטיים יותר לבינה של המודל, ואילו משניים, ואז שומר על דיוק גבוה בפרמטרים החשובים, ודוחס באגרסיביות (אפילו מתחת ל-2 ביט) את הפרמטרים הפחות חשובים.
התוצאה היא מודל חכם כמו Q4, אבל תופס שטח כמו Q3.
השיטה הזאת אמנם יוצרת מודל חכם וקטן יותר, אבל קצת איטית יותר, מכיוון שתהליך הסקה של מודל מכומת עם IQ דורש מעט יותר חישובים לפיענוח הפרמטרים הדחוסים.ישנם עוד סימונים פחות משמעותיים בכימות - האותיות באנגלית שאחרי רמת הכימות, לדוגמא Q4_K_M, שמייצגות את כמות השכבות של המודל שנדחסות ל-4 ביט, לעומת מספר שכבות קריטיות שנדחסות ל-6 ביט.
בשיטת ה-IQ נראה את הייצוג XXS / XS, כלומר דחיסה קיצונית של יותר שכבות, אבל המודל בכל זאת יישמור על השכל שלו בגלל ייחודיות שיטת ה-IQ. יש גם את הייצוג NL (Non Linear = לא ליניארי), כלומר האלגוריתם משתמש בגרף עקום כדי לקבוע אילו פרמטרים חשובים יותר ולא במדרגות קבועות, מה ששומר עוד יותר על הדיוק של המודל בפרמטרים החשובים.למעשה, הכימות המומלץ לשימוש הוא 4 ביט בשיטת Q, למעט במקרים הבאים:
- אם המודל שאנחנו רוצים להריץ הוא על גבול יכולת ה-RAM שלנו, נבחר בשיטת IQ כדי לחסוך כמה מאות MB ב-RAM.
- במודלים קטנים - פחות מ-3B, כל ביט קריטי, ושם חשובה שיטת ה-IQ כדי לשמור על הבינה של המודל.
- במודלי MoE (הסבר בהמשך), שיטת ה-IQ שומרת על פרמטרים חשובים כמו הנתב שמפעיל את הפרמטרים הרלוונטיים לכל טוקן בדיוק גבוה, ודוחסת פרמטרים פחות רלוונטיים.
- בחומרה חזקה עם GPU, שאז הפרש המהירות לא מורגש, נבחר בשיטת ה-IQ.
לסיכום, אם בוחרים בשיטת Q, מומלץ לבחור ב-Q4_K_M, ואם בוחרים בשיטת IQ מומלץ לבחור ב-IQ4_NL.
ארכיטקטורת המודל
ישנן 3 ארכיטקטורות מודלים עיקריות:
- צפוף (Dense): מודל רגיל שכל הפרמטרים שלו מופעלים עבור כל טוקן, כך שהמודל ממקסם את היכולות והידע שלו. לדוגמא: Gemma 4 31B.
- MoE (תערובת מומחים): מודל מיוחד שמכיל נתב פנימי שקובע אילו פרמטרים ("מומחים") חשובים עבור כל טוקן, ובמקום להפעיל את כל הפרמטרים לטוקן מפעיל רק חלק קטן מהם, מה שמאיץ משמעותית את ההסקה, ובעיקר מאפשר לתוכנת ההסקה להכניס את הפרמטרים הפעילים ל-VRAM הקטן להסקה במהירות עצומה ולהשאיר את שאר הפרמטרים ב-RAM, מוכנים לשליפה לטוקן הבא, אם כי האיכות פחותה ממודל צפוף. לדוגמא: Gemma 4 26B A4B.
- Effective (פרמטרים אפקטיביים): מודלי ה-E (כמו Gemma 4 E2B ו-E4B) מציגים שיטה חדשה של "הטמעה לכל שכבה" (Per-Layer Embeddings). במודל רגיל, המעבד מבצע כפל מטריצות כבד על כל הפרמטרים בכל שלב - פעולה שדורשת כוח עיבוד רב וזיכרון מהיר (VRAM או לפחות RAM). במודלי E, גוגל פיצלה את המודל לשניים: ליבת חישוב רזה - רק חלק קטן מהפרמטרים (למשל 2.3B מתוך 5.1B ב-E2B) משתתף בחישובים המתמטיים המורכבים, וטבלאות ידע מוטמעות - שאר הפרמטרים (2.8B) מאורגנים כטבלאות נתונים ענקיות שמוטמעות בכל שכבה של המודל.
במקום שהשכבה תחשב את המידע מחדש ב"מוח" שלה, היא פשוט מבצעת אחזור - שליפה מהירה של ערכים מוכנים מהטבלה שרלוונטיים רק לטוקן הספציפי שהיא עובדת עליו כרגע. מכיוון ששליפה מטבלה היא פעולה קלה לעיבוד לעומת חישוב מתמטי, המודל מפגין רמת חוכמה של מודל גדול בהרבה מבלי להאט את מהירות ההרצה. בנוסף, את הטבלאות הללו ניתן לאחסן על הדיסק (SSD) ולא חובה להעמיס אותן על ה-RAM, מה שמאפשר להריץ מודלים איכותיים גם על חומרה מוגבלת.
מודלי VL
מודלי VL (מולטי-מודאליים), הם מודלים שמסוגלים "לראות" תמונות ווידאו ולטפל בהם כקלט ולא רק בטקסט. זה מאפשר להם להשיב על שאלות חזותיות שונות וכדומה.
בפורמט GGUF (יוסבר בהמשך), מודלי ראיה מגיעים עם קובץ נוסף שנקרא mmproj (Multi-Modal Projector), שהוא רכיב שמתווך בין הראייה לבין ה"מוח" הטקסטואלי של המודל.
ישנם מודלי ראיה מיוחדים שאומנו במיוחד עבור משימות OCR (זיהוי טקסט מתמונות), שבהם חלק הראיה גדול מאוד, לעיתים אף יותר מהחלק הטקסטואלי של המודל, כדי להתאים לשימושים שעיקרם ויזואליים.פורמטי מודלים עיקריים
ישנם מספר פורמטים להרצת מודלים באופן מקומי ומהיר. הנפוצים שבהם:
- GGUF: הפורמט הנפוץ ביותר. נתמך במרבית תוכנות ההרצה המקומית. פותח ע"י יוצר llama.cpp. מכיל בקובץ אחד את כל חלקי המודל - המשקולות, הטוקנייזר, המטא-דאטה, תבנית הצ'אט וכו'. מסוגל לפצל את שכבות המודל בין ה-CPU וה-GPU, והוא הנוח והמתקדם ביותר לבדיקה ושימוש גמיש. מחזיק באקו-סיסטם ענק סביבו.
- MNN: פורמט שפותח ע"י אליבאבא, ונחשב לאחד המנועים המהירים ביותר להרצת מודלים על אנדרואיד ו-iOS, עם צריכת סוללה נמוכה מאוד וזמן טעינה מהיר.
- LiteRT: המיתוג מחדש של גוגל ל-TensorFlow Lite, המנוע הוותיק והיציב להרצת מודלי שפה ולמידת מכונה על מכשירי קצה. מותאם בצורה מושלמת לאנדרואיד, ונחשב לפורמט הסטנדרטי והיציב ביותר בתעשייה ליישומים מסחריים.
- MLX: פורמט למחקר והרצת מודלים שפותח על ידי חטיבת ה-AI של Apple. הוא תוכנן במיוחד עבור המעבדים מסדרת Apple Silicon. מתאים לארכיטקטורת הזיכרון המאוחד של מעבדי אפל.
אורך ההקשר (Context)
רבים טועים לחשוב שהדבר היחיד שמשפיע על ה-RAM הנדרש להרצת מודלים מקומיים הוא גודל המודל בלבד.
למעשה יש עוד דבר שמשפיע על הזיכרון לא פחות, ובהרצות מסחריות אף יותר מגודל המודל: מטמון ה-KV.
כדי שהמודל יזכור את מה שנאמר בתחילת השיחה, הוא צריך לשמור סיכום מתמטי של כל הטוקנים הקודמים שחושבו בזיכרון ה-RAM/VRAM. ככל שהשיחה מתארכת וחלון ההקשר ארוך יותר, הזיכרון הזה הולך ותופח.
אפילו במודלים קטנים, אורך הקשר של 32K יכול לתפוס כמה GB טובים בזיכרון, בנוסף למשקל המודל עצמו!
בדרך כלל ברירת המחדל בתוכנות הרצה מקומית היא אורך הקשר של 4096 טוקנים, מה שמצריך "רק" כמה מאות MB בזיכרון, אבל בהסקות מסחריות של מודלים מקומיים על שרתים גדולים, לדוגמא לקידוד מקצועי או לצרכים ארגוניים, אורך הקשר של מיליון טוקנים ידרוש כמה מאות GB בזיכרון!
כדי לחסוך בזיכרון, משתמשים בשיטות של דחיסה או חלוקת ההקשר בין ראשי המודל כמו GQA.
יש גם את Flash Attention, טכנולוגיה שמייעלת את הגישה לטוקני ההקשר האלו בזמן אמת באמצעות חישוב של חתיכות מידע בבת אחת במהירות עצומה בזיכרון המהיר שבתוך המעבד (SRAM) בלי לצאת החוצה ל-RAM בכל טוקן.
גוגל פרסמה לאחרונה שיטה חדשנית בשם TurboQuant, שבה במקום לכמת רק את משקולות המודל, מכמתים גם את טוקני ההקשר בצורה יעילה שלא פוגעת כמעט בדיוק, בכימות קיצוני שחוסך 75% עד 85% מהזיכרון, תוך כדי תנועה!
כרגע TurboQuant עדיין לא הוטמעה רשמית בתוכנות ההסקה המקומית הנפוצות, אבל כשזה יקרה זה יורגש גם עבור משתמשים פשוטים, אבל עבור משתמשים מקצועיים עם חומרת על זה יחסוך מאות GB RAM!RAG
גם המודל הכי חכם שיש, מוגבל למה שהוא למד בזמן האימון שלו. אם תשאלו אותו על קובץ PDF פרטי משלכם, או על חדשות שפורסמו אתמול, הוא פשוט לא יידע, או גרוע מכך - הוא יהזה וימציא תשובה שנשמעת הגיונית.
RAG (ייצור מוגבר באחזור) פותר את זה על ידי כך שהוא נותן למודל "ספרייה" חיצונית לעיון בזמן אמת.
בשלב הראשון המערכת מטמיעה את הטקסטים של המסמכים או מה שזה לא יהיה לערכים וקטוריים ושומרת אותם במסד נתונים בשם VectorDB (או אחרים).
כשהמשתמש שואל שאלה, המערכת לא שולחת אותה מיד למודל, אלא קודם כל מבצעת חיפוש סמנטי (לפי משמעות) במסד הנתונים הוקטורי, ושולפת ממנו את פסקאות הטקסט שהכי קרובות מבחינה סמנטית לטקסט השאלה של המשתמש.
לאחר מכן המערכת מגישה את השאלה מהמשתמש למודל, בתוספת הטקסט ששלפה ממסד הנתונים כחלק מההקשר, וכך המודל יכול להשיב בצורה יעילה שמבוססת על נתונים עדכניים ומאומתים, בלי להזות.
מה שמיוחד ב-RAG הוא שמכיון שהחיפוש הוא סמנטי, המודל יקבל גם פסקאות טקסט שמילות החיפוש לא מופיעות בהן במפורש, אלא רק המשמעות קשורה איכשהו. לדוגמא אם תשאלו על "שבת", המודל יקבל כהקשר גם טקסט בנושא ל"ט מלאכות.
MCP
MCP (ראשי תיבות של Model Context Protocol) הוא תקן פתוח שמאפשר לכל המודלים להתחבר לכלים ונתונים חיצוניים בצורה אחידה. הוא הנושא החם של 2026, ומי שבעצם אחראי לכל מהפכת סוכני ה-AI.
עד לא מזמן, כשהמשתמש רצה שהמודל יבצע עבורו פעולות מסוימות וישתמש בכלים, הא היה צריך לכתוב (או המודל עצמו) קוד מיוחד עבור כל משימה בנפרד. זה היה מסורבל, לא אמין ודרש התאמה לכל מודל.
ה-MCP הוא פרוטוקול סטנדרטי שמאפשר למודל להתחבר לכל שרת MCP חיצוני ולהשתמש בכלים שלו מיד, בלי שום הגדרות מיוחדות.
השיטה מבוססת על 2 חלקים: לקוח ה-MCP - תוכנת ההסקה שבה יושב המודל, ושרת ה-MCP - שרת מקומי בדרך כלל שמורכב מיחידה קטנה של קוד שיודעת לעשות פעולה ספציפית כמו קריאה מקבצים, חיפוש ברשת, גישה ליומן וכדומה.
ברגע שמחברים שרת MCP לתוכנה, המודל מבין מיד אילו כלים נתונים לרשותו ומתחיל להשתמש בהם כשצריך.
ככה, במקום לכתוב כלי ייעודי עבור כל משימה, פשוט מצביעים על כלי מתוך המאגר העצום הקיים ברשת בקובץ mcp.json, והתוכנה מורידה את הכלי ומטפלת בו ונותנת למודל פירוט קצר על כל כלי הכולל את שם הכלי, תיאור על מטרתו ויכולותיו, והסבר אילו פרמטרים הוא צריך.
לדוגמא המודל מקבל כלי קריאה מקבצים בשם read_file עם תיאור על יכולותיו והפרמטרים הנדרשים, וכשהוא מחליט לקרוא תוכן מתוך קובץ הוא מבצע קריאה לכלי:call: read_file(path="notes.txt")MCP זה מה שהופך את המודל לסוכן שיוצא מגבולות הצ'אט לפעולות בעולם האמיתי.
פרוטוקול ה-MCP פותח במקור ע"י חברת אנתרופיק עבור מודלי Claude, אבל הפך לתקן פתוח שכל תעשיית ה-AI אימצה, וכל מודל התומך בקריאה לכלים מאומן מראש על הפרוטוקול הזה.פיענוח ספקולטיבי
אחת הבעיות הגדולות בהרצת מודלי שפה גדולים היא ההשהיה, בשל העיבוד המקומי האיטי.
מודל גדול של 30B עובד ממש לאט כי הוא צריך להפעיל את כל המוח שלו על כל טוקן.
בשביל זה פותחה טכנולוגיית הפיענוח הספקולטיבי - 2 מודלים מאותה משפחה עם אותו אוצר מילים שרצים במקביל, אחד חכם וכבד - נניח Qwen 3.5 27B, והשני קטן, מהיר וקליל - Qwen 3.5 0.8B.
במקום שהמודל הגדול יחשוב על כל טוקן, המודל הקטן רץ קדימה במהירות ומנחש סדרה של טוקנים (למשל את 5 הטוקנים הבאים במשפט). הוא עושה זאת במהירות עצומה כי הוא קטן וקל משקל. המודל הגדול מקבל את כל 5 הטוקנים בבת אחת ובודק אותם במכה אחת (בפעולת חישוב מקבילית).
אם המודל הקטן צדק, הרווחנו 5 טוקנים בזמן של טוקן אחד!
אם הוא טעה בטוקן השלישי לדוגמא, המודל הגדול מתקן אותו וזורק את השאר, ומתחילים שוב מהנקודה הזו.
בטכנולוגיה הזו ניתן לקבל מהירות גבוהה פי 10 לעומת הרצה רגילה של המודל הגדול, ובמקביל האיכות נקבעת ב-100% ע"י המודל הגדול, כך שאין שום הבדל מבחינת התוצאה!
הנחיית מערכת
רבים נוטים להתעלם מהנחיית המערכת ופשוט מתחילים לשאול שאלות, אז מתלוננים שהמודל גרוע. אבל עבור מודלים מקומיים הנחיית מערכת היא הכלי החזק ביותר שלכם כדי לקבל תוצאות מקצועיות ולא "רובוטיות".
הנחיית המערכת קובעת את הזהות, המומחיות והחוקים שחלים על המודל לאורך כל השיחה.
לא מספיק לכתוב "אתה עוזר חכם", אלא צריך להגדיר למודל מיהו, מה תפקידו המדוייק, מה סגנון הכתיבה, מבנה הפלט, סביבת הריצה שלו, הכלים השונים שעומדים לרשותו ועוד.
כשכותבים למודל בהנחיית המערכת "אתה מומחה לכתיבת קוד Python", זה מכניס אותו למאגר הידע של Python שבתוכו.
ככל שמשקיעים יותר בהנחיית המערכת ונותנים בה למודל יותר מידע רלוונטי, התוצאות טובות יותר בעשרות אחוזים.
יש מאגר בגיטהאב שמרכז דליפות של הנחיות מערכת של מודלי העל כמו Claude ו-Gemini, ושם אפשר לראות שהנחיות המערכת שלהם הן יותר ספר רכב מאשר הנחיה...אפשרויות ההרצה
ישנן מספר רב של תוכנות ואפליקציות להרצת מודלי AI ללא אינטרנט, ונסקר את העיקרית שבהן.
כאמור בהתאם לחוקי הפורום לא אוכל לצערי לשתף קישורים להורדת התוכנות, ואם יהיה שינוי בחוקי הפורום כמובן שאעדכן את הפוסט עם קישורים לכל תוכנה.Windows:
- LM Studio:

