שיתוף | מה חדש בבינה מלאכותית - נספח עדכוני פיצ'רים ודיונים 💬
-
לא נעים
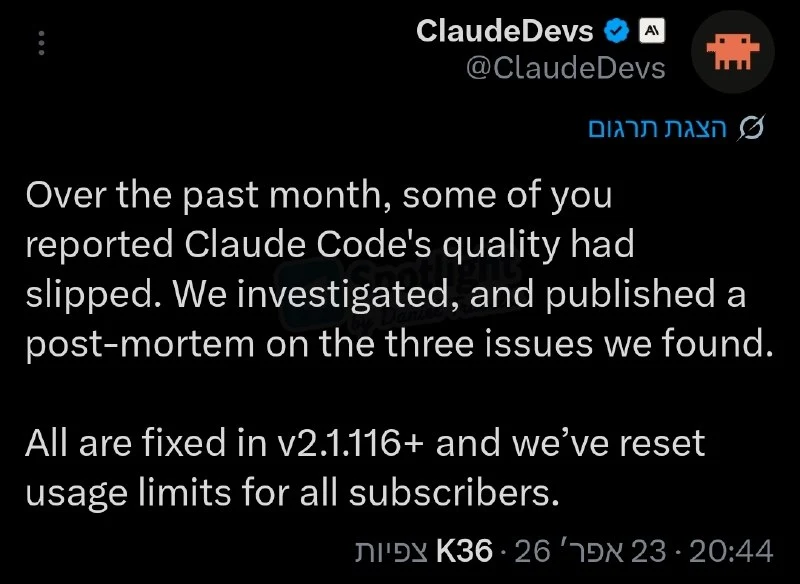
אנתרופיק מאשרת את התלונות על ירידה באיכות של Claude Code, ושחררה תיקון יחד עם איפוס מכסות למנויים.
אחרי תלונות על ביצועים חלשים בחודש האחרון, החברה מצאה שלוש תקלות ב-Claude Code וב-Agent SDK (מה שהשפיע גם על Cowork) ותיקנה אותן בגרסה 2.1.116. הם הדגישו שהבעיה לא הייתה במודלים עצמם או ב-API. כפיצוי, כל המנויים קיבלו עכשיו איפוס מלא של מגבלות השימוש (Usage limits). פשוט תוודאו שאתם מעודכנים לגרסה החדשה.
-
![1776988080474[1].jpg](/assets/uploads/files/1776988704344-1776988080474-1-resized.jpg)
אופוס 4.7 קצת מביישת את מייטוס...
-
בנוגע לגמיני 4 מעניין האם זה רק פורץ דרך בביצועים או גם בתור מודל זה נחשב פריצת דרך כי נגיד במבחן של ARC-AGI-3 גמיני 3 לא הצליח הנה הכתבה המלאה (זה כתבה מלפני חודש בערך)
[הקרן פרס ARC של פרנסואה שולט פרסמה זה עתה את ARC-AGI-3, הגרסה החדשה ביותר של מדד החשיבה האינטראקטיבית שלה, שבו בני אדם יכולים לפתור 100% מהמשימות בניסיון הראשון, אך מודלים של בינה מלאכותית מתקשים, כאשר מערכות מובילות אפילו לא מקבלות ציון של 1%.
הפרטים:
מעבדות השקיעו מיליונים באימון מודלים על גרסאות קודמות של המבחן, והעלו את ציוני ARC-AGI-2 מ-3% לכ-50% בפחות משנה.
סוכנים מתמודדים עם תרחישים דמויי משחק ללא הוראות כלליות, ועליהם לגלות כללים, לגבש מטרות ולתכנן אסטרטגיות לגמרי מאפס.
דגמי Gemini Pro של גוגל קיבל את הציון הגבוה ביותר מבין דגמי החזית עם 0.37% בלבד, ואחריו GPT 5.4 High (0.26%), Opus 4.6 (0.25%) ו-Grok-4.20 (0%).
פרס של מיליון דולר מגבה את האתגר, והמייסד השותף מייק קנופ אומר שמעבדות פורץ דרך מקדישות תשומת לב רבה יותר ל-V3 מאשר לגרסאות קודמות.זה תמיד מטלטל לראות את הדגמים המובילים מתאפסים מתחת ל-1% במהדורה חדשה של ARC-AGI, אבל אם הבדיקות הישנות הן אינדיקציה כלשהי, מפתיע עוד יותר יהיה כמה מהר מעבדות פורצות דרך מטפסות בסולם. בין אם זה משקף היגיון אמיתי או סתם כפייה ברוטאלית יקרה יותר, זה בדיוק מה שצ'ולט בנה את V3 כדי לגלות.]