התוכנה הנוחה ביותר להרצת מודלים, עם הגמישות הגדולה ביותר ותמיכה בטכנולוגית מתקדמות.- תומכת במודלים בפורמט GGUF, ובמחשבי אפל גם בפורמט MLX.
- יצירת שרת מקומי לשימוש בתוכנות אחרות, כלי שורת פקודה וסוכני AI שונים.
- תומך במודלי ראיה.
- תמיכה בפיענוח ספקולטיבי.
- תמיכה בקריאה לכלים.
- כוללת RAG.
- מבוססת על ליבת llama.cpp.
- הממשק הגמיש והנוח ביותר, עם שליטה בהגדרות רבות.
למדריך מפורט ומושקע של @חובבן-מקצועי האלוף על השימוש בתוכנה, היכנסו לכאן.
- Ollama:

הסטנדרט עבור הרצת מודלים בשורת הפקודה או כשרת רקע.
נועד למשתמשים שצריכים API מקומי יציב ופשוט, ולמשתמשים שמעדיפים ממשק מינימליסטי.
- Llama.cpp:

המנוע שמתחת למכסה המנוע. כמעט כל התוכנות והאפליקציות האחרות, כולל LM Studio ו-Ollama, מבוססות עליו.- פרוייקט קוד פתוח ב-C++, שנועד להריץ מודלים במינימום משאבים.
- גמישות מלאה ושליטה על כל פרמטר.
- המהירות הגבוהה ביותר בדרך כלל, מכיון שאין שכבות גרפיות מעל המנוע.
- דורש ידע בעבודה עם שורת הפקודה.
- תמיכה ראשונית בכל טכנולוגיה חדשה או מודל חדש מופיעה כאן לראשונה.
- Jan:

חלופה מודרנית וקלילה ל-LM Studio, עם דגש חזק על קוד פתוח ופרטיות.- ממשק נקי ופשוט, ידידותי למשתמשים מתחילים.
- כולל גרסה ניידת.
- RAG ותוספים.
Android:
- PocketPal AI:

האפליקציה היציבה והנוחה ביותר. מבוססת על Llama.cpp, ומתעדכנת כל כמה ימים בדרך כלל.- תמיכה במודלי GGUF.
- תמיכה במודלי ראיה, עם אפשרות לטעון את המודל ללא רכיב הראיה לביצועים מהירים יותר.
- תמיכה בשכפול צ'אטים.
- שליטה מלאה בפרמטרי ההסקה.
- בנצ'מרק למדידת ביצועי הסקה במכשירים שונים.
- Pals - מערכת ליצירת סוכנים במגוון תחומים.
- כוללת עברית - תורגם על ידי כתרומה לפרוייקט.
- Google AI Edge Gallery:

האפליקציה להרצת מודלי AI מבית Google. המתאימה ביותר לביצועי רקע וחיסכון בסוללה. משמשת בעיקרון ככלי הניסוי של גוגל למודלי Gemma הקטנים, בעיקר E2B ו-E4B.- מבוססת על מנוע LiteRT שפותח ע"י Google.
- הגרסאות האחרונות כוללות פיצ'רים מעניינים המבוססים על מודלי Gemma 4, כמו המיומנויות - לדוגמא קריאה מויקיפדיה, הצגת מיקום במפות גוגל ועוד.
- תומכת בקלט תמונה ואודיו עבור מודלים נתמכים.
- תרגום דיבור.
- תמלול.
- מעבדת הנחיות - סביבת עבודה ייעודית לבדיקת הנחיות שונות.
- פעולות מובייל - ביצוע פעולות במכשיר באמצעות מודל קריאה לכלים זעיר.
- משחק גננות זעיר המופעל באמצעות מודל קריאה לכלים זעיר.
- החיסרון העיקרי: לא שומרת היסטוריית שיחות.
- MNN Chat:

אפליקציה להרצת מודלים בפורמט MNN שפותחה גם היא כמו הפורמט ע"י אליבאבא. נכון להיום, משמשת כפיתרון המהיר ביותר להרצת מודלים באנדרואיד.- חושפת שרת מקומי לשימוש מאפליקציות אחרות ואפליקציות אוטומציה כמו מאקרודרואיד וטאסקר.
- תומכת במודלי Qwen Omni - מודלים התומכים בקלט טקסט, תמונה ואודיו ופלט טקסט ואודיו.
- תמיכה במודל Stable Diffusion ליצירת תמונות מקומית.
- חסרונות עיקריים - חוסר יציבות ואי-אמינות, תמיכה מאוחרת במודלים חדשים, תמיכה רק במודלים המעטים שהומרו לפורמט המתאים.
ישנן עוד אפליקציות רבות המבוססות על Llama.cpp, הטובות שבהן:
- Off Grid
- InferrLM
- LLM Hub
בעז"ה אפרט עליהן בעדכונים הבאים למדריך.
פיתרון בעיות בהרצה
כאן ירוכזו בעיות בהרצת מודלי AI מקומיים ופתרונן.
בעיה בטעינת מודלי Gemma 4, Qwen 3.5 ומודלים נוספים ב-LM Studio
פיתרון הבעיה בספויילר:
הפיתרון: מדובר בשגיאה בטעינת מודלים הכוללים יכולות ראיה. התוכנה לא מזהה את קובץ ה-mmproj שאחראי על תיווך הראיה למוח הטקסטואלי של המודל, אם הוא נמצא בנתיב המכיל אותיות עבריות, ולכן מתרחשת שגיאה אם שם המשתמש במחשב כולל אותיות עבריות וטעינת המודלים נכשלת.
הפיתרון הוא כמובן לוודא קודם כל שהגרסה המותקנת של LM Studio היא העדכנית ביותר כדי לוודא תמיכה במודלים, ולאחר מכן יש להעביר את תיקיית "models" מהנתיב הזה:C:\Users\<שם_המשתמש_שלך>\.cache\lm-studio\modelsאל תיקיית השורש של הכונן - לדוגמא C, ואז להיכנס להגדרות ב-LM Studio, בכרטיסיית General, לגלול למטה עד Models Directory, ללחוץ על 3 הנקודות בצד ולבחור ב-Change ואז לבחור בנתיב החדש שלנו -
C:\modelsכעת המודלים אמורים להיטען בהצלחה, כולל רכיב הראיה!
איך לאפשר\להשבית מצב חשיבה ב-Gemma 4 ב-LM Studio?
ראה מדריך מפורט לניהול מצב החשיבה כאן.
משפחות המודלים וסקירה מקיפה (מתעדכן!)
להלן יפורטו משפחות המודלים העיקריות, עם פירוט על המודלים האחרונים בכל סדרה ויכולותיהם, קטנים ובינוניים - עד גודל של 35B.
אם לחברה כלשהיא יש מודלים ישנים יותר אך עדיין רלוונטיים, לדוגמא בשל כך שאין להם תחליף מאותה משפחה באותו טווח גודל, הבאתי גם אותם.
Gemma

משפחת המודלים הפתוחים של גוגל, המבוססת על הטכנולוגיה של מודלי Gemini.
מודלי Gemma בכללותם מצטיינים בשפות רבות, כולל עברית, וידועים ביציבותם וב"מערביות" שלהם, ובכך שהם מודלים "צפויים" שאפשר לסמוך עליהם לשימוש אמיתי. המודלים החדשים במשפחה נחשבים כיום למודלים החזקים ביותר כמעט בכל תחום, למעט בתחום הקידוד.
המודלים העדכניים של החברה:- Gemma 4 31B: המודל החכם ביותר במשפחה ובעולם המודלים הפתוחים בטווח הגודל הבינוני. מודל צפוף. ביצועים דומים למודלי העל מדור קודם. בעל יכולות ראיה וחשיבה. תומך בעברית.
- Gemma 4 26B A4B: מודל MoE. מודל חכם אך מהיר בשל כך שרק 4B פרמטרים מופעלים על כל טוקן. בעל יכולות ראיה וחשיבה. תומך בעברית.
- Gemma 4 E4B: מודל מסוג Effective, עם סה"כ 5.1B פרמטרים. נועד לפעול על מחשבים סטנדרטיים. תומך בקלט תמונה ואודיו. בעל יכולות חשיבה. תומך בעברית.
- Gemma 4 E2B: מודל מסוג Effective, עם סה"כ 8B פרמטרים. נועד לפעול על סמארטפונים סטנדרטיים. תומך בקלט תמונה ואודיו. בעל יכולות חשיבה. תומך בעברית.
- Gemma 3 12B: מודל צפוף, אמנם מהדור הקודם, אבל עדיין מהחזקים בטווח הגודל שלו. בעל יכולות ראיה. תומך בעברית.
- Gemma 3 1B: מודל קטן במיוחד מדור קודם, שנועד לפעול על חומרה חלשה במיוחד, למגוון משימות הדורשות בעיקר מהירות ופחות ידע.
- Gemma 3 270M: מודל זעיר מדור קודם, מהחזקים בגודלו, שנועד בעיקר לכוונון עדין למשימות הדורשות תגובה במהירות שיא.
- TranslateGemma 4B\12B: מודלי תרגום רב לשוניים, המבוססים על מודלים מסדרת Gemma 3. בעלי ביצועי תרגום מהטובים בעולם. תומך בתרגום ל\מעברית.
- FunctionGemma 270M: מודל זעיר המבוסס על המודל הזעיר מסדרת Gemma 3, שכוונן במיוחד לקריאה לכלים, ונועד לכוונון עדין להתאמה ספציפית למשימות קריאה לכלים.
Qwen

משפחת המודלים של חברת Qwen מבית אליבאבא הסינית. פורצי דרך בתחום המודלים הפתוחים. המודלים ממשפחת Qwen נחשבים למודלים מהטובים ביותר בכל תחום, והטובים ביותר בתחום הקידוד. כל המודלים מהסדרה האחרונה - Qwen 3.5 אומנו מראש באופן טבעי על תמיכה בקלט תמונה.- Qwen 3.5 35B A3B: מודל MoE. מהטובים לגודלו, מתאים במיוחד למנוע עבור סוכני AI מקומיים בשל האיזון בין יכולות גבוהות לבין מהירות הסקה גבוהה. בעל יכולות ראיה וחשיבה. תומך בעברית.
- Qwen 3.5 27B: מודל צפוף. הטוב ביותר לקידוד מבין המודלים הפתוחים בטווח הגודל הבינוני. בעל יכולות ראיה וחשיבה. תומך בעברית.
- Qwen 3.5 9B: מודל צפוף. הטוב ביותר לגודלו. נחשב למודל הקטן ביותר המסוגל להחזיק לבדו מערכת סוכני קידוד. בעל יכולות ראיה וחשיבה. תמיכה חלקית בעברית.
- Qwen 3.5 4B: מודל קטן, המחזיק בביצועי קידוד מרשימים לגודלו, המתקרבים לביצועי GPT 4. בעל יכולות ראיה וחשיבה.
- Qwen 3.5 2B: מודל קטן במיוחד, המתאים לביצוע מגוון משימות הדורשות מהירות ויעילות. מחזיק ביכולות מרשימות ביחס לגודלו. מתאים כמודל OCR קטן ומהיר. בעל יכולות ראיה וחשיבה.
- Qwen 3.5 0.8B: מודל זעיר במיוחד, המתאים לביצוע משימות פשוטות במהירות שיא, וניתן לכוונון עדין למשימות ספציפיות. מחזיק ביכולות מרשימות ביחס לגודלו. בעל יכולות ראיה וחשיבה.
- Qwen3 Coder 30B A3B Instruct: מודל MoE מיוחד לקידוד המבוסס על המודל מהדור הקודם. בעל יכולות קידוד מרשימות. תומך בעברית.
סדרת Qwen 3.5 הביאה איתה גל של כוונונים עדינים למודלי הסדרה, המשפרים את ביצועי המודלים בשלל תחומים. בדרך כלל לא מומלץ להשתמש במודלים מכווננים אלא להישאר עם המודל המקורי, אך בסדרה הזו ישנם 2 מודלים שמומלצים אף יותר מהמודל המקורי:
- Qwopus 3.5 4B\9B\27B (או השם הקודם - Qwen 3.5 Claude 4.6 Opus Reasoning Distilled עבור גרסאות 0.8B\2B\35B A3B): אימון של מודלי Qwen 3.5 על עקבות מחשבה של Claude 4.6 Opus. האימון המיוחד משפר ומקצר דרמטית את אורך שרשרת החשיבה של המודלים, תוך שמירה על איכות המודלים ואף ביצועים טובים יותר.
- OmniCoder 9B: - כוונון עדין מיוחד של מודל ה-9B של Qwen 3.5 המשפר באופן משמעותי את ביצועי הקידוד של המודל.
GPT-OSS

משפחת המודלים GPT-OSS של חברת OpenAI, ששחררה אותם לאחר לחץ מקהילת המודלים הפתוחים, משקיעים ועוד. נחשבים למודלים בעלי צנזורה חזקה במיוחד, שאף עיכבה את שחרור המודלים פעם אחר פעם כי "לא הייתה מספיק בטוחה"... המודלים נחשבים למודלים חכמים מאוד ואמינים במיוחד.- GPT-OSS 20B: מודל MoE עם 3.6B פרמטרים פעילים. מהטובים ביותר בגזרת המודלים הבינוניים לקידוד ולכל מטרה. בעל יכולות חשיבה. תומך בעברית.
DictaLM

משפחת המודלים מבית חברת דיקטה הישראלית, המתמחים בשפה העברית באופן מיוחד.- DictaLM 3.0 24B Instruct\Thinking: מודל הדגל של החברה, המבוסס על Mistral Small 3.1 24B. מגיע בשני גרסאות - חשיבה ותגובה מיידית, להתאמה לכלל מקרי השימוש. מציג ביצועים מרשימים בעברית.
- DictaLM 3.0 12B Instruct\Thinking: מודל הביניים של החברה, המבוסס על NVIDIA Nemotron Nano 12B v2. גם הוא מגיע בשני גרסאות - חשיבה ותגובה מיידית. מציג ביצועים מרשימים בעברית ביחס לגודלו.
- DictaLM 3.0 1.7B Instruct\Thinking: מודל קטן במיוחד המותאם לריצה על מכשירים עם חומרה חלשה. מבוסס על Qwen3 1.7B. בעל ביצועים מפתיעים בעברית, ונחשב למודל הקטן ביותר המסוגל לשוחח בעברית תקינה לחלוטין, והחכם ביותר בעברית בקטגוריית הגודל שלו. גם הוא מגיע בגרסאות חשיבה ותגובה מיידית.
Aya

משפחת המודלים מבית מעבדות Cohere. מתמקדת ברב-לשוניות.- Tiny Aya 3.35B: סדרת מודלים קטנים המתאימים להרצה על חומרה חלשה, ומתאימים למשימות במגוון ענק של שפות. תומך בעברית. המודל המתאים לשימוש בישראל מתוך הסדרה הוא Tiny Aya Global.
- Aya Expanse 8B\32B: מודלים שמטרתם להרחיב את הבינה המלאכותית לשפות נוספות, ומשיגים ביצועים מרשימים בשפות שונות. די מיושנים כיום, אם כי הביצועים בשפות אחרות נדירות בגדלים כאלו. תומכים בעברית.
LFM

משפחת המודלים מבית LiquidAI היפנית. המודלים במשפחה נחשבים חריגים בשל כך שאינם מבוססים על ארכיטקטורת ה-Transformer הנפוצה, אלא על ארכיטקטורה "נוזלית", שמאיצה את ביצועי ההסקה על מכשירים חלשים. נחשבים למודלים שוברי סטיגמות בעניין יחס גודל-איכות, וככל שהמודל קטן יותר כך איכותו מפתיעה יותר ביחס לגודלו.- LFM 2 24B A2B: מודל MoE. המודל הגדול ביותר במשפחה, אך רץ במהירות גבוהה במיוחד בשל העובדה שרק 2B מהפרמטרים פעילים עבור כל טוקן. בעל יעילות קיצונית לריצה מהירה על מחשבים עם RAM מספק.
- LFM 2 8B A1B: מודל MoE. מתאים להרצה על מחשבים סטנדרטיים, במהירות גבוהה מאוד בשל העובדה שרק 1B מהפרמטרים פעילים עבור כל טוקן.
- LFM 2 2.6B: המודל הצפוף הגדול ביותר במשפחה. בעל איכות מפתיעה וידע עולם רב, בניגוד למודלים אחרים בגודלו. המודל עובר במדדים אף מודלים הגדולים ממנו פי כמה וכמה. מהיר מאוד בשל הארכיטקטורה ה"נוזלית" המיוחדת שלו. קיימת גרסת Exp ניסיונית שאף מאיצה עוד יותר את ההסקה.
- LFM 2 VL 3B: מודל ראיה המבוסס על מודל ה-2.6B, המצטיין ביכולות ראיה גבוהות במיוחד ביחס לגודלו, ובמהירות גבוהה במיוחד.
- LFM 2.5 1.2B Instruct\Thinking: מודל בעל איכות גבוהה ויכולת היגיון מפתיעה. מהיר מאוד גם ביחס לגודלו. נחשב למודל הטוב ביותר בפער סביב טווח הגודל של 1B. מגיע בשני גרסאות - חשיבה ותגובה מיידית, כשגרסת החשיבה מגיעה לביצועי היגיון גבוהים בדומה למודלים גדולים פי כמה.
- LFM 2.5 VL 1.6B: מודל ראיה המבוסס על מודל ה-1.2B, המצטיין ביכולות ראיה גבוהות במהירות עצומה.
- LFM 2 700M: מודל קטן ומהיר במיוחד, המותאם למשימות הדורשות ביצועים איכותיים ומהירים. מפתיע ביותר ביחס לגודלו.
- LFM 2.5 350M: המודל הקטן ביותר במשפחה, אך בעל הביצועים המפתיעים ביותר ביחס לגודלו. רץ במהירות שיא על כל חומרה, ומתאים למגוון רב של משימות.
- LFM 2.5 VL 450M: מודל ראיה המבוסס על מודל ה-350M, המצטיין ביכולות ראיה מפתיעות ביחס לגודלו במהירות שיא.
Llama

משפחת המודלים המיתולוגית מבית Meta, שהחלה את מהפכת ה-AI המקומי ב-2023 כשהודלף מודל ה-Llama הראשון, שלטה בתחום ללא עוררין למשך תקופה ארוכה, עד שהגיעה לקיצה ההיסטורי עם השקת מודלי Llama 4 המאכזבים. למרות זאת, מודלי המשפחה עדיין נחשבים לסטנדרט בתחומים רבים, ומהנוחים ביותר לעיצוב והתאמה אישית, ועדיין מככבים בראש רשימת ההורדות ב-Hugging Face. המודלים בסדרת Llama 4 גדולים יחסית ולכן לא הובאו כאן.- Llama 3.2 11B Vision Instruct: מודל מתקדם מדור קודם. בעל יכולות ראיה.
- Llama 3.2 3B Instruct: מודל קטן מדור קודם, המתאים למשימות רבות הדורשות מהירות גבוהה על חומרה חלשה.
- Llama 3.2 1B Instruct: מודל קטן במיוחד מדור קודם, אך עדיין אחד החכמים בטווח הגודל הזה. מתאים למשימות רבות הדורשות הרצה במהירות גבוהה במיוחד.
- Llama 3.1 8B Instruct: אמנם מודל יחסית ישן, אבל עדיין אחד המודלים שהורדו הכי הרבה פעמים מ-Hugging Face. נוח לשימוש והתאמה אישית.
Jamba

משפחת המודלים מבית AI21Labs הישראלית. המודלים מורכבים מארכיטקטורה היברידית המשלבת גם שכבות Transformer וגם שכבות Mamba (SSM).- AI21 Jamba Reasoning 3B: מודל קטן וחכם, עם יכולות חשיבה מתקדמות. בשל כך שרוב השכבות הן שכבות Mamba, ההסקה מהירה ברמה קיצונית. בעל יכולות היגיון חזקות. תומך בעברית.
- AI21 Jamba2 3B: הגרסה הקטנה בסדרה החדשה של המשפחה. לא כולל יכולות חשיבה, אך עדיין מציג תוצאות דומות למודל הקודם. מהירות גבוהה במיוחד. יכולות היגיון מפתיעות. תומך בעברית.
Phi

סדרת המודלים החכמים מבית מיקרוסופט. אומנו על מערכי נתונים מסוננים בקפידה, כמו ספרי לימוד ומידע סינטטי איכותי, ומהווים דוגמא לחשיבות איכות הנתונים על פני הכמות. מעולים לקידוד, מתמטיקה, היגיון ישר וידע עולם.- Phi-4: מודל 14B פרמטרים, הגדול ביותר בסדרה. מעולה לקידוד ומשימות היגיון מורכבות. תומך בעברית.
- Phi 4 Reasoning: מודל 14B פרמטרים בעל יכולות חשיבה מתקדמות, המבוסס על המודל הקודם. תומך בעברית.
- Phi 4 Reasoning Plus: גרסה משופרת של Phi 4 Reasoning שעברה למידת חיזוק. מספקת תשובות מדויקות ואיכותיות יותר, אך חושבת הרבה יותר, ולכן המודל מתאים למקרי שימוש המעדיפים איכות על פני מהירות. תומך בעברית.
- Phi 4 Multimodal Instruct: מודל מולטי מודאלי של 5.6B פרמטרים התומך בקלט טקסט, תמונה ואודיו. תומך בעברית.
- Phi 4 Mini Instruct: מודל קטן בעל 3.8B פרמטרים. מעולה למשימות הדורשות היגיון ישר וכסייען קידוד מהיר במיוחד. תומך בעברית.
- Phi 4 Mini Reasoning: מודל 3.8B פרמטרים בעל יכולות חשיבה מתקדמות, המבוסס על המודל הקודם. תומך בעברית.
- Phi 4 Mini Flash Reasoning: גרסה מהירה עד פי 10 מהמודל הקודם, תוך שמירה על אותה איכות, ע"י שימוש בארכיטקטורת SambaY המשלבת שכבות Mamba וטכנולוגיות נוספות, לעומת המודל הרגיל המבוסס על טרנספורמר קלאסי.
DeepSeek

משפחת המודלים הפתוחים של DeepSeek הסינית. המודלים הרלונטיים לכאן הם מודלים שזוקקו מהמודל הגדול של החברה - DeepSeek R1 685B. מודלים המתייחדים ביכולות חשיבה עמוקה וביצועים גבוהים תוך שימוש בחומרה צרכנית.- DeepSeek R1 Distill Qwen 32B: מודל חשיבה גדול המציג ביצועים מרשימים במדדים שונים. מבוסס על המודל המקביל מסדרת Qwen 2.5, שזוקק ממודל DeepSeek R1 הגדול. הכי קרוב לביצועי מודל המקור, ונחשב ספינת הדגל של המשפחה להרצה ביתית. תומך בעברית.
- DeepSeek R1 Distill Qwen 14B: מבוסס על המודל המקביל מסדרת Qwen 2.5. האיזון המושלם. חזק משמעותית בחשיבה מעמיקה, קידוד ומתמטיקה מגרסאות ה-8B.
- DeepSeek R1 Distill Llama 8B: מבוסס על המודל המקביל מסדרת Llama 3. בחירה אידיאלית למי שמעדיף את הסגנון ה"שיחתי" של מטא, אך זקוק לחשיבה עמוקה ולוגיקה משופרת.
- DeepSeek R1 Distill Qwen 7B: מבוסס על המודל המקביל מסדרת Qwen 2.5, עם יכולות חשיבה מעמיקה.
- DeepSeek R1 Distill Qwen 1.5B: מבוסס על המודל המקביל מסדרת Qwen 2.5. מותאם למשימות הדורשות חשיבה עמוקה על חומרה חלשה במיוחד.
- DeepSeek R1 0528 Qwen3 8B: הזיקוק של הגרסה המשופרת 0528 של מודל DeepSeek R1 הגדול. מבוסס על המודל המקביל מסדרת Qwen 3.
- DeepSeek OCR 2: מודל OCR מתקדם בעל 3B פרמטרים. תומך בעברית.
EuroLLM

משפחת מודלים רב-לשונית של חברת UTTER האירופית, הממומנת ע"י האיחוד האירופי ופותחה ע"י האוניברסיטאות היוקרתיות ביותר של אירופה. מטרת החברה הייתה לאמן מודלים בעלי יכולות מתקדמות בכל שפות האיחוד האירופי ושפות נפוצות אחרות.- EuroLLM 22B Instruct 2512: המודל הגדול במשפחה. בעל יכולות חזקות מאוד בכל השפות הרבות הנתמכות.
- EuroLLM 9B Instruct 2512: האיזון המשלם למהירות ויכולות לוגיות מורכבות. בעל יכולות היגיון חזקות מאוד גם לשפות פחות נפוצות.
- EuroMoE 2.6B A0.6B Instruct 2512: מודל MoE עם 0.6B פרמטרים פעילים בלבד עבור כל טוקן. מהיר מאוד, וחזק ביכולות רב-לשוניות. מאפשר גם לבעלי חומרה חלשה לחקור מודלי MoE, ונחשב למודל ה-MoE הרשמי הקטן ביותר. מתאים למשימות תרגום מהירות בין שפות רבות.
- EuroLLM 1.7B Instruct: מודל קטן ומהיר, בעל יכולות רב לשוניות חזקות. די מיושן אך עדיין בעל יכולות בלעדיות בתחומים מסויימים בשפות פחות נפוצות.
GLM

משפחת המודלים של חברת Z.ai הסינית. כיום החברה עברה להתמקד במודלי על עוצמתיים המתחרים במודלים המערביים הגדולים, כדוגמת GLM 5.1 שעוקף במדדי הביצועים את רוב מודלי העל המערביים, ופחות במודלים בינוניים וכמעט שלא מתעסקת במודלים קטנים. בכל זאת, המודלים הקטנים והבינוניים שכן שוחררו על ידי החברה עדיין ניצבים בחזית הביצועים המקומיים.- GLM 4.7 Flash: מודל MoE של 30B A3B (3B פרמטרים פעילים עבור כל טוקן). המודל הבינוני הטוב ביותר של החברה עד כה. בעל יכולות חשיבה עמוקה מתקדמות, ועוקף במדדי הביצועים מודלים הגדולים ממנו פי עשרה ויותר, ובמקביל מהיר במיוחד בשל ארכיטקטורת ה-MoE החדשנית.
- GLM 4.6V Flash: מודל 9B פרמטרים בעל יכולות ראיה מתקדמות, עם חשיבה מעמיקה. אחד ממודלי הראיה החזקים ביותר, ומתאים למשימות הדורשות שילוב של יכולות ראיה אמינות והיגיון ישר.
- GLM Edge 4B Chat: מודל קטן שנועד לרוץ על חומרת קצה. די מיושן אך בעל יכולות חזקות מאוד ומתאים למשימות הדורשת אמינות ויציבות במהירות גבוהה.
- GLM Edge V 5B: מודל ראיה המבוסס על המודל הקודם.
- GLM Edge 1.5B Chat: מודל קטן במיוחד להרצה על חומרת קצה חלשה. אמנם די מיושן, אבל עדיין בעל יכולות מרשימות יחסית לגודלו.
- GLM Edge V 2B: מודל ראיה המבוסס על המודל הקודם.
Falcon

משפחת המודלים מבית חברת TII (Technology Innovation Institute) האמירתית, הממומנת ע"י הממשלה האמירתית. במשפחה ישנם גם מודלים קטנים מאוד המתאימים לחומרה חלשה במיוחד.- Falcon H1 34B Instruct: ספינת הדגל של המשפחה. מודל חזק ועוצמתי בעל יכולות היגיון ישר ומתמטיקה חזקות.
- Falcon H1 7B Instruct: האיזון המושלם לביצועים איכותיים במהירות גבוהה.
- Falcon H1R 7B: גרסת חשיבה עמוקה של המודל המקורי. מתאימה למקרי שימוש בדורשים חשיבה חזקה ומהירות.
- Falcon H1 3B Instruct: מודל קטן אך חזק מאוד יחסית לגודלו, לביצועים מהירים במיוחד.
- Falcon H1 1.5B Instruct: מודל קטן מאוד אך בעל יכולות מרשימות, למשימות הדורשות מהירות גבוהה.
- Falcon H1 1.5B Deep Instruct: גרסה עמוקה יותר של המודל הקודם, עם ביצועים מעט איטיים יותר אך איכותיים בהרבה, למקרי שימוש הדורשים איכות גבוהה יותר ופחות מהירות.
- Falcon H1 0.5B Instruct: מודל קטן במיוחד אך חזק מאוד, לביצועים מהירים במיוחד אך איכותיים.
- Falcon H1 Tiny R 0.6B: מודל חשיבה מעמיקה המותאם לחומרה חלשה במיוחד. בעל יכולות היגיון חזקות מאוד יחסית לגודלו.
- Falcon H1 Tiny 90M Instruct: מודל זעיר במיוחד המסוגל לרוץ אפילו על חומרה חלשה ביותר, הצורך רק כ-55MB זיכרון RAM בכימות 4 ביט. בעל יכולות מרשימות מאוד ביחס לגודלו. נחשב למודל הקטן ביותר המפיק פלט איכותי וקוהרנטי.
- Falcon H1 Tiny R 90M: מודל חשיבה מעמיקה זעיר במיוחד לחומרה חלשה. נועד לאפשר יכולות חשיבה מעמיקה וקוהרנטית גם על חומרה חלשה באופן קיצוני. נחשב למודל החשיבה הקטן ביותר המפיק פלט איכותי וקוהרנטי.
- Falcon H1 Tiny Coder 90M: מודל קידוד זעיר לחומרה חלשה, המבוסס על המודל המקורי.
- Falcon H1 Tiny Tool Calling 90M: מודל קריאה לכלים זעיר לחומרה חלשה, המבוסס על המודל המקורי.
- Falcon OCR: מודל OCR של 300M פרמטרים. דוחף את גבולות ה-OCR על חומרה חלשה במיוחד.
על משפחות המודלים הבאות אפרט בעדכונים הבאים למדריך:
Granite