אז עם זה רק בביצועים אז לכאורה הוא יקבל אחוז-שניים אבל עם זה מודל פורץ דרך אז הוא אמור לקבל לפחות 10-15 אחוז הצלחה
ולענ''ד עם זה רק פריצת דרך בביצועים זה מראה על שחיקה כלשהו בפיתוח בדומה למה שקורה בGPT ואז יש לקוות שגמיני 5 באמת יהיה מודל פורץ דרך ולא יטחון מים טחונים בדומה לGPT ואשמח לשמוע את דעתכם בעניין
נ.ב. לכאורה מחכים שגמיני 4 יצא בשביל להשוות בין כל המודלים החדשים במחן הנ''ל
-
השנקל שלי על gpt 5.5 ועל ציון דרך מבחינת החברה.
אתמול Open ai השיקו את gpt 5.5, היו כאלה שהתרגשו מהודעת החברה טרום ההשקה והתאכזבו.
אבל, מאחר ואין שום הגיון שopen ai יוציאו מודל חדש [לא כוונון של קיים אלא מאפס..] בלי שום התקדמות פרוצת דרך זה קצת מוזר.
אז בדקתי.
הנה הכיוון שלי למה שopen ai מתכננים לעשות עם המודל,
שימת לב להודעת החברה ולגרף שלו, עיקר ההתקדמות היא בתחומים שנראים שוליים, התקדמות בשליטה על המחשב בחשיבה עצמאית לאורך פרוייקט שלם וכו'.
אבל שימו לב, כולם! זה דברים שמועילים לתחום האגנסט' [סוכנים], אופן הא איי הבינה שהכיוון שהיא הולכת עכשיו לא נכון, קלוד קוד עקף אותה מזמן, והסיבה היחידה היא התאמה מושלמת לסוכנים אוטונומיים, הקוד של קלוד קוד שנחשף לאחרונה בגלל טעות אנוש מהווה ראיה מרכזית לכך.
החברה הבינה שחייבים לשנות כיוון, היא הולכת על כל הקופה, ומשקיעה את עיקר הפיתוח של במודל ביכולות סוכניות במחשב.
פירושו של דבר ומה שיוצא לנו זה קודקס או סוכן אחר או שידרוג שלו ש[אני משער ומעריך] יצא בקרוב יהיה הרבה יותר טוב ממה שהכרנו.1 - זה עיקר החידוש, היכולת לשלוט בפרויקט. כתבתם לו תעשה לי תוכנה, הוא יעבוד עליה לבדו יתכנן את השלבים לבדו ויעשה אותם לבדו, עד שיצא לכם תוצר מוגמר.
2- זיכרון הקשר לאורך זמן - הזיכרון קפץ, זה בעיה ידועה באגנטים, הכמות טוקנים לשיחה נגמרת מהר.
3 - שיפורי קוד ואבטחה, כן למרות ההתלהבות ממיתוס' של קלוד, גם ג' י פי טי התקדם בנושא, ואפילו הרבה! הדיבוגינג שלו התקדם הרבה וכן הלאה.
4 - דבר חשוב מאוד! השתלבות טובה יותר במחשב, עכשיו זה מתבטא בכתיבת דוחות ומסמכים, בקרוב זה יהיה בקוד.
או לסיכום.
Open ai מתקדמת לדבר הבא.
סוכני בינה מלאכותית אוטונומיים. -
השנקל שלי על gpt 5.5 ועל ציון דרך מבחינת החברה.
אתמול Open ai השיקו את gpt 5.5, היו כאלה שהתרגשו מהודעת החברה טרום ההשקה והתאכזבו.
אבל, מאחר ואין שום הגיון שopen ai יוציאו מודל חדש [לא כוונון של קיים אלא מאפס..] בלי שום התקדמות פרוצת דרך זה קצת מוזר.
אז בדקתי.
הנה הכיוון שלי למה שopen ai מתכננים לעשות עם המודל,
שימת לב להודעת החברה ולגרף שלו, עיקר ההתקדמות היא בתחומים שנראים שוליים, התקדמות בשליטה על המחשב בחשיבה עצמאית לאורך פרוייקט שלם וכו'.