Exaone

Mistral

SmolLM

Nanbeige4

VibeThinker

Ernie

Maincoder

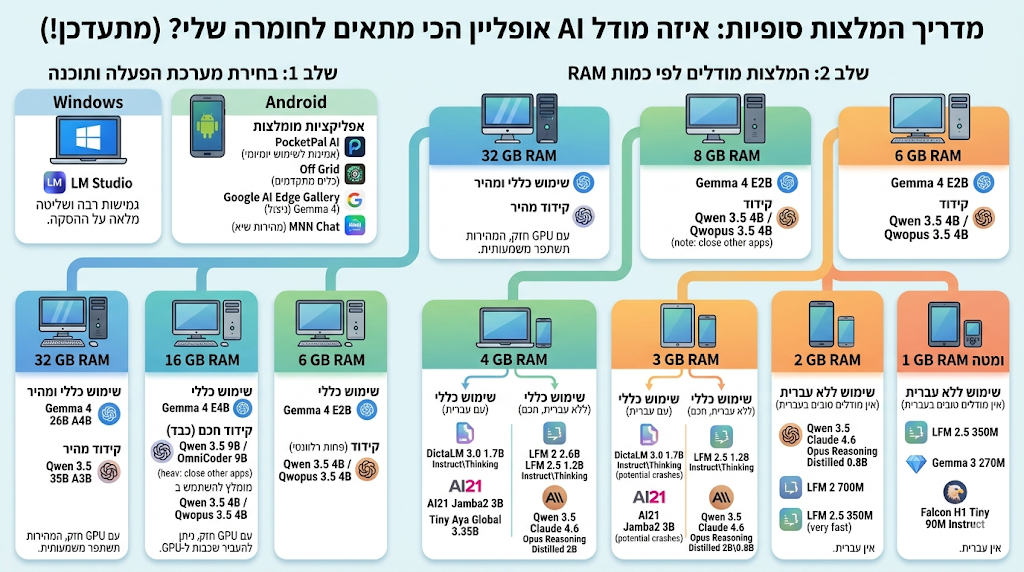
אז תכל'ס, איזה מודל הכי מתאים להריץ על החומרה שלי? (מתעדכן!)
תוכנת הסקה
עבור מחשבי Windows, התוכנה המומלצת כיום להרצת מודלים מקומיים היא LM Studio, בשל גמישותה הרבה והשליטה המלאה שהיא מאפשרת על תהליך ההסקה. ניתן להיעזר כאמור במדריך של @חובבן-מקצועי להרצת מודלים בתוכנה.
עבור מכשירי Android, האפליקציות המומלצות הן PocketPal AI עבור אמינות ויציבות לשימוש יומיומי, Off Grid לשימוש מתקדם בכלים וכדומה, Google AI Edge Gallery עבור ניצול מלא של יכולות Gemma 4 וסקירת התפתחות ה-AI, ו-MNN Chat להשגת ביצועי הסקה במהירות שיא.
מודל מומלץ
עבור חומרה עם 32 RAM: לשימוש כללי ומהיר המודל המומלץ הוא Gemma 4 26B A4B, ולקידוד מהיר Qwen 3.5 35B A3B. אם קיים GPU חזק, המהירות תשתפר ללא היכר.
עבור חומרה עם 16 RAM: לצרכי קידוד חכמים - בעיקרון המודל המומלץ הוא Qwen 3.5 9B או הגרסה המכווננת שלו OmniCoder 9B, אבל מדובר במודלים יחסית כבדים לחומרה כזאת שמצריכים סגירה של שאר התוכנות, ולכן מומלץ להשתמש לקידוד ב-Qwen 3.5 4B או בגרסה המכווננת שלו Qwopus 3.5 4B. לשימוש כללי - Gemma 4 E4B. אם קיים GPU חזק, ניתן להעביר כמה שיותר שכבות ל-GPU לעיבוד מהיר בהרבה.
עבור חומרה עם 8 RAM: עבור קידוד מומלץ להשתמש ב-Qwen 3.5 4B או בגרסה המכווננת שלו Qwopus 3.5 4B. לשימוש כללי - Gemma 4 E2B.
עבור חומרה עם 6 RAM: לשימוש כללי מומלץ להשתמש ב-Gemma 4 E2B. שימוש לקידוד פחות רלוונטי בדרך כלל בחומרה כזאת, אבל ניתן להסתייע ב-Qwen 3.5 4B או בגרסה המכווננת שלו Qwopus 3.5 4B.
עבור חומרה עם 4 RAM: לשימוש כללי בעברית מומלץ להשתמש ב-DictaLM 3.0 1.7B Instruct\Thinking, או ב-AI21 Jamba2 3B, או ב-Tiny Aya Global 3.35B. לשימוש חכם יותר אך ללא עברית מומלץ להשתמש ב-LFM 2 2.6B או LFM 2.5 1.2B Instruct\Thinking, או ב-Qwen 3.5 Claude 4.6 Opus Reasoning Distilled 2B (הכוונון של המודל המקורי, מונע לולאות חשיבה אינסופית בגודל הזה).
עבור חומרה עם 3 RAM: לשימוש כללי בעברית מומלץ להשתמש ב-DictaLM 3.0 1.7B Instruct\Thinking. ניתן לנסות להשתמש ב-AI21 Jamba2 3B - מודל מהיר במיוחד, אך ייתכנו קריסות אם ה-RAM צפוף. לשימוש חכם יותר אך ללא עברית מומלץ להשתמש ב-LFM 2.5 1.2B Instruct\Thinking, או ב-Qwen 3.5 Claude 4.6 Opus Reasoning Distilled 2B\0.8B (הכוונון של המודל המקורי, מונע לולאות חשיבה אינסופית בגודל הזה).
עבור חומרה עם 2 RAM: אין כיום מודלים טובים בעברית לחומרה זו. לשימוש ללא עברית מומלץ להשתמש ב-Qwen 3.5 Claude 4.6 Opus Reasoning Distilled 0.8B (הכוונון של המודל המקורי, מונע לולאות חשיבה אינסופית בגודל הזה), או ב-LFM 2 700M, או ב-LFM 2.5 350M לשימוש מהיר במיוחד.
עבור חומרה עם 1 RAM ומטה: אין כיום מודלים טובים בעברית לחומרה זו. לשימוש ללא עברית מומלץ להשתמש ב-LFM 2.5 350M, או ב-Gemma 3 270M, או ב-Falcon H1 Tiny 90M Instruct.
מקווה שהמדריך הזה יועיל ויחסוך שאלות מיותרות.
אם משתמש נתקל בתקלות ובעיות בהרצת מודלים, אפשר לשאול כאן או באישי, ואם אחשוב שזה עשוי להועיל לציבור אוסיף את התקלה ופתרונה למדריך.
אשמח לקבל משוב בתגובות והצעות לשיפור המדריך!
-
-
@א.מ.ד. וואו!! איזה מדריך מושקע וארוך! כל הכבוד!
איזה ראש יש לך.. נראה לי אתה יכול להריץ את כל המודלים בראש שלך..