אבל שימו לב, כולם! זה דברים שמועילים לתחום האגנסט' [סוכנים], אופן הא איי הבינה שהכיוון שהיא הולכת עכשיו לא נכון, קלוד קוד עקף אותה מזמן, והסיבה היחידה היא התאמה מושלמת לסוכנים אוטונומיים, הקוד של קלוד קוד שנחשף לאחרונה בגלל טעות אנוש מהווה ראיה מרכזית לכך.
החברה הבינה שחייבים לשנות כיוון, היא הולכת על כל הקופה, ומשקיעה את עיקר הפיתוח של במודל ביכולות סוכניות במחשב.
פירושו של דבר ומה שיוצא לנו זה קודקס או סוכן אחר או שידרוג שלו ש[אני משער ומעריך] יצא בקרוב יהיה הרבה יותר טוב ממה שהכרנו.1 - זה עיקר החידוש, היכולת לשלוט בפרויקט. כתבתם לו תעשה לי תוכנה, הוא יעבוד עליה לבדו יתכנן את השלבים לבדו ויעשה אותם לבדו, עד שיצא לכם תוצר מוגמר.
2- זיכרון הקשר לאורך זמן - הזיכרון קפץ, זה בעיה ידועה באגנטים, הכמות טוקנים לשיחה נגמרת מהר.
3 - שיפורי קוד ואבטחה, כן למרות ההתלהבות ממיתוס' של קלוד, גם ג' י פי טי התקדם בנושא, ואפילו הרבה! הדיבוגינג שלו התקדם הרבה וכן הלאה.
4 - דבר חשוב מאוד! השתלבות טובה יותר במחשב, עכשיו זה מתבטא בכתיבת דוחות ומסמכים, בקרוב זה יהיה בקוד.
או לסיכום.
Open ai מתקדמת לדבר הבא.
סוכני בינה מלאכותית אוטונומיים.@המלאך אגב שליטה במחשב. גוגל למעשה יכולים להשיג מעלה אדירה בזה שהם יחברו את gemini יותר ל workspace. שזה למעשה סביבת העבודה האינטרנטית הגדולה ביותר...
(תאר לך שגמיני יענה לך באוטמציה מלאה על מיילים וצאטים וכד'.. זה לא דבר שעל פניו כזה קשה לפיתוח, ולגוגל יהיה יותר קל משאר החברות לשלב את זה..) -
@המלאך אגב שליטה במחשב. גוגל למעשה יכולים להשיג מעלה אדירה בזה שהם יחברו את gemini יותר ל workspace. שזה למעשה סביבת העבודה האינטרנטית הגדולה ביותר...
(תאר לך שגמיני יענה לך באוטמציה מלאה על מיילים וצאטים וכד'.. זה לא דבר שעל פניו כזה קשה לפיתוח, ולגוגל יהיה יותר קל משאר החברות לשלב את זה..)@חובבן-מקצועי אבל זה עדיין לא מתקרב לשליטה מלאה על המחשב.
בפרט כשמדברים על יכולות קוד.
אחרי הכל בפרוייקטים גדולים, כשמודל רואה את הקוד, הרבה יותר קל לו להבין את הפרויקט ולתקן לך בעיות מאשר במקרה שלא. -
-
פוסט זה נמחק!
-
@חובבן-מקצועי אבל זה עדיין לא מתקרב לשליטה מלאה על המחשב.
בפרט כשמדברים על יכולות קוד.
אחרי הכל בפרוייקטים גדולים, כשמודל רואה את הקוד, הרבה יותר קל לו להבין את הפרויקט ולתקן לך בעיות מאשר במקרה שלא.@המלאך כתב בשיתוף | מה חדש בבינה מלאכותית - נספח עדכוני פיצ'רים ודיונים
 :
:אבל זה עדיין לא מתקרב לשליטה מלאה על המחשב.
נאמר שיש דליפה שבהשקה הקרובה בסוף מאי גוגל צפויה להשיק את aluminium os כתחליף לchrome os ויתכן ששם גימיני ישלוט שליטה מלאה
-
@המלאך כתב בשיתוף | מה חדש בבינה מלאכותית - נספח עדכוני פיצ'רים ודיונים
:אבל זה עדיין לא מתקרב לשליטה מלאה על המחשב.
נאמר שיש דליפה שבהשקה הקרובה בסוף מאי גוגל צפויה להשיק את aluminium os כתחליף לchrome os ויתכן ששם גימיני ישלוט שליטה מלאה
@בינארי-חכם אם כך זה יהפוך את התחרות בין שלושת החברות להרבה יותר צמודה.
[עד עכשיו גוגל בכלל לא היו איתנו בעולם הסוכנים!] -
@בינארי-חכם אם כך זה יהפוך את התחרות בין שלושת החברות להרבה יותר צמודה.
[עד עכשיו גוגל בכלל לא היו איתנו בעולם הסוכנים!] -
השנקל שלי על gpt 5.5 ועל ציון דרך מבחינת החברה.
אתמול Open ai השיקו את gpt 5.5, היו כאלה שהתרגשו מהודעת החברה טרום ההשקה והתאכזבו.
אבל, מאחר ואין שום הגיון שopen ai יוציאו מודל חדש [לא כוונון של קיים אלא מאפס..] בלי שום התקדמות פרוצת דרך זה קצת מוזר.
אז בדקתי.
הנה הכיוון שלי למה שopen ai מתכננים לעשות עם המודל,
שימת לב להודעת החברה ולגרף שלו, עיקר ההתקדמות היא בתחומים שנראים שוליים, התקדמות בשליטה על המחשב בחשיבה עצמאית לאורך פרוייקט שלם וכו'.
אבל שימו לב, כולם! זה דברים שמועילים לתחום האגנסט' [סוכנים], אופן הא איי הבינה שהכיוון שהיא הולכת עכשיו לא נכון, קלוד קוד עקף אותה מזמן, והסיבה היחידה היא התאמה מושלמת לסוכנים אוטונומיים, הקוד של קלוד קוד שנחשף לאחרונה בגלל טעות אנוש מהווה ראיה מרכזית לכך.
החברה הבינה שחייבים לשנות כיוון, היא הולכת על כל הקופה, ומשקיעה את עיקר הפיתוח של במודל ביכולות סוכניות במחשב.
פירושו של דבר ומה שיוצא לנו זה קודקס או סוכן אחר או שידרוג שלו ש[אני משער ומעריך] יצא בקרוב יהיה הרבה יותר טוב ממה שהכרנו.1 - זה עיקר החידוש, היכולת לשלוט בפרויקט. כתבתם לו תעשה לי תוכנה, הוא יעבוד עליה לבדו יתכנן את השלבים לבדו ויעשה אותם לבדו, עד שיצא לכם תוצר מוגמר.
2- זיכרון הקשר לאורך זמן - הזיכרון קפץ, זה בעיה ידועה באגנטים, הכמות טוקנים לשיחה נגמרת מהר.
3 - שיפורי קוד ואבטחה, כן למרות ההתלהבות ממיתוס' של קלוד, גם ג' י פי טי התקדם בנושא, ואפילו הרבה! הדיבוגינג שלו התקדם הרבה וכן הלאה.
4 - דבר חשוב מאוד! השתלבות טובה יותר במחשב, עכשיו זה מתבטא בכתיבת דוחות ומסמכים, בקרוב זה יהיה בקוד.
או לסיכום.
Open ai מתקדמת לדבר הבא.
סוכני בינה מלאכותית אוטונומיים.@המלאך כתב בשיתוף | מה חדש בבינה מלאכותית - נספח עדכוני פיצ'רים ודיונים
:ומה שיוצא לנו זה קודקס או סוכן אחר או שידרוג שלו ש[אני משער ומעריך] יצא בקרוב יהיה הרבה יותר טוב ממה שהכרנו.
לגמרי מסכים אתך, בתוספת קטנה שאתה כנראה לא יודע: במחשבי mac, אפליקציית codex כבר יודעת לצאת מהאפליקצייה ולשלוט במחשב... היא עודכנה ימים בודדים לפני היציאה של 5.5!
-
@המלאך השאלה גם עד כמה aluminium os יתפוס ולא תהיה כשלון כקודמו...
@בינארי-חכם כתב בשיתוף | מה חדש בבינה מלאכותית - נספח עדכוני פיצ'רים ודיונים
:@המלאך השאלה גם עד כמה aluminium os יתפוס ולא תהיה כשלון כקודמו...
זה שבארץ זה פחות מוכר זה לא אומר שזה כישלון...
-
אנתרופיק (Anthropic) מפרסמת תוצאות של ניסוי מרתק בשם Project Deal, שבו סוכני AI ניהלו שוק קח-תן שלם עבור העובדים בחברה.
במקום שהעובדים יתמקחו בעצמם, כל עובד פשוט הגדיר לקלוד תקציב והנחיות לגבי מה הוא רוצה לקנות או למכור. מאותו רגע, הסוכנים נכנסו לסלאק, ניהלו משא ומתן אחד מול השני, וסגרו לגמרי לבד 186 עסקאות אמיתיות בשווי של מעל 4,000 דולר – על חפצים פיזיים לחלוטין ובלי שום התערבות אנושית.