-
אוקי.
@א.מ.ד. וווואאווו!!!
שוב פעם הוכחת את עצמך ובגדול!
חודשים אנחנו מחכים לזה!@חירות-ציון כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
אפליקציה שמשתמשת בספריית WEB VIEW המובנה של ווינדוס וכיו"ב...
היא לא שוקלת ג"כ? אמנם לא כמו הכרומיום.
אבל עדיין..@אורי כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
תוכל להוסיף הסבר על NPU. איך אפשר לרתום את זה להרצה מהירה יותר של מודלים אופליין?
לדוג', המחשב שלי מגיע עם 12TOPS, מה שזה לא אומר...לא אפשרי.
או יותר נכון, גם אם נניח שזה אפשרי, (ולא מצאתי תוכנות שמשתמשות בזה פרט לתוכנות מערכת) זה ידרוש (כנראה) ידע מורכב בנושא.@א.מ.ד. כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש לי חומרה בערך כמו שלך עם מעבד i5, וזה הרבה יותר מהר:
זה לא בהכרח.
ייתכן שיש לו תוכנות נוספות על המחשב.
@עידו300 אילו תוכנות מותקנות לך?@א.מ.ד. כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
אין קשר בין זה לזה. LM Studio הוא כלי להרצת מודלים, ו-OpenClaw הוא סוכן מקומי שיכול להתחבר למודלי ענן או למודלים מקומיים.
בכללי (וגם לפי המלצה שלך בעצמך
)לא כדאי להתייעץ עם ג'מיני בנושאים האלה.@חובבן-מקצועי בליבות שאמרת התכוונת לתוכנות שמורצות על המחשב בנוסף לזו?
@jc324118983 כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
סליחה. אבל מה שהתכונתי לשאול זה לאחד שהוא רק רוצה שאלות ותשובות וכדומה האם יש הבדל ביניהם.
יש, בדרך ההתקנה וההרצה (אולמה זה בלי ממשק גרפי, וממילא בכמות המשאבי עיבוד שזה תופס), בכל מקרה הייתי ממליץ לעבור לLM סטודיו, תוםס קצת יותר משאבים, אבל מדבריך נשמע שאינך עוסק בתחום, ואולמה זה כלי שמיועד למפתחים.
דרך אגב @א.מ.ד. ידעת שלאולמה יש ייתרון שההרצה של כל שיחה מחדש מתבססת על אותו מופע שכבר טעון לVRAM? לכן רק פעם ראשונה זה לוקח זמן ואחרי זה, זה הרבה יותר מהר..
כך או כך, מדריך מוסבר מפורט ומושקע.
שאפו!!! -
אוקי.
@א.מ.ד. וווואאווו!!!
שוב פעם הוכחת את עצמך ובגדול!
חודשים אנחנו מחכים לזה!@חירות-ציון כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
אפליקציה שמשתמשת בספריית WEB VIEW המובנה של ווינדוס וכיו"ב...
היא לא שוקלת ג"כ? אמנם לא כמו הכרומיום.
אבל עדיין..@אורי כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
תוכל להוסיף הסבר על NPU. איך אפשר לרתום את זה להרצה מהירה יותר של מודלים אופליין?
לדוג', המחשב שלי מגיע עם 12TOPS, מה שזה לא אומר...לא אפשרי.
או יותר נכון, גם אם נניח שזה אפשרי, (ולא מצאתי תוכנות שמשתמשות בזה פרט לתוכנות מערכת) זה ידרוש (כנראה) ידע מורכב בנושא.@א.מ.ד. כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש לי חומרה בערך כמו שלך עם מעבד i5, וזה הרבה יותר מהר:
זה לא בהכרח.
ייתכן שיש לו תוכנות נוספות על המחשב.
@עידו300 אילו תוכנות מותקנות לך?@א.מ.ד. כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
אין קשר בין זה לזה. LM Studio הוא כלי להרצת מודלים, ו-OpenClaw הוא סוכן מקומי שיכול להתחבר למודלי ענן או למודלים מקומיים.
בכללי (וגם לפי המלצה שלך בעצמך
)לא כדאי להתייעץ עם ג'מיני בנושאים האלה.@חובבן-מקצועי בליבות שאמרת התכוונת לתוכנות שמורצות על המחשב בנוסף לזו?
@jc324118983 כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
סליחה. אבל מה שהתכונתי לשאול זה לאחד שהוא רק רוצה שאלות ותשובות וכדומה האם יש הבדל ביניהם.
יש, בדרך ההתקנה וההרצה (אולמה זה בלי ממשק גרפי, וממילא בכמות המשאבי עיבוד שזה תופס), בכל מקרה הייתי ממליץ לעבור לLM סטודיו, תוםס קצת יותר משאבים, אבל מדבריך נשמע שאינך עוסק בתחום, ואולמה זה כלי שמיועד למפתחים.
דרך אגב @א.מ.ד. ידעת שלאולמה יש ייתרון שההרצה של כל שיחה מחדש מתבססת על אותו מופע שכבר טעון לVRAM? לכן רק פעם ראשונה זה לוקח זמן ואחרי זה, זה הרבה יותר מהר..
כך או כך, מדריך מוסבר מפורט ומושקע.
שאפו!!!@המלאך כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש, בדרך ההתקנה וההרצה (אולמה זה בלי ממשק גרפי, וממילא בכמות המשאבי עיבוד שזה תופס), בכל מקרה הייתי ממליץ לעבור לLM סטודיו, תוםס קצת יותר משאבים, אבל מדבריך נשמע שאינך עוסק בתחום, ואולמה זה כלי שמיועד למפתחים.
דרך אגב @א.מ.ד. ידעת שלאולמה יש ייתרון שההרצה של כל שיחה מחדש מתבססת על אותו מופע שכבר טעון לVRAM? לכן רק פעם ראשונה זה לוקח זמן ואחרי זה, זה הרבה יותר מהר..גם כשאני צריך שרת ברקע אני משתמש בשרת של LM Studio, הוא הרבה יותר נוח ומונגש וקל לשליטה. חיברתי אותו ל-Open Code ו-OpenClaw. וגם ב-LM Studio כל היסטוריית השיחה שמורה במטמון, זה נקרא מטמון KV. בכל תוכנה זה ככה. לדוגמא בחיבור שעשיתי ל-Open Code, אפילו שאילתת "היי!" בלבד בתחילת השיחה דורשת יותר מ-10,000 טוקנים, והעיבד שלהם לוקח דקה-שתיים, ואז בהמשך השיחה כל הודעה לוקחת שניות בודדות.
מפתח אפליקציות אנדרואיד
em0548438097@gmail.com -
אוקי.
@א.מ.ד. וווואאווו!!!
שוב פעם הוכחת את עצמך ובגדול!
חודשים אנחנו מחכים לזה!@חירות-ציון כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
אפליקציה שמשתמשת בספריית WEB VIEW המובנה של ווינדוס וכיו"ב...
היא לא שוקלת ג"כ? אמנם לא כמו הכרומיום.
אבל עדיין..@אורי כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
תוכל להוסיף הסבר על NPU. איך אפשר לרתום את זה להרצה מהירה יותר של מודלים אופליין?
לדוג', המחשב שלי מגיע עם 12TOPS, מה שזה לא אומר...לא אפשרי.
או יותר נכון, גם אם נניח שזה אפשרי, (ולא מצאתי תוכנות שמשתמשות בזה פרט לתוכנות מערכת) זה ידרוש (כנראה) ידע מורכב בנושא.@א.מ.ד. כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש לי חומרה בערך כמו שלך עם מעבד i5, וזה הרבה יותר מהר:
זה לא בהכרח.
ייתכן שיש לו תוכנות נוספות על המחשב.
@עידו300 אילו תוכנות מותקנות לך?@א.מ.ד. כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
אין קשר בין זה לזה. LM Studio הוא כלי להרצת מודלים, ו-OpenClaw הוא סוכן מקומי שיכול להתחבר למודלי ענן או למודלים מקומיים.
בכללי (וגם לפי המלצה שלך בעצמך
)לא כדאי להתייעץ עם ג'מיני בנושאים האלה.@חובבן-מקצועי בליבות שאמרת התכוונת לתוכנות שמורצות על המחשב בנוסף לזו?
@jc324118983 כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
סליחה. אבל מה שהתכונתי לשאול זה לאחד שהוא רק רוצה שאלות ותשובות וכדומה האם יש הבדל ביניהם.
יש, בדרך ההתקנה וההרצה (אולמה זה בלי ממשק גרפי, וממילא בכמות המשאבי עיבוד שזה תופס), בכל מקרה הייתי ממליץ לעבור לLM סטודיו, תוםס קצת יותר משאבים, אבל מדבריך נשמע שאינך עוסק בתחום, ואולמה זה כלי שמיועד למפתחים.
דרך אגב @א.מ.ד. ידעת שלאולמה יש ייתרון שההרצה של כל שיחה מחדש מתבססת על אותו מופע שכבר טעון לVRAM? לכן רק פעם ראשונה זה לוקח זמן ואחרי זה, זה הרבה יותר מהר..
כך או כך, מדריך מוסבר מפורט ומושקע.
שאפו!!!@המלאך כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
אולמה זה בלי ממשק גרפי
יש לו ממשק גרפי פשוט ונוח, (אני לא כל כך אוהב את LM הוא יותר מדי מבלגן)
-
@המלאך כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש, בדרך ההתקנה וההרצה (אולמה זה בלי ממשק גרפי, וממילא בכמות המשאבי עיבוד שזה תופס), בכל מקרה הייתי ממליץ לעבור לLM סטודיו, תוםס קצת יותר משאבים, אבל מדבריך נשמע שאינך עוסק בתחום, ואולמה זה כלי שמיועד למפתחים.
דרך אגב @א.מ.ד. ידעת שלאולמה יש ייתרון שההרצה של כל שיחה מחדש מתבססת על אותו מופע שכבר טעון לVRAM? לכן רק פעם ראשונה זה לוקח זמן ואחרי זה, זה הרבה יותר מהר..גם כשאני צריך שרת ברקע אני משתמש בשרת של LM Studio, הוא הרבה יותר נוח ומונגש וקל לשליטה. חיברתי אותו ל-Open Code ו-OpenClaw. וגם ב-LM Studio כל היסטוריית השיחה שמורה במטמון, זה נקרא מטמון KV. בכל תוכנה זה ככה. לדוגמא בחיבור שעשיתי ל-Open Code, אפילו שאילתת "היי!" בלבד בתחילת השיחה דורשת יותר מ-10,000 טוקנים, והעיבד שלהם לוקח דקה-שתיים, ואז בהמשך השיחה כל הודעה לוקחת שניות בודדות.
@א.מ.ד. כן הכרתי את מטמון KV. אבל ממה שקראתי זה היה נראה מעבר לזה.
כלומר היה נראה שזה מוסיף מעבר לKV סטנדרטי.@jc324118983 כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש לו ממשק גרפי פשוט ונוח, (אני לא כל כך אוהב את LM הוא יותר מדי מבלגן)
לא הבנתי את כוונתך.
אולמה זה ממשק שורת פקודה. טקסטואלי. -
@א.מ.ד. כן הכרתי את מטמון KV. אבל ממה שקראתי זה היה נראה מעבר לזה.
כלומר היה נראה שזה מוסיף מעבר לKV סטנדרטי.@jc324118983 כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש לו ממשק גרפי פשוט ונוח, (אני לא כל כך אוהב את LM הוא יותר מדי מבלגן)
לא הבנתי את כוונתך.
אולמה זה ממשק שורת פקודה. טקסטואלי.@המלאך
בעדכון האחרון הוא יצא כתוכנה עם ממשק גרפי נוח -
@א.מ.ד. כן הכרתי את מטמון KV. אבל ממה שקראתי זה היה נראה מעבר לזה.
כלומר היה נראה שזה מוסיף מעבר לKV סטנדרטי.@jc324118983 כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יש לו ממשק גרפי פשוט ונוח, (אני לא כל כך אוהב את LM הוא יותר מדי מבלגן)
לא הבנתי את כוונתך.
אולמה זה ממשק שורת פקודה. טקסטואלי. -
@המלאך כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
בכל מקרה, זה וודאי כלי שמיועד למפתחים ופחות לאנשים רגילים..
הממשק הגפי הוא מאוד פשוט ומותאם במיוחד לאנשים פשוטים
-
@המלאך כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
בכל מקרה, זה וודאי כלי שמיועד למפתחים ופחות לאנשים רגילים..
הממשק הגפי הוא מאוד פשוט ומותאם במיוחד לאנשים פשוטים
@jc324118983 לא התכוונתי מהבחינה הזו.
התכוונתי מבחינת הapi, המודלים המותאמים וכו'.. -
ביקשו ממני בכמה מקומות לכתוב מדריך על הרצת מודלי AI באופן מקומי, וסקירות על מודלים מתאימים, יחד עם אינספור שאלות כמו מה כדאי להריץ על חומרה כזאת וכזאת, איזה מודל טוב בעברית, וכו'.
מכיוון שלפי חוקי הפורום חל איסור על העלאת כלים ומודלים להרצה אופליין בשל פריצת סינונים, המדריך לא יכלול קישורים אליהם (ייתכן שיהיה אפשרי להוסיף רק קישורים רשמיים שמן הסתם חסומים בנטפרי, אבדוק בעז"ה מול מנהלי הפורום). אין מה לבקש באישי מודלים בדרייב, כי אני לא מתכוון להעלות.
אם יהיה שינוי בחוקי הפורום בנושא, המדריך יעודכן בהתאם.ביקשתי מ-Gemini שייצור לי אינפוגרפיקות להמחשה על בסיס קטעי המדריך שהעליתי לו, לנוחותכם.
רקע: המהפכה המקומית
במקביל לצמיחת מהפכת ה-AI בשנים האחרונות, מתרחשת מהפכה מעניינת לא פחות - מהפכת ה-AI המקומי.
למה בעצם אנשים מתאמצים להריץ מודלים מקומיים, כשאפשר פשוט להיכנס לדפדפן או לאפליקציה ולשוחח עם Gemini או GPT?יש לזה כמה סיבות, רובן פחות רלוונטיות עבורנו. הנה חלקן:
-
פרטיות: במודלי ענן, כל הנתונים נשלחים לשרת כלשהו במרחבי האינטרנט, ואנחנו לא יכולים להיות רגועים ב-100% שהם מאובטחים ולא מועברים הלאה. בשכבות השימוש החינמיות הנתונים בדרך כלל משמשים לאימון הגרסה הבאה של המודלים.
ועוד לא דיברנו על חברות, עמותות וארגונים ממשלתיים, שמובן מאליו שלא תמיד יכולים להשתמש במודל ענן, מטעמי חיסיון וצנעת הפרט, סודות מסחריים ועוד, ויש חשיבות גבוהה במיוחד לפרטיות, ומודל מקומי שרץ בתוך המשרד או החברה הוא הפיתרון היחיד. -
עלות: כשמשתמשים ב-AI במסות עצומות, העלות גבוהה מאד. גם כשמקודדים פרוייקטים שלמים ב-AI בפלטפורמות כמו קלוד קוד וכדומה, זה יכול להגיע לסכומים מאוד גבוהים, וכשמריצים מודל מספיק איכותי באופן מקומי העלות היחידה היא "רק" החומרה והחשמל.
-
אופליין: להסקה ללא חיבור לאינטרנט. מתאים למטיילים במקומות ללא אינטרנט, טסים במטוס, תת קרקע ואחרים ללא חיבור לאינטרנט.
מן הסתם זו הסיבה הנפוצה ביותר בקרב המגזר החרדי... -
עקיפת צנזורות: במדינות שבהן קיים פיקוח הדוק על תכני הרשת, כמו סין, רוסיה, איראן ועוד, יש ביקוש נרחב למודלי שפה פתוחים יותר שזמינים בכיס.
-
שעשוע נחמד
: להנות מהמחשבה שיש לך GPT קטנטן בתוך הכיס... לראות את הפלאפון השברירי שלך פולט תשובות, מספר סיפורים ועוד, וכל זה ללא אינטרנט...
(גילוי נאות: זו הסיבה האהובה עלי, ומה שגורם לי להשקיע בזה הרבה משעות הפנאי שלי...)
חומרה: RAM ו-VRAM
כדי להריץ מודל באופן מקומי, תנאי הסף הוא חומרה מספקת. ישנם שני מרכיבים עיקריים בחומרה שקריטיים להרצת מודלים:
-
RAM: הזיכרון הזמני של המחשב, שמשמש את המעבד לאחסון זמני של נתונים בזמן העיבוד. מחשבים סטנדרטיים מחזיקים ב-16 GB RAM, אחרים 8 או 32.
-
VRAM: זיכרון וירטואלי. קיים בשבבי GPU (כרטיסי מסך) חזקים. בעיקרון נועד למשימות גרפיות מיוחדות, כמו עריכת וידאו מקצועית או גיימינג, אבל בשנים האחרונות משמש גם להאצה משמעותית של הרצת מודלי AI בשל מהירות העיבוד הרבה שהוא מאפשר וגישה מהירה לזיכרון הוירטואלי. בדרך כלל לא קיים במחשבים סטנדרטיים.
(ישנם עוד מרכיבים חשובים מאוד, כמו רוחב פס ועוד, אבל זה פחות רלוונטי לעכשיו.)
בדרך כלל כשמריצים מודל על חומרה סטנדרטית (RAM בלבד) בפלאפונים ומחשבים, הגודל המומלץ של המודל צריך להיות כמחצית מסך ה-RAM הכולל, כדי להשאיר מספיק זיכרון לפעילות מערכת ההפעלה ותהליכי מערכת אחרים. לדוגמא, אם יש במחשב 16 RAM, הגודל המומלץ של המודל יהיה 7-8GB, אלא אם כן ישנן תוכנות כבדות שפתוחות במקביל להרצת המודל ותופסת מקום משלהן.
כמו כן, ככל שיש יותר RAM מעבר לסטנדרט, לדוגמא במחשבי פרימיום עם 32 RAM, מתפנה הרבה יותר מקום פנוי ב-RAM עבור הרצת המודל, ואפשר להריץ אפילו מודלים ששוקלים 24GB ויותר.
קוונטיזציה (כימות)
כמו שכתבתי בקטע הקודם, אם יש לי במחשב 16 RAM, מתפנה לי כ-8GB עבור הרצת מודל מקומי. הבעיה היא, שמודל AI ללא כימות שוקל בערך פי שניים ממספר הפרמטרים שלו, לדוגמא מודל של 7B שוקל בערך 14GB...
למתקדמים: פרמטר הוא בעצם מספר עשרוני (לדוגמא 0.12345678-). ללא כימות הוא מורכב מ-16 ביטים (סיביות).
כל בייט (בית) באחסון מכיל 8 ביטים (סיביות), ולעומת זאת כאמור כל פרמטר במודל מורכב מ-16 ביטים, כך שכל פרמטר מורכב משני בייטים.
אם נכפיל את הפרמטרים, אז מודל של 7B יהיה מורכב מ-14 מיליארד בייטים ששווים לבערך 14GB (ליתר דיוק קצת פחות, כי בשטח אחסון הכפולות הן של 1024 ולא 1000).זה משאיר לנו להשתמש רק במודלים קטנים מאוד, בדוגמא שלנו - 4B בערך...
בשביל זה נועד הכימות, או קוונטיזציה בלועזית: דחיסה של פרמטרי המודל.
חוקרי ה-AI גילו שעיגול של הספרות האחרונות שאחרי הנקודה בכל פרמטר, עד רמה מסוימת אינו פוגע משמעותית בדיוק של המודל, אבל כתוצאה מכך המודל הופך לקטן ומהיר יותר.
לדוגמא, כימות של 8 ביט, כלומר שכל פרמטר מורכב מ-8 ביטים במקום מ-16, חותך את גודל המודל ב-50% (יחס של 1:1 בין הפרמטרים לבייטים), תוך פגיעה מינימלית בדיוק.
כימות של 4 ביט, חותך את גודל המודל ב-75% (יחס של 1:0.5) בין הפרמטרים לבייטים), תוך פגיעה בלתי מורגשת לעין אנושית בדיוק.
הסטנדרט בהרצה מקומית הוא כימות של 4 ביט. כימות חזק יותר כבר פוגע משמעותית בדיוק של המודל (ראה בסקירת המודלים השונים בהמשך אודות מודלי Bonsai החדשניים בעלי כימות של 1 ביט - חיסכון של 93% בגודל המודל!!!).ככה שאם יש לנו 8GB פנויים להרצת המודל, נוכל להריץ עליהם אפילו מודלים של 13-14B בכימות של 4 ביט!
הכימות מוצג בשם קובץ המודל אחרי האות Q (קיצור של Quantization) - כימות של 8 ביט: Q8, כימות של 4 ביט: Q4 וכן הלאה.
בנוסף לעובדה שהירידה בדיוק המודלים היא מינורית, פותחה שיטת כימות חדשה שמצמצמת את הירידה בדיוק עוד יותר: IQ (Importance Quantization = כימות לפי חשיבות).
בשיטה הזאת, הכימות אינו אגרסיבי ואחיד לכלל הפרמטרים במודל, אלא האלגוריתם, באמצעות הרצה של המודל על טקסט ארוך ומגוון מזהה אילו פרמטרים "נדלקים" הכי הרבה - מה שאומר שהם קריטיים יותר לבינה של המודל, ואילו משניים, ואז שומר על דיוק גבוה בפרמטרים החשובים, ודוחס באגרסיביות (אפילו מתחת ל-2 ביט) את הפרמטרים הפחות חשובים.
התוצאה היא מודל חכם כמו Q4, אבל תופס שטח כמו Q3.
השיטה הזאת אמנם יוצרת מודל חכם וקטן יותר, אבל קצת איטית יותר, מכיוון שתהליך הסקה של מודל מכומת עם IQ דורש מעט יותר חישובים לפיענוח הפרמטרים הדחוסים.ישנם עוד סימונים פחות משמעותיים בכימות - האותיות באנגלית שאחרי רמת הכימות, לדוגמא Q4_K_M, שמייצגות את כמות השכבות של המודל שנדחסות ל-4 ביט, לעומת מספר שכבות קריטיות שנדחסות ל-6 ביט.
בשיטת ה-IQ נראה את הייצוג XXS / XS, כלומר דחיסה קיצונית של יותר שכבות, אבל המודל בכל זאת יישמור על השכל שלו בגלל ייחודיות שיטת ה-IQ. יש גם את הייצוג NL (Non Linear = לא ליניארי), כלומר האלגוריתם משתמש בגרף עקום כדי לקבוע אילו פרמטרים חשובים יותר ולא במדרגות קבועות, מה ששומר עוד יותר על הדיוק של המודל בפרמטרים החשובים.למעשה, הכימות המומלץ לשימוש הוא 4 ביט בשיטת Q, למעט במקרים הבאים:
- אם המודל שאנחנו רוצים להריץ הוא על גבול יכולת ה-RAM שלנו, נבחר בשיטת IQ כדי לחסוך כמה מאות MB ב-RAM.
- במודלים קטנים - פחות מ-3B, כל ביט קריטי, ושם חשובה שיטת ה-IQ כדי לשמור על הבינה של המודל.
- במודלי MoE (הסבר בהמשך), שיטת ה-IQ שומרת על פרמטרים חשובים כמו הנתב שמפעיל את הפרמטרים הרלוונטיים לכל טוקן בדיוק גבוה, ודוחסת פרמטרים פחות רלוונטיים.
- בחומרה חזקה עם GPU, שאז הפרש המהירות לא מורגש, נבחר בשיטת ה-IQ.
לסיכום, אם בוחרים בשיטת Q, מומלץ לבחור ב-Q4_K_M, ואם בוחרים בשיטת IQ מומלץ לבחור ב-IQ4_NL.
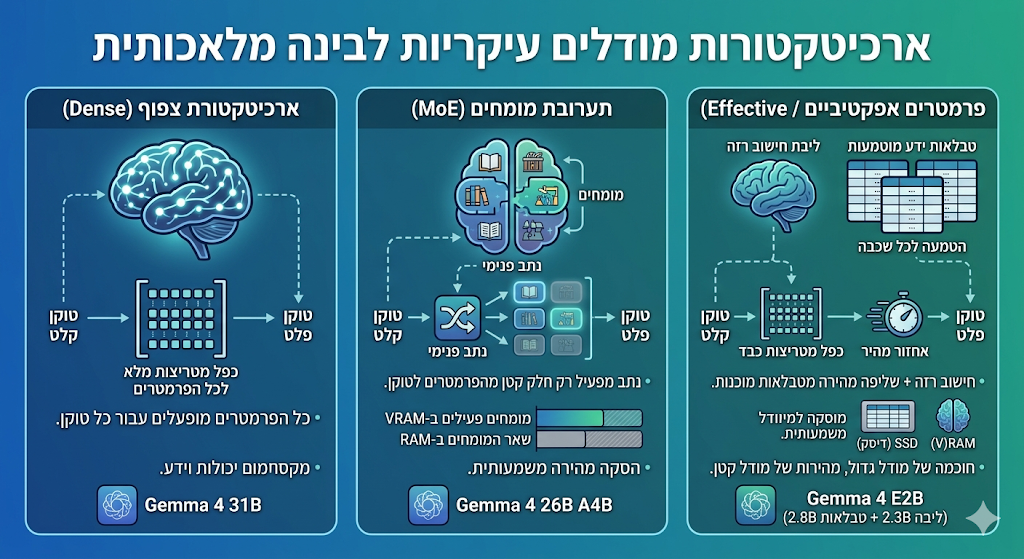
ארכיטקטורת המודל
ישנן 3 ארכיטקטורות מודלים עיקריות:
- צפוף (Dense): מודל רגיל שכל הפרמטרים שלו מופעלים עבור כל טוקן, כך שהמודל ממקסם את היכולות והידע שלו. לדוגמא: Gemma 4 31B.
- MoE (תערובת מומחים): מודל מיוחד שמכיל נתב פנימי שקובע אילו פרמטרים ("מומחים") חשובים עבור כל טוקן, ובמקום להפעיל את כל הפרמטרים לטוקן מפעיל רק חלק קטן מהם, מה שמאיץ משמעותית את ההסקה, ובעיקר מאפשר לתוכנת ההסקה להכניס את הפרמטרים הפעילים ל-VRAM הקטן להסקה במהירות עצומה ולהשאיר את שאר הפרמטרים ב-RAM, מוכנים לשליפה לטוקן הבא, אם כי האיכות פחותה ממודל צפוף. לדוגמא: Gemma 4 26B A4B.
- Effective (פרמטרים אפקטיביים): מודלי ה-E (כמו Gemma 4 E2B ו-E4B) מציגים שיטה חדשה של "הטמעה לכל שכבה" (Per-Layer Embeddings). במודל רגיל, המעבד מבצע כפל מטריצות כבד על כל הפרמטרים בכל שלב - פעולה שדורשת כוח עיבוד רב וזיכרון מהיר (VRAM או לפחות RAM). במודלי E, גוגל פיצלה את המודל לשניים: ליבת חישוב רזה - רק חלק קטן מהפרמטרים (למשל 2.3B מתוך 5.1B ב-E2B) משתתף בחישובים המתמטיים המורכבים, וטבלאות ידע מוטמעות - שאר הפרמטרים (2.8B) מאורגנים כטבלאות נתונים ענקיות שמוטמעות בכל שכבה של המודל.
במקום שהשכבה תחשב את המידע מחדש ב"מוח" שלה, היא פשוט מבצעת אחזור - שליפה מהירה של ערכים מוכנים מהטבלה שרלוונטיים רק לטוקן הספציפי שהיא עובדת עליו כרגע. מכיוון ששליפה מטבלה היא פעולה קלה לעיבוד לעומת חישוב מתמטי, המודל מפגין רמת חוכמה של מודל גדול בהרבה מבלי להאט את מהירות ההרצה. בנוסף, את הטבלאות הללו ניתן לאחסן על הדיסק (SSD) ולא חובה להעמיס אותן על ה-RAM, מה שמאפשר להריץ מודלים איכותיים גם על חומרה מוגבלת.
מודלי VL
מודלי VL (מולטי-מודאליים), הם מודלים שמסוגלים "לראות" תמונות ווידאו ולטפל בהם כקלט ולא רק בטקסט. זה מאפשר להם להשיב על שאלות חזותיות שונות וכדומה.
בפורמט GGUF (יוסבר בהמשך), מודלי ראיה מגיעים עם קובץ נוסף שנקרא mmproj (Multi-Modal Projector), שהוא רכיב שמתווך בין הראייה לבין ה"מוח" הטקסטואלי של המודל.
ישנם מודלי ראיה מיוחדים שאומנו במיוחד עבור משימות OCR (זיהוי טקסט מתמונות), שבהם חלק הראיה גדול מאוד, לעיתים אף יותר מהחלק הטקסטואלי של המודל, כדי להתאים לשימושים שעיקרם ויזואליים.פורמטי מודלים עיקריים
ישנם מספר פורמטים להרצת מודלים באופן מקומי ומהיר. הנפוצים שבהם:
- GGUF: הפורמט הנפוץ ביותר. נתמך במרבית תוכנות ההרצה המקומית. פותח ע"י יוצר llama.cpp. מכיל בקובץ אחד את כל חלקי המודל - המשקולות, הטוקנייזר, המטא-דאטה, תבנית הצ'אט וכו'. מסוגל לפצל את שכבות המודל בין ה-CPU וה-GPU, והוא הנוח והמתקדם ביותר לבדיקה ושימוש גמיש. מחזיק באקו-סיסטם ענק סביבו.
- MNN: פורמט שפותח ע"י אליבאבא, ונחשב לאחד המנועים המהירים ביותר להרצת מודלים על אנדרואיד ו-iOS, עם צריכת סוללה נמוכה מאוד וזמן טעינה מהיר.
- LiteRT: המיתוג מחדש של גוגל ל-TensorFlow Lite, המנוע הוותיק והיציב להרצת מודלי שפה ולמידת מכונה על מכשירי קצה. מותאם בצורה מושלמת לאנדרואיד, ונחשב לפורמט הסטנדרטי והיציב ביותר בתעשייה ליישומים מסחריים.
- MLX: פורמט למחקר והרצת מודלים שפותח על ידי חטיבת ה-AI של Apple. הוא תוכנן במיוחד עבור המעבדים מסדרת Apple Silicon. מתאים לארכיטקטורת הזיכרון המאוחד של מעבדי אפל.
אורך ההקשר (Context)
רבים טועים לחשוב שהדבר היחיד שמשפיע על ה-RAM הנדרש להרצת מודלים מקומיים הוא גודל המודל בלבד.
למעשה יש עוד דבר שמשפיע על הזיכרון לא פחות, ובהרצות מסחריות אף יותר מגודל המודל: מטמון ה-KV.
כדי שהמודל יזכור את מה שנאמר בתחילת השיחה, הוא צריך לשמור סיכום מתמטי של כל הטוקנים הקודמים שחושבו בזיכרון ה-RAM/VRAM. ככל שהשיחה מתארכת וחלון ההקשר ארוך יותר, הזיכרון הזה הולך ותופח.
אפילו במודלים קטנים, אורך הקשר של 32K יכול לתפוס כמה GB טובים בזיכרון, בנוסף למשקל המודל עצמו!
בדרך כלל ברירת המחדל בתוכנות הרצה מקומית היא אורך הקשר של 4096 טוקנים, מה שמצריך "רק" כמה מאות MB בזיכרון, אבל בהסקות מסחריות של מודלים מקומיים על שרתים גדולים, לדוגמא לקידוד מקצועי או לצרכים ארגוניים, אורך הקשר של מיליון טוקנים ידרוש כמה מאות GB בזיכרון!
כדי לחסוך בזיכרון, משתמשים בשיטות של דחיסה או חלוקת ההקשר בין ראשי המודל כמו GQA.
יש גם את Flash Attention, טכנולוגיה שמייעלת את הגישה לטוקני ההקשר האלו בזמן אמת באמצעות חישוב של חתיכות מידע בבת אחת במהירות עצומה בזיכרון המהיר שבתוך המעבד (SRAM) בלי לצאת החוצה ל-RAM בכל טוקן.
גוגל פרסמה לאחרונה שיטה חדשנית בשם TurboQuant, שבה במקום לכמת רק את משקולות המודל, מכמתים גם את טוקני ההקשר בצורה יעילה שלא פוגעת כמעט בדיוק, בכימות קיצוני שחוסך 75% עד 85% מהזיכרון, תוך כדי תנועה!
כרגע TurboQuant עדיין לא הוטמעה רשמית בתוכנות ההסקה המקומית הנפוצות, אבל כשזה יקרה זה יורגש גם עבור משתמשים פשוטים, אבל עבור משתמשים מקצועיים עם חומרת על זה יחסוך מאות GB RAM!RAG
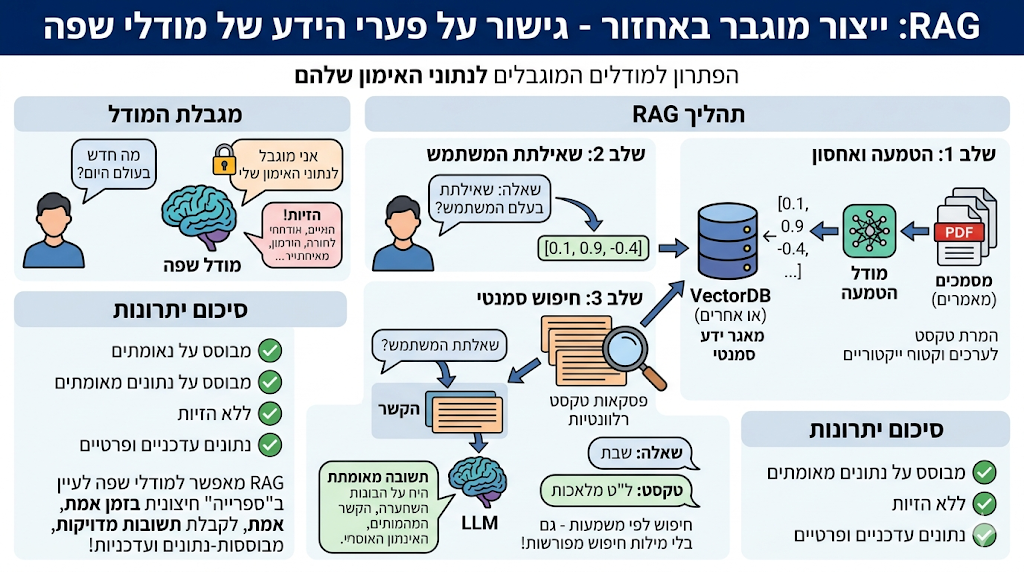
גם המודל הכי חכם שיש, מוגבל למה שהוא למד בזמן האימון שלו. אם תשאלו אותו על קובץ PDF פרטי משלכם, או על חדשות שפורסמו אתמול, הוא פשוט לא יידע, או גרוע מכך - הוא יהזה וימציא תשובה שנשמעת הגיונית.
RAG (ייצור מוגבר באחזור) פותר את זה על ידי כך שהוא נותן למודל "ספרייה" חיצונית לעיון בזמן אמת.
בשלב הראשון המערכת מטמיעה את הטקסטים של המסמכים או מה שזה לא יהיה לערכים וקטוריים ושומרת אותם במסד נתונים בשם VectorDB (או אחרים).
כשהמשתמש שואל שאלה, המערכת לא שולחת אותה מיד למודל, אלא קודם כל מבצעת חיפוש סמנטי (לפי משמעות) במסד הנתונים הוקטורי, ושולפת ממנו את פסקאות הטקסט שהכי קרובות מבחינה סמנטית לטקסט השאלה של המשתמש.
לאחר מכן המערכת מגישה את השאלה מהמשתמש למודל, בתוספת הטקסט ששלפה ממסד הנתונים כחלק מההקשר, וכך המודל יכול להשיב בצורה יעילה שמבוססת על נתונים עדכניים ומאומתים, בלי להזות.
מה שמיוחד ב-RAG הוא שמכיון שהחיפוש הוא סמנטי, המודל יקבל גם פסקאות טקסט שמילות החיפוש לא מופיעות בהן במפורש, אלא רק המשמעות קשורה איכשהו. לדוגמא אם תשאלו על "שבת", המודל יקבל כהקשר גם טקסט בנושא ל"ט מלאכות.
MCP
MCP (ראשי תיבות של Model Context Protocol) הוא תקן פתוח שמאפשר לכל המודלים להתחבר לכלים ונתונים חיצוניים בצורה אחידה. הוא הנושא החם של 2026, ומי שבעצם אחראי לכל מהפכת סוכני ה-AI.
עד לא מזמן, כשהמשתמש רצה שהמודל יבצע עבורו פעולות מסוימות וישתמש בכלים, הא היה צריך לכתוב (או המודל עצמו) קוד מיוחד עבור כל משימה בנפרד. זה היה מסורבל, לא אמין ודרש התאמה לכל מודל.
ה-MCP הוא פרוטוקול סטנדרטי שמאפשר למודל להתחבר לכל שרת MCP חיצוני ולהשתמש בכלים שלו מיד, בלי שום הגדרות מיוחדות.
השיטה מבוססת על 2 חלקים: לקוח ה-MCP - תוכנת ההסקה שבה יושב המודל, ושרת ה-MCP - שרת מקומי בדרך כלל שמורכב מיחידה קטנה של קוד שיודעת לעשות פעולה ספציפית כמו קריאה מקבצים, חיפוש ברשת, גישה ליומן וכדומה.
ברגע שמחברים שרת MCP לתוכנה, המודל מבין מיד אילו כלים נתונים לרשותו ומתחיל להשתמש בהם כשצריך.
ככה, במקום לכתוב כלי ייעודי עבור כל משימה, פשוט מצביעים על כלי מתוך המאגר העצום הקיים ברשת בקובץ mcp.json, והתוכנה מורידה את הכלי ומטפלת בו ונותנת למודל פירוט קצר על כל כלי הכולל את שם הכלי, תיאור על מטרתו ויכולותיו, והסבר אילו פרמטרים הוא צריך.
לדוגמא המודל מקבל כלי קריאה מקבצים בשם read_file עם תיאור על יכולותיו והפרמטרים הנדרשים, וכשהוא מחליט לקרוא תוכן מתוך קובץ הוא מבצע קריאה לכלי:call: read_file(path="notes.txt")MCP זה מה שהופך את המודל לסוכן שיוצא מגבולות הצ'אט לפעולות בעולם האמיתי.
פרוטוקול ה-MCP פותח במקור ע"י חברת אנתרופיק עבור מודלי Claude, אבל הפך לתקן פתוח שכל תעשיית ה-AI אימצה, וכל מודל התומך בקריאה לכלים מאומן מראש על הפרוטוקול הזה.פיענוח ספקולטיבי
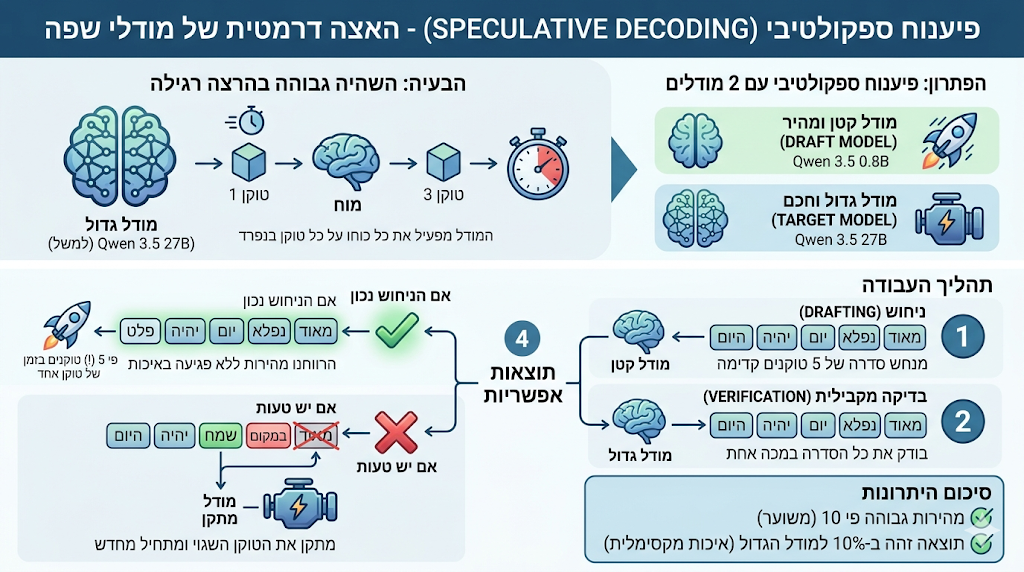
אחת הבעיות הגדולות בהרצת מודלי שפה גדולים היא ההשהיה, בשל העיבוד המקומי האיטי.
מודל גדול של 30B עובד ממש לאט כי הוא צריך להפעיל את כל המוח שלו על כל טוקן.
בשביל זה פותחה טכנולוגיית הפיענוח הספקולטיבי - 2 מודלים מאותה משפחה עם אותו אוצר מילים שרצים במקביל, אחד חכם וכבד - נניח Qwen 3.5 27B, והשני קטן, מהיר וקליל - Qwen 3.5 0.8B.
במקום שהמודל הגדול יחשוב על כל טוקן, המודל הקטן רץ קדימה במהירות ומנחש סדרה של טוקנים (למשל את 5 הטוקנים הבאים במשפט). הוא עושה זאת במהירות עצומה כי הוא קטן וקל משקל. המודל הגדול מקבל את כל 5 הטוקנים בבת אחת ובודק אותם במכה אחת (בפעולת חישוב מקבילית).
אם המודל הקטן צדק, הרווחנו 5 טוקנים בזמן של טוקן אחד!
אם הוא טעה בטוקן השלישי לדוגמא, המודל הגדול מתקן אותו וזורק את השאר, ומתחילים שוב מהנקודה הזו.
בטכנולוגיה הזו ניתן לקבל מהירות גבוהה פי 10 לעומת הרצה רגילה של המודל הגדול, ובמקביל האיכות נקבעת ב-100% ע"י המודל הגדול, כך שאין שום הבדל מבחינת התוצאה!
הנחיית מערכת
רבים נוטים להתעלם מהנחיית המערכת ופשוט מתחילים לשאול שאלות, אז מתלוננים שהמודל גרוע. אבל עבור מודלים מקומיים הנחיית מערכת היא הכלי החזק ביותר שלכם כדי לקבל תוצאות מקצועיות ולא "רובוטיות".
הנחיית המערכת קובעת את הזהות, המומחיות והחוקים שחלים על המודל לאורך כל השיחה.