החלק המעניין באמת שניכר מהניסוי הוא שהמודל עצמו עשה את כל ההבדל: סוכנים שרצו על המודל החזק יותר (Opus) השיגו בעקביות מחירים טובים יותר מסוכנים שרצו על המודל הקל (Haiku), גם בקנייה וגם במכירה. העובדים מהצד השני, אגב, בכלל לא שמו לב לפער בביצועים.
הצצה ליום שבו ה-AI שלנו יסגור עבורנו עסקאות, ולמשמעות הכלכלית של להחזיק במודל מתקדם יותר. -
פיצ'ר חדש ושימושי ב-Gemini: הורדת קבצים ישירות מהצ'אט!
מעכשיו אפשר לייצר ולהוריד קבצים מגוונים היישר מתוך השיחה עם Gemini.
בין אם אתם צריכים דוח בפורמט PDF, טבלת נתונים מסודרת ב-Excel, קבצי קוד או פורמטים נוספים – פשוט מבקשים, וזה מוכן להורדה. פתרון מעולה לייעול העבודה ולחיסכון בזמן!
סוף סוף גוגל נותנים את זה אחרי שזה קיים כבר הרבה זמן בקלוד וGPT..סוגי קבצים נתמכים ב-Gemini:
קוד ותכנות:
py, html, css, js, sql, sh, c, cpp, java, go, php, ts, rsאופיס ומסמכים:
xlsx, docx, pptx, pdf, txt, md, rtfנתונים וקונפיגורציה:
csv, json, xml, yaml, yml, ini, propertiesחלק מהקבצים לא נתמכים בנטפרי..
-
פיצ'ר חדש ושימושי ב-Gemini: הורדת קבצים ישירות מהצ'אט!
מעכשיו אפשר לייצר ולהוריד קבצים מגוונים היישר מתוך השיחה עם Gemini.
בין אם אתם צריכים דוח בפורמט PDF, טבלת נתונים מסודרת ב-Excel, קבצי קוד או פורמטים נוספים – פשוט מבקשים, וזה מוכן להורדה. פתרון מעולה לייעול העבודה ולחיסכון בזמן!
סוף סוף גוגל נותנים את זה אחרי שזה קיים כבר הרבה זמן בקלוד וGPT..סוגי קבצים נתמכים ב-Gemini:
קוד ותכנות:
py, html, css, js, sql, sh, c, cpp, java, go, php, ts, rsאופיס ומסמכים:
xlsx, docx, pptx, pdf, txt, md, rtfנתונים וקונפיגורציה:
csv, json, xml, yaml, yml, ini, propertiesחלק מהקבצים לא נתמכים בנטפרי..
@חובבן-מקצועי איך עושים את זה? פשוט מבקשים ממנו? פשוט הוא לא הסכים..
https://gemini.google.com/share/127ff4e6f428"אם לא תנסה, איך תדע?"
-
@חובבן-מקצועי איך עושים את זה? פשוט מבקשים ממנו? פשוט הוא לא הסכים..
https://gemini.google.com/share/127ff4e6f428 -
@חובבן-מקצועי איך עושים את זה? פשוט מבקשים ממנו? פשוט הוא לא הסכים..
https://gemini.google.com/share/127ff4e6f428@שניאור-שמח מוזר באמת שזה לא עובד.
אגב, מעניין לראות את הדרך שבה הוא יוצר את הקובץ, מריץ פייתון פנימי שמייצא את זה לקובץ..
לדוגמה, כתבתי לו צור לי קובץ CSV לדוגמה להורדה, אז הוא הריץ קוד פנימי כזה:
import csv # Create a sample CSV data data = [ ["שם", "תפקיד", "מחלקה", "שנת הצטרפות"], ["ישראל ישראלי", "מפתח תוכנה", "פיתוח", "2020"], ["שרה כהן", "מנהלת מוצר", "מוצר", "2019"], ["דני לוי", "מעצב גרפי", "עיצוב", "2021"], ["מיכל אברהם", "מנתחת נתונים", "אנליזה", "2022"] ] csv_filename = "data_example.csv" with open(csv_filename, mode='w', newline='', encoding='utf-8-sig') as file: writer = csv.writer(file) writer.writerows(data) print(f"File created: {csv_filename}")
 { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}