לא מספיק לכתוב "אתה עוזר חכם", אלא צריך להגדיר למודל מיהו, מה תפקידו המדוייק, מה סגנון הכתיבה, מבנה הפלט, סביבת הריצה שלו, הכלים השונים שעומדים לרשותו ועוד.
כשכותבים למודל בהנחיית המערכת "אתה מומחה לכתיבת קוד Python", זה מכניס אותו למאגר הידע של Python שבתוכו.
ככל שמשקיעים יותר בהנחיית המערכת ונותנים בה למודל יותר מידע רלוונטי, התוצאות טובות יותר בעשרות אחוזים.
יש מאגר בגיטהאב שמרכז דליפות של הנחיות מערכת של מודלי העל כמו Claude ו-Gemini, ושם אפשר לראות שהנחיות המערכת שלהם הן יותר ספר רכב מאשר הנחיה...אפשרויות ההרצה
ישנן מספר רב של תוכנות ואפליקציות להרצת מודלי AI ללא אינטרנט, ונסקר את העיקרית שבהן.
כאמור בהתאם לחוקי הפורום לא אוכל לצערי לשתף קישורים להורדת התוכנות, ואם יהיה שינוי בחוקי הפורום כמובן שאעדכן את הפוסט עם קישורים לכל תוכנה.Windows:
- LM Studio:
התוכנה הנוחה ביותר להרצת מודלים, עם הגמישות הגדולה ביותר ותמיכה בטכנולוגית מתקדמות.- תומכת במודלים בפורמט GGUF, ובמחשבי אפל גם בפורמט MLX.
- יצירת שרת מקומי לשימוש בתוכנות אחרות, כלי שורת פקודה וסוכני AI שונים.
- תומך במודלי ראיה.
- תמיכה בפיענוח ספקולטיבי.
- תמיכה בקריאה לכלים.
- כוללת RAG.
- מבוססת על ליבת llama.cpp.
- הממשק הגמיש והנוח ביותר, עם שליטה בהגדרות רבות.
למדריך מפורט ומושקע של @חובבן-מקצועי האלוף על השימוש בתוכנה, היכנסו לכאן.
- Ollama:
הסטנדרט עבור הרצת מודלים בשורת הפקודה או כשרת רקע.
נועד למשתמשים שצריכים API מקומי יציב ופשוט, ולמשתמשים שמעדיפים ממשק מינימליסטי.
- Llama.cpp:
המנוע שמתחת למכסה המנוע. כמעט כל התוכנות והאפליקציות האחרות, כולל LM Studio ו-Ollama, מבוססות עליו.- פרוייקט קוד פתוח ב-C++, שנועד להריץ מודלים במינימום משאבים.
- גמישות מלאה ושליטה על כל פרמטר.
- המהירות הגבוהה ביותר בדרך כלל, מכיון שאין שכבות גרפיות מעל המנוע.
- דורש ידע בעבודה עם שורת הפקודה.
- תמיכה ראשונית בכל טכנולוגיה חדשה או מודל חדש מופיעה כאן לראשונה.
- Jan:
חלופה מודרנית וקלילה ל-LM Studio, עם דגש חזק על קוד פתוח ופרטיות.- ממשק נקי ופשוט, ידידותי למשתמשים מתחילים.
- כולל גרסה ניידת.
- RAG ותוספים.
Android:
- PocketPal AI:
האפליקציה היציבה והנוחה ביותר. מבוססת על Llama.cpp, ומתעדכנת כל כמה ימים בדרך כלל.- תמיכה במודלי GGUF.
- תמיכה במודלי ראיה, עם אפשרות לטעון את המודל ללא רכיב הראיה לביצועים מהירים יותר.
- תמיכה בשכפול צ'אטים.
- שליטה מלאה בפרמטרי ההסקה.
- בנצ'מרק למדידת ביצועי הסקה במכשירים שונים.
- Pals - מערכת ליצירת סוכנים במגוון תחומים.
- כוללת עברית - תורגם על ידי כתרומה לפרוייקט.
- Google AI Edge Gallery:
האפליקציה להרצת מודלי AI מבית Google. המתאימה ביותר לביצועי רקע וחיסכון בסוללה. משמשת בעיקרון ככלי הניסוי של גוגל למודלי Gemma הקטנים, בעיקר E2B ו-E4B.- מבוססת על מנוע LiteRT שפותח ע"י Google.
- הגרסאות האחרונות כוללות פיצ'רים מעניינים המבוססים על מודלי Gemma 4, כמו המיומנויות - לדוגמא קריאה מויקיפדיה, הצגת מיקום במפות גוגל ועוד.
- תומכת בקלט תמונה ואודיו עבור מודלים נתמכים.
- תרגום דיבור.
- תמלול.
- מעבדת הנחיות - סביבת עבודה ייעודית לבדיקת הנחיות שונות.
- פעולות מובייל - ביצוע פעולות במכשיר באמצעות מודל קריאה לכלים זעיר.
- משחק גננות זעיר המופעל באמצעות מודל קריאה לכלים זעיר.
- החיסרון העיקרי: לא שומרת היסטוריית שיחות.
- MNN Chat:
אפליקציה להרצת מודלים בפורמט MNN שפותחה גם היא כמו הפורמט ע"י אליבאבא. נכון להיום, משמשת כפיתרון המהיר ביותר להרצת מודלים באנדרואיד.- חושפת שרת מקומי לשימוש מאפליקציות אחרות ואפליקציות אוטומציה כמו מאקרודרואיד וטאסקר.
- תומכת במודלי Qwen Omni - מודלים התומכים בקלט טקסט, תמונה ואודיו ופלט טקסט ואודיו.
- תמיכה במודל Stable Diffusion ליצירת תמונות מקומית.
- חסרונות עיקריים - חוסר יציבות ואי-אמינות, תמיכה מאוחרת במודלים חדשים, תמיכה רק במודלים המעטים שהומרו לפורמט המתאים.
ישנן עוד אפליקציות רבות המבוססות על Llama.cpp, הטובות שבהן:
- Off Grid
- InferrLM
- LLM Hub
בעז"ה אפרט עליהן בעדכונים הבאים למדריך.
פיתרון בעיות בהרצה
כאן ירוכזו בעיות בהרצת מודלי AI מקומיים ופתרונן.
בעיה בטעינת מודלי Gemma 4, Qwen 3.5 ומודלים נוספים ב-LM Studio
פיתרון הבעיה בספויילר:
הפיתרון: מדובר בשגיאה בטעינת מודלים הכוללים יכולות ראיה. התוכנה לא מזהה את קובץ ה-mmproj שאחראי על תיווך הראיה למוח הטקסטואלי של המודל, אם הוא נמצא בנתיב המכיל אותיות עבריות, ולכן מתרחשת שגיאה אם שם המשתמש במחשב כולל אותיות עבריות וטעינת המודלים נכשלת.
הפיתרון הוא כמובן לוודא קודם כל שהגרסה המותקנת של LM Studio היא העדכנית ביותר כדי לוודא תמיכה במודלים, ולאחר מכן יש להעביר את תיקיית "models" מהנתיב הזה:C:\Users\<שם_המשתמש_שלך>\.cache\lm-studio\modelsאל תיקיית השורש של הכונן - לדוגמא C, ואז להיכנס להגדרות ב-LM Studio, בכרטיסיית General, לגלול למטה עד Models Directory, ללחוץ על 3 הנקודות בצד ולבחור ב-Change ואז לבחור בנתיב החדש שלנו -
C:\modelsכעת המודלים אמורים להיטען בהצלחה, כולל רכיב הראיה!
איך לאפשר\להשבית מצב חשיבה ב-Gemma 4 ב-LM Studio?
ראה מדריך מפורט לניהול מצב החשיבה כאן.
משפחות המודלים וסקירה מקיפה (מתעדכן!)
להלן יפורטו משפחות המודלים העיקריות, עם פירוט על המודלים האחרונים בכל סדרה ויכולותיהם, קטנים ובינוניים - עד גודל של 35B.
אם לחברה כלשהיא יש מודלים ישנים יותר אך עדיין רלוונטיים, לדוגמא בשל כך שאין להם תחליף מאותה משפחה באותו טווח גודל, הבאתי גם אותם.
Gemma
משפחת המודלים הפתוחים של גוגל, המבוססת על הטכנולוגיה של מודלי Gemini.
מודלי Gemma בכללותם מצטיינים בשפות רבות, כולל עברית, וידועים ביציבותם וב"מערביות" שלהם, ובכך שהם מודלים "צפויים" שאפשר לסמוך עליהם לשימוש אמיתי. המודלים החדשים במשפחה נחשבים כיום למודלים החזקים ביותר כמעט בכל תחום, למעט בתחום הקידוד.
המודלים העדכניים של החברה:- Gemma 4 31B: המודל החכם ביותר במשפחה ובעולם המודלים הפתוחים בטווח הגודל הבינוני. מודל צפוף. ביצועים דומים למודלי העל מדור קודם. בעל יכולות ראיה וחשיבה. תומך בעברית.
- Gemma 4 26B A4B: מודל MoE. מודל חכם אך מהיר בשל כך שרק 4B פרמטרים מופעלים על כל טוקן. בעל יכולות ראיה וחשיבה. תומך בעברית.
- Gemma 4 E4B: מודל מסוג Effective, עם סה"כ 5.1B פרמטרים. נועד לפעול על מחשבים סטנדרטיים. תומך בקלט תמונה ואודיו. בעל יכולות חשיבה. תומך בעברית.
- Gemma 4 E2B: מודל מסוג Effective, עם סה"כ 8B פרמטרים. נועד לפעול על סמארטפונים סטנדרטיים. תומך בקלט תמונה ואודיו. בעל יכולות חשיבה. תומך בעברית.
- Gemma 3 12B: מודל צפוף, אמנם מהדור הקודם, אבל עדיין מהחזקים בטווח הגודל שלו. בעל יכולות ראיה. תומך בעברית.
- Gemma 3 1B: מודל קטן במיוחד מדור קודם, שנועד לפעול על חומרה חלשה במיוחד, למגוון משימות הדורשות בעיקר מהירות ופחות ידע.
- Gemma 3 270M: מודל זעיר מדור קודם, מהחזקים בגודלו, שנועד בעיקר לכוונון עדין למשימות הדורשות תגובה במהירות שיא.
- TranslateGemma 4B\12B: מודלי תרגום רב לשוניים, המבוססים על מודלים מסדרת Gemma 3. בעלי ביצועי תרגום מהטובים בעולם. תומך בתרגום ל\מעברית.
- FunctionGemma 270M: מודל זעיר המבוסס על המודל הזעיר מסדרת Gemma 3, שכוונן במיוחד לקריאה לכלים, ונועד לכוונון עדין להתאמה ספציפית למשימות קריאה לכלים.
Qwen
משפחת המודלים של חברת Qwen מבית אליבאבא הסינית. פורצי דרך בתחום המודלים הפתוחים. המודלים ממשפחת Qwen נחשבים למודלים מהטובים ביותר בכל תחום, והטובים ביותר בתחום הקידוד. כל המודלים מהסדרה האחרונה - Qwen 3.5 אומנו מראש באופן טבעי על תמיכה בקלט תמונה.- Qwen 3.5 35B A3B: מודל MoE. מהטובים לגודלו, מתאים במיוחד למנוע עבור סוכני AI מקומיים בשל האיזון בין יכולות גבוהות לבין מהירות הסקה גבוהה. בעל יכולות ראיה וחשיבה. תומך בעברית.
- Qwen 3.5 27B: מודל צפוף. הטוב ביותר לקידוד מבין המודלים הפתוחים בטווח הגודל הבינוני. בעל יכולות ראיה וחשיבה. תומך בעברית.
- Qwen 3.5 9B: מודל צפוף. הטוב ביותר לגודלו. נחשב למודל הקטן ביותר המסוגל להחזיק לבדו מערכת סוכני קידוד. בעל יכולות ראיה וחשיבה. תמיכה חלקית בעברית.
- Qwen 3.5 4B: מודל קטן, המחזיק בביצועי קידוד מרשימים לגודלו, המתקרבים לביצועי GPT 4. בעל יכולות ראיה וחשיבה.
- Qwen 3.5 2B: מודל קטן במיוחד, המתאים לביצוע מגוון משימות הדורשות מהירות ויעילות. מחזיק ביכולות מרשימות ביחס לגודלו. מתאים כמודל OCR קטן ומהיר. בעל יכולות ראיה וחשיבה.
- Qwen 3.5 0.8B: מודל זעיר במיוחד, המתאים לביצוע משימות פשוטות במהירות שיא, וניתן לכוונון עדין למשימות ספציפיות. מחזיק ביכולות מרשימות ביחס לגודלו. בעל יכולות ראיה וחשיבה.
- Qwen3 Coder 30B A3B Instruct: מודל MoE מיוחד לקידוד המבוסס על המודל מהדור הקודם. בעל יכולות קידוד מרשימות. תומך בעברית.
סדרת Qwen 3.5 הביאה איתה גל של כוונונים עדינים למודלי הסדרה, המשפרים את ביצועי המודלים בשלל תחומים. בדרך כלל לא מומלץ להשתמש במודלים מכווננים אלא להישאר עם המודל המקורי, אך בסדרה הזו ישנם 2 מודלים שמומלצים אף יותר מהמודל המקורי:
- Qwopus 3.5 4B\9B\27B (או השם הקודם - Qwen 3.5 Claude 4.6 Opus Reasoning Distilled עבור גרסאות 0.8B\2B\35B A3B): אימון של מודלי Qwen 3.5 על עקבות מחשבה של Claude 4.6 Opus. האימון המיוחד משפר ומקצר דרמטית את אורך שרשרת החשיבה של המודלים, תוך שמירה על איכות המודלים ואף ביצועים טובים יותר.
- OmniCoder 9B: - כוונון עדין מיוחד של מודל ה-9B של Qwen 3.5 המשפר באופן משמעותי את ביצועי הקידוד של המודל.
GPT-OSS
משפחת המודלים GPT-OSS של חברת OpenAI, ששחררה אותם לאחר לחץ מקהילת המודלים הפתוחים, משקיעים ועוד. נחשבים למודלים בעלי צנזורה חזקה במיוחד, שאף עיכבה את שחרור המודלים פעם אחר פעם כי "לא הייתה מספיק בטוחה"... המודלים נחשבים למודלים חכמים מאוד ואמינים במיוחד.- GPT-OSS 20B: מודל MoE עם 3.6B פרמטרים פעילים. מהטובים ביותר בגזרת המודלים הבינוניים לקידוד ולכל מטרה. בעל יכולות חשיבה. תומך בעברית.
DictaLM
משפחת המודלים מבית חברת דיקטה הישראלית, המתמחים בשפה העברית באופן מיוחד.- DictaLM 3.0 24B Instruct\Thinking: מודל הדגל של החברה, המבוסס על Mistral Small 3.1 24B. מגיע בשני גרסאות - חשיבה ותגובה מיידית, להתאמה לכלל מקרי השימוש. מציג ביצועים מרשימים בעברית.
- DictaLM 3.0 12B Instruct\Thinking: מודל הביניים של החברה, המבוסס על NVIDIA Nemotron Nano 12B v2. גם הוא מגיע בשני גרסאות - חשיבה ותגובה מיידית. מציג ביצועים מרשימים בעברית ביחס לגודלו.
- DictaLM 3.0 1.7B Instruct\Thinking: מודל קטן במיוחד המותאם לריצה על מכשירים עם חומרה חלשה. מבוסס על Qwen3 1.7B. בעל ביצועים מפתיעים בעברית, ונחשב למודל הקטן ביותר המסוגל לשוחח בעברית תקינה לחלוטין, והחכם ביותר בעברית בקטגוריית הגודל שלו. גם הוא מגיע בגרסאות חשיבה ותגובה מיידית.
Aya
משפחת המודלים מבית מעבדות Cohere. מתמקדת ברב-לשוניות.- Tiny Aya 3.35B: סדרת מודלים קטנים המתאימים להרצה על חומרה חלשה, ומתאימים למשימות במגוון ענק של שפות. תומך בעברית. המודל המתאים לשימוש בישראל מתוך הסדרה הוא Tiny Aya Global.
- Aya Expanse 8B\32B: מודלים שמטרתם להרחיב את הבינה המלאכותית לשפות נוספות, ומשיגים ביצועים מרשימים בשפות שונות. די מיושנים כיום, אם כי הביצועים בשפות אחרות נדירות בגדלים כאלו. תומכים בעברית.
LFM
משפחת המודלים מבית LiquidAI היפנית. המודלים במשפחה נחשבים חריגים בשל כך שאינם מבוססים על ארכיטקטורת ה-Transformer הנפוצה, אלא על ארכיטקטורה "נוזלית", שמאיצה את ביצועי ההסקה על מכשירים חלשים. נחשבים למודלים שוברי סטיגמות בעניין יחס גודל-איכות, וככל שהמודל קטן יותר כך איכותו מפתיעה יותר ביחס לגודלו.- LFM 2 24B A2B: מודל MoE. המודל הגדול ביותר במשפחה, אך רץ במהירות גבוהה במיוחד בשל העובדה שרק 2B מהפרמטרים פעילים עבור כל טוקן. בעל יעילות קיצונית לריצה מהירה על מחשבים עם RAM מספק.
- LFM 2 8B A1B: מודל MoE. מתאים להרצה על מחשבים סטנדרטיים, במהירות גבוהה מאוד בשל העובדה שרק 1B מהפרמטרים פעילים עבור כל טוקן.
- LFM 2 2.6B: המודל הצפוף הגדול ביותר במשפחה. בעל איכות מפתיעה וידע עולם רב, בניגוד למודלים אחרים בגודלו. המודל עובר במדדים אף מודלים הגדולים ממנו פי כמה וכמה. מהיר מאוד בשל הארכיטקטורה ה"נוזלית" המיוחדת שלו. קיימת גרסת Exp ניסיונית שאף מאיצה עוד יותר את ההסקה.
- LFM 2 VL 3B: מודל ראיה המבוסס על מודל ה-2.6B, המצטיין ביכולות ראיה גבוהות במיוחד ביחס לגודלו, ובמהירות גבוהה במיוחד.
- LFM 2.5 1.2B Instruct\Thinking: מודל בעל איכות גבוהה ויכולת היגיון מפתיעה. מהיר מאוד גם ביחס לגודלו. נחשב למודל הטוב ביותר בפער סביב טווח הגודל של 1B. מגיע בשני גרסאות - חשיבה ותגובה מיידית, כשגרסת החשיבה מגיעה לביצועי היגיון גבוהים בדומה למודלים גדולים פי כמה.
- LFM 2.5 VL 1.6B: מודל ראיה המבוסס על מודל ה-1.2B, המצטיין ביכולות ראיה גבוהות במהירות עצומה.
- LFM 2 700M: מודל קטן ומהיר במיוחד, המותאם למשימות הדורשות ביצועים איכותיים ומהירים. מפתיע ביותר ביחס לגודלו.
- LFM 2.5 350M: המודל הקטן ביותר במשפחה, אך בעל הביצועים המפתיעים ביותר ביחס לגודלו. רץ במהירות שיא על כל חומרה, ומתאים למגוון רב של משימות.
- LFM 2.5 VL 450M: מודל ראיה המבוסס על מודל ה-350M, המצטיין ביכולות ראיה מפתיעות ביחס לגודלו במהירות שיא.
Llama
משפחת המודלים המיתולוגית מבית Meta, שהחלה את מהפכת ה-AI המקומי ב-2023 כשהודלף מודל ה-Llama הראשון, שלטה בתחום ללא עוררין למשך תקופה ארוכה, עד שהגיעה לקיצה ההיסטורי עם השקת מודלי Llama 4 המאכזבים. למרות זאת, מודלי המשפחה עדיין נחשבים לסטנדרט בתחומים רבים, ומהנוחים ביותר לעיצוב והתאמה אישית, ועדיין מככבים בראש רשימת ההורדות ב-Hugging Face. המודלים בסדרת Llama 4 גדולים יחסית ולכן לא הובאו כאן.- Llama 3.2 11B Vision Instruct: מודל מתקדם מדור קודם. בעל יכולות ראיה.
- Llama 3.2 3B Instruct: מודל קטן מדור קודם, המתאים למשימות רבות הדורשות מהירות גבוהה על חומרה חלשה.
- Llama 3.2 1B Instruct: מודל קטן במיוחד מדור קודם, אך עדיין אחד החכמים בטווח הגודל הזה. מתאים למשימות רבות הדורשות הרצה במהירות גבוהה במיוחד.
- Llama 3.1 8B Instruct: אמנם מודל יחסית ישן, אבל עדיין אחד המודלים שהורדו הכי הרבה פעמים מ-Hugging Face. נוח לשימוש והתאמה אישית.
Jamba
משפחת המודלים מבית AI21Labs הישראלית. המודלים מורכבים מארכיטקטורה היברידית המשלבת גם שכבות Transformer וגם שכבות Mamba (SSM).- AI21 Jamba Reasoning 3B: מודל קטן וחכם, עם יכולות חשיבה מתקדמות. בשל כך שרוב השכבות הן שכבות Mamba, ההסקה מהירה ברמה קיצונית. בעל יכולות היגיון חזקות. תומך בעברית.
- AI21 Jamba2 3B: הגרסה הקטנה בסדרה החדשה של המשפחה. לא כולל יכולות חשיבה, אך עדיין מציג תוצאות דומות למודל הקודם. מהירות גבוהה במיוחד. יכולות היגיון מפתיעות. תומך בעברית.
Phi
סדרת המודלים החכמים מבית מיקרוסופט. אומנו על מערכי נתונים מסוננים בקפידה, כמו ספרי לימוד ומידע סינטטי איכותי, ומהווים דוגמא לחשיבות איכות הנתונים על פני הכמות. מעולים לקידוד, מתמטיקה, היגיון ישר וידע עולם.- Phi-4: מודל 14B פרמטרים, הגדול ביותר בסדרה. מעולה לקידוד ומשימות היגיון מורכבות. תומך בעברית.
- Phi 4 Reasoning: מודל 14B פרמטרים בעל יכולות חשיבה מתקדמות, המבוסס על המודל הקודם. תומך בעברית.
- Phi 4 Reasoning Plus: גרסה משופרת של Phi 4 Reasoning שעברה למידת חיזוק. מספקת תשובות מדויקות ואיכותיות יותר, אך חושבת הרבה יותר, ולכן המודל מתאים למקרי שימוש המעדיפים איכות על פני מהירות. תומך בעברית.
- Phi 4 Multimodal Instruct: מודל מולטי מודאלי של 5.6B פרמטרים התומך בקלט טקסט, תמונה ואודיו. תומך בעברית.
- Phi 4 Mini Instruct: מודל קטן בעל 3.8B פרמטרים. מעולה למשימות הדורשות היגיון ישר וכסייען קידוד מהיר במיוחד. תומך בעברית.
- Phi 4 Mini Reasoning: מודל 3.8B פרמטרים בעל יכולות חשיבה מתקדמות, המבוסס על המודל הקודם. תומך בעברית.
- Phi 4 Mini Flash Reasoning: גרסה מהירה עד פי 10 מהמודל הקודם, תוך שמירה על אותה איכות, ע"י שימוש בארכיטקטורת SambaY המשלבת שכבות Mamba וטכנולוגיות נוספות, לעומת המודל הרגיל המבוסס על טרנספורמר קלאסי.
DeepSeek
משפחת המודלים הפתוחים של DeepSeek הסינית. המודלים הרלונטיים לכאן הם מודלים שזוקקו מהמודל הגדול של החברה - DeepSeek R1 685B. מודלים המתייחדים ביכולות חשיבה עמוקה וביצועים גבוהים תוך שימוש בחומרה צרכנית.- DeepSeek R1 Distill Qwen 32B: מודל חשיבה גדול המציג ביצועים מרשימים במדדים שונים. מבוסס על המודל המקביל מסדרת Qwen 2.5, שזוקק ממודל DeepSeek R1 הגדול. הכי קרוב לביצועי מודל המקור, ונחשב ספינת הדגל של המשפחה להרצה ביתית. תומך בעברית.
- DeepSeek R1 Distill Qwen 14B: מבוסס על המודל המקביל מסדרת Qwen 2.5. האיזון המושלם. חזק משמעותית בחשיבה מעמיקה, קידוד ומתמטיקה מגרסאות ה-8B.
- DeepSeek R1 Distill Llama 8B: מבוסס על המודל המקביל מסדרת Llama 3. בחירה אידיאלית למי שמעדיף את הסגנון ה"שיחתי" של מטא, אך זקוק לחשיבה עמוקה ולוגיקה משופרת.
- DeepSeek R1 Distill Qwen 7B: מבוסס על המודל המקביל מסדרת Qwen 2.5, עם יכולות חשיבה מעמיקה.
- DeepSeek R1 Distill Qwen 1.5B: מבוסס על המודל המקביל מסדרת Qwen 2.5. מותאם למשימות הדורשות חשיבה עמוקה על חומרה חלשה במיוחד.
- DeepSeek R1 0528 Qwen3 8B: הזיקוק של הגרסה המשופרת 0528 של מודל DeepSeek R1 הגדול. מבוסס על המודל המקביל מסדרת Qwen 3.
- DeepSeek OCR 2: מודל OCR מתקדם בעל 3B פרמטרים. תומך בעברית.
EuroLLM
משפחת מודלים רב-לשונית של חברת UTTER האירופית, הממומנת ע"י האיחוד האירופי ופותחה ע"י האוניברסיטאות היוקרתיות ביותר של אירופה. מטרת החברה הייתה לאמן מודלים בעלי יכולות מתקדמות בכל שפות האיחוד האירופי ושפות נפוצות אחרות.- EuroLLM 22B Instruct 2512: המודל הגדול במשפחה. בעל יכולות חזקות מאוד בכל השפות הרבות הנתמכות.
- EuroLLM 9B Instruct 2512: האיזון המשלם למהירות ויכולות לוגיות מורכבות. בעל יכולות היגיון חזקות מאוד גם לשפות פחות נפוצות.
- EuroMoE 2.6B A0.6B Instruct 2512: מודל MoE עם 0.6B פרמטרים פעילים בלבד עבור כל טוקן. מהיר מאוד, וחזק ביכולות רב-לשוניות. מאפשר גם לבעלי חומרה חלשה לחקור מודלי MoE, ונחשב למודל ה-MoE הרשמי הקטן ביותר. מתאים למשימות תרגום מהירות בין שפות רבות.
- EuroLLM 1.7B Instruct: מודל קטן ומהיר, בעל יכולות רב לשוניות חזקות. די מיושן אך עדיין בעל יכולות בלעדיות בתחומים מסויימים בשפות פחות נפוצות.
GLM
משפחת המודלים של חברת Z.ai הסינית. כיום החברה עברה להתמקד במודלי על עוצמתיים המתחרים במודלים המערביים הגדולים, כדוגמת GLM 5.1 שעוקף במדדי הביצועים את רוב מודלי העל המערביים, ופחות במודלים בינוניים וכמעט שלא מתעסקת במודלים קטנים. בכל זאת, המודלים הקטנים והבינוניים שכן שוחררו על ידי החברה עדיין ניצבים בחזית הביצועים המקומיים.- GLM 4.7 Flash: מודל MoE של 30B A3B (3B פרמטרים פעילים עבור כל טוקן). המודל הבינוני הטוב ביותר של החברה עד כה. בעל יכולות חשיבה עמוקה מתקדמות, ועוקף במדדי הביצועים מודלים הגדולים ממנו פי עשרה ויותר, ובמקביל מהיר במיוחד בשל ארכיטקטורת ה-MoE החדשנית.
- GLM 4.6V Flash: מודל 9B פרמטרים בעל יכולות ראיה מתקדמות, עם חשיבה מעמיקה. אחד ממודלי הראיה החזקים ביותר, ומתאים למשימות הדורשות שילוב של יכולות ראיה אמינות והיגיון ישר.
- GLM Edge 4B Chat: מודל קטן שנועד לרוץ על חומרת קצה. די מיושן אך בעל יכולות חזקות מאוד ומתאים למשימות הדורשת אמינות ויציבות במהירות גבוהה.
- GLM Edge V 5B: מודל ראיה המבוסס על המודל הקודם.
- GLM Edge 1.5B Chat: מודל קטן במיוחד להרצה על חומרת קצה חלשה. אמנם די מיושן, אבל עדיין בעל יכולות מרשימות יחסית לגודלו.
- GLM Edge V 2B: מודל ראיה המבוסס על המודל הקודם.
Falcon
משפחת המודלים מבית חברת TII (Technology Innovation Institute) האמירתית, הממומנת ע"י הממשלה האמירתית. במשפחה ישנם גם מודלים קטנים מאוד המתאימים לחומרה חלשה במיוחד.- Falcon H1 34B Instruct: ספינת הדגל של המשפחה. מודל חזק ועוצמתי בעל יכולות היגיון ישר ומתמטיקה חזקות.
- Falcon H1 7B Instruct: האיזון המושלם לביצועים איכותיים במהירות גבוהה.
- Falcon H1R 7B: גרסת חשיבה עמוקה של המודל המקורי. מתאימה למקרי שימוש בדורשים חשיבה חזקה ומהירות.
- Falcon H1 3B Instruct: מודל קטן אך חזק מאוד יחסית לגודלו, לביצועים מהירים במיוחד.
- Falcon H1 1.5B Instruct: מודל קטן מאוד אך בעל יכולות מרשימות, למשימות הדורשות מהירות גבוהה.
- Falcon H1 1.5B Deep Instruct: גרסה עמוקה יותר של המודל הקודם, עם ביצועים מעט איטיים יותר אך איכותיים בהרבה, למקרי שימוש הדורשים איכות גבוהה יותר ופחות מהירות.
- Falcon H1 0.5B Instruct: מודל קטן במיוחד אך חזק מאוד, לביצועים מהירים במיוחד אך איכותיים.
- Falcon H1 Tiny R 0.6B: מודל חשיבה מעמיקה המותאם לחומרה חלשה במיוחד. בעל יכולות היגיון חזקות מאוד יחסית לגודלו.
- Falcon H1 Tiny 90M Instruct: מודל זעיר במיוחד המסוגל לרוץ אפילו על חומרה חלשה ביותר, הצורך רק כ-55MB זיכרון RAM בכימות 4 ביט. בעל יכולות מרשימות מאוד ביחס לגודלו. נחשב למודל הקטן ביותר המפיק פלט איכותי וקוהרנטי.
- Falcon H1 Tiny R 90M: מודל חשיבה מעמיקה זעיר במיוחד לחומרה חלשה. נועד לאפשר יכולות חשיבה מעמיקה וקוהרנטית גם על חומרה חלשה באופן קיצוני. נחשב למודל החשיבה הקטן ביותר המפיק פלט איכותי וקוהרנטי.
- Falcon H1 Tiny Coder 90M: מודל קידוד זעיר לחומרה חלשה, המבוסס על המודל המקורי.
- Falcon H1 Tiny Tool Calling 90M: מודל קריאה לכלים זעיר לחומרה חלשה, המבוסס על המודל המקורי.
- Falcon OCR: מודל OCR של 300M פרמטרים. דוחף את גבולות ה-OCR על חומרה חלשה במיוחד.
על משפחות המודלים הבאות אפרט בעדכונים הבאים למדריך:
Granite
Exaone
Mistral
SmolLM
Nanbeige4
VibeThinker
Ernie
Maincoder
אז תכל'ס, איזה מודל הכי מתאים להריץ על החומרה שלי? (מתעדכן!)
תוכנת הסקה
עבור מחשבי Windows, התוכנה המומלצת כיום להרצת מודלים מקומיים היא LM Studio, בשל גמישותה הרבה והשליטה המלאה שהיא מאפשרת על תהליך ההסקה. ניתן להיעזר כאמור במדריך של @חובבן-מקצועי להרצת מודלים בתוכנה.
עבור מכשירי Android, האפליקציות המומלצות הן PocketPal AI עבור אמינות ויציבות לשימוש יומיומי, Off Grid לשימוש מתקדם בכלים וכדומה, Google AI Edge Gallery עבור ניצול מלא של יכולות Gemma 4 וסקירת התפתחות ה-AI, ו-MNN Chat להשגת ביצועי הסקה במהירות שיא.
מודל מומלץ
עבור חומרה עם 32 RAM: לשימוש כללי ומהיר המודל המומלץ הוא Gemma 4 26B A4B, ולקידוד מהיר Qwen 3.5 35B A3B. אם קיים GPU חזק, המהירות תשתפר ללא היכר.
עבור חומרה עם 16 RAM: לצרכי קידוד חכמים - בעיקרון המודל המומלץ הוא Qwen 3.5 9B או הגרסה המכווננת שלו OmniCoder 9B, אבל מדובר במודלים יחסית כבדים לחומרה כזאת שמצריכים סגירה של שאר התוכנות, ולכן מומלץ להשתמש לקידוד ב-Qwen 3.5 4B או בגרסה המכווננת שלו Qwopus 3.5 4B. לשימוש כללי - Gemma 4 E4B. אם קיים GPU חזק, ניתן להעביר כמה שיותר שכבות ל-GPU לעיבוד מהיר בהרבה.
עבור חומרה עם 8 RAM: עבור קידוד מומלץ להשתמש ב-Qwen 3.5 4B או בגרסה המכווננת שלו Qwopus 3.5 4B. לשימוש כללי - Gemma 4 E2B.
עבור חומרה עם 6 RAM: לשימוש כללי מומלץ להשתמש ב-Gemma 4 E2B. שימוש לקידוד פחות רלוונטי בדרך כלל בחומרה כזאת, אבל ניתן להסתייע ב-Qwen 3.5 4B או בגרסה המכווננת שלו Qwopus 3.5 4B.
עבור חומרה עם 4 RAM: לשימוש כללי בעברית מומלץ להשתמש ב-DictaLM 3.0 1.7B Instruct\Thinking, או ב-AI21 Jamba2 3B, או ב-Tiny Aya Global 3.35B. לשימוש חכם יותר אך ללא עברית מומלץ להשתמש ב-LFM 2 2.6B או LFM 2.5 1.2B Instruct\Thinking, או ב-Qwen 3.5 Claude 4.6 Opus Reasoning Distilled 2B (הכוונון של המודל המקורי, מונע לולאות חשיבה אינסופית בגודל הזה).
עבור חומרה עם 3 RAM: לשימוש כללי בעברית מומלץ להשתמש ב-DictaLM 3.0 1.7B Instruct\Thinking. ניתן לנסות להשתמש ב-AI21 Jamba2 3B - מודל מהיר במיוחד, אך ייתכנו קריסות אם ה-RAM צפוף. לשימוש חכם יותר אך ללא עברית מומלץ להשתמש ב-LFM 2.5 1.2B Instruct\Thinking, או ב-Qwen 3.5 Claude 4.6 Opus Reasoning Distilled 2B\0.8B (הכוונון של המודל המקורי, מונע לולאות חשיבה אינסופית בגודל הזה).
עבור חומרה עם 2 RAM: אין כיום מודלים טובים בעברית לחומרה זו. לשימוש ללא עברית מומלץ להשתמש ב-Qwen 3.5 Claude 4.6 Opus Reasoning Distilled 0.8B (הכוונון של המודל המקורי, מונע לולאות חשיבה אינסופית בגודל הזה), או ב-LFM 2 700M, או ב-LFM 2.5 350M לשימוש מהיר במיוחד.
עבור חומרה עם 1 RAM ומטה: אין כיום מודלים טובים בעברית לחומרה זו. לשימוש ללא עברית מומלץ להשתמש ב-LFM 2.5 350M, או ב-Gemma 3 270M, או ב-Falcon H1 Tiny 90M Instruct.
מקווה שהמדריך הזה יועיל ויחסוך שאלות מיותרות.
אם משתמש נתקל בתקלות ובעיות בהרצת מודלים, אפשר לשאול כאן או באישי, ואם אחשוב שזה עשוי להועיל לציבור אוסיף את התקלה ופתרונה למדריך.
אשמח לקבל משוב בתגובות והצעות לשיפור המדריך!
-
-
@א.מ.ד. וואו! כל הכבוד!
- יצא לי לראות עוד סיומת של מודלים, Safetensors. יש שינויים לגביו?
- מורכב להתקין ולחבר את openclow? (בכללי נראה לי שסוכן מקומי זה עניין למדריך נפרד, זורק רעיון...
 )
)
@דאבל כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
יצא לי לראות עוד סיומת של מודלים, Safetensors. יש שינויים לגביו?
זה מודל מקורי בלי המרה ודחיסה, שלא נוח להריץ מקומית.
@דאבל כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
מורכב להתקין ולחבר את openclow?
יחסית מורכב, בפרט באינטרנט מסונן.
@דאבל כתב במדריך | מודלי AI מקומיים - מדריך וסקירה מקיפים למודלים קטנים ויעילים - מתעדכן.:
(בכללי נראה לי שסוכן מקומי זה עניין למדריך נפרד, זורק רעיון... )
רעיון...
-
@א.מ.ד. @חובבן-מקצועי הורדתי
Qwen3.5-4B.Q4_K_M.ggufושמתי בתיקייהC:\Users\ADMIN\.lmstudio\models\Qwen3.5-4B,בתוכנה מוגדר לקחת את כך

ובפועל כשאני בא לבחור מדל אין לי שום מודל ברשימה,
העברתי את קובץ ה-gguf לתיקייהmodelsוזה לא עזר -
@CUBASE בעיקרון (לא ניסיתי בעצמי כמו שכתבתי כבר, אבל מהערות של משתמשים אחרים) צריך להכניס לעוד תקיה בתוך המודלוס,
ובכל מקרה תמיד יש את האופציה של בחירה ידנית.
כל זה אם הבנתי נכון וכוונתך אכן לLM סטודיו.

 { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}