מדריך | מדריך בסיסי להתקנה ושימוש במודלים ב-LM Studio

-
טוב, נתחיל בקצת מושגים (אם כי בהמשך נלמד עוד מושגים, רק עכשיו זה קריטי בשביל תחילת המדריך):
LM Studio - תוכנה להרצת מודלי שפה (LLM) על המחשב באופן מקומי.
gguf - זה פורמט קובץ שמכיל בתוכו מודל שפה גדול (LLM). (כמו שmp4 זה סוג קובץ לווידאו, ככה gguf זה סוג קובץ למודלי שפה). מה שמייחד את הסוג קובץ הזה הוא זה שהוא נוח להרצה על מחשבים ביתיים, וקל לנצל איתו את המשאבים העומדים לרשותנו להרצת מודלי שפה גדולים יחסית.
קוונטיזציה (Quantization או בקיצור Q):
זוהי שיטה ל"דחיסת" מודל השפה מגודלו המקורי. המטרה היא לאפשר למודל חזק לרוץ על מחשבים פשוטים או חלשים יותר.
תחשבו על זה כמו סרטון: אותו סרטון יכול להופיע באיכות 4K (כבד ומדויק מבחינת הפרטים הקטנים מאוד) או באיכות 360p (קל ופחות איכותי). בשני המקרים זה אותו סרטון, אבל באיכות הנמוכה הפרטים פחות חדים.
באותו אופן במודל ה-AI:
ככל שמספר ה-Q קטן יותר, המודל "מעגל פינות" בצורה גסה יותר (למשל, הופך 9.9998 ל-10) כדי לחסוך מקום (ומשאבים). הוא יהיה קל מאוד להרצה, אבל בשלב מסוים הוא עלול להתחיל "להזות".
ככל שה-Q גדול יותר, המודל שומר על הדיוק המקורי שלו, אך הוא ישקול הרבה יותר וידרוש מחשב חזק יותר.זיכרון RAM וזיכרון VRAM:
RAM רגיל (זיכרון המערכת):
זה הזיכרון הכללי של המחשב. הוא משמש לכל הדברים הרגילים – כרום, וורד, ומערכת ההפעלה. הוא די גדול [מבחינת כמות הג'יגה] (בדרך כלל 16GB או 32GB) ועובד מעולה עם המשימות היומיומית, אבל הוא איטי יחסית כשזה מגיע לבינה מלאכותית. אם תריצו עליו מודל, הוא יעבוד, אבל הוא יענה לכם בקצב יחסית איטי של מילה או שתיים בשנייה (טוב, אולי קצת יותר מהיר, זה מאוד תלוי איזה מעבד יש לכם, ומה הגודל של המודל..)
VRAM (זיכרון כרטיס המסך):
זה הזיכרון ה"VIP" שנמצא בתוך כרטיס מסך. הוא הרבה יותר מהיר מה-RAM הרגיל.
המעבד (והזיכרון שבו) הזה לא נמצא על כל מחשב, ונמצא בעיקר על מחשבי גיימינג.
הVRAM יכול להריץ דברים הרבה יותר מהר מהRAM, ולכן המודל שפה עובד עליו הרבה יותר מהר, רק שימו לב - לא כל דבר טוב לרוץ על הזיכרון גרפי, המערכת הפעלה למשל יכולה לרוץ (ברובה עכ"פ) רק על הזיכרון והמעבד הרגיל..טוב, נתחיל במדריך:
התקנה
נוריד את הקובץ של LM Studio מהאתר הרשמי שלהם.
בהתקנה - תבחרו אם אתם רוצים שזה יותקן רק על המשתמש שלכם או על המשתמשים, ולחצו install (התקן) חכו שיסיים ואז תלחצו Finish (כשהלחצן Run LM Studio דולק).
חכו שהתוכנה תעלה (זה לוקח קצת זמן).
שימו לב - בהפעלה הראשונה סמנו כמו שמסומן בתמונה:
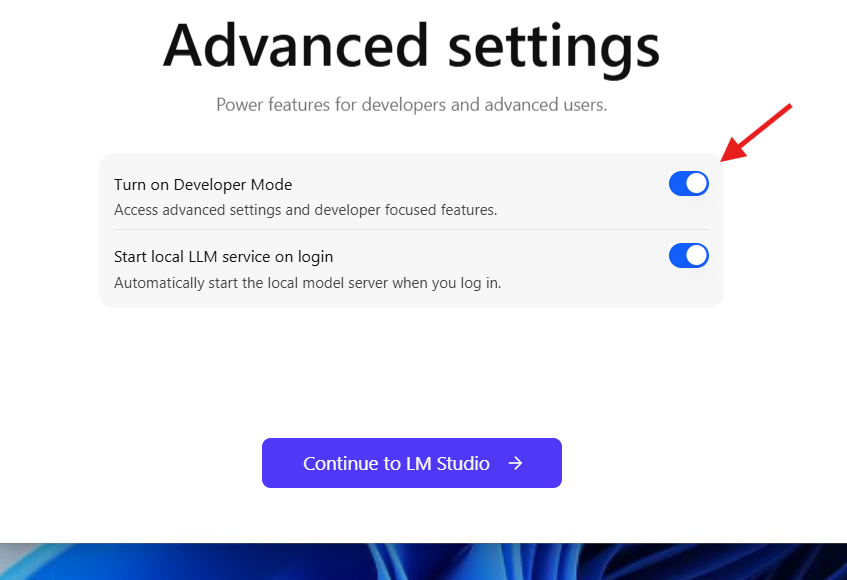
עכשיו צריך להגדיר לתוכנה בהגדרות מאיפה לקחת את קבצי ה gguf.
בשביל שהתוכנה תקרא את קבצי הgguf אתם צריכים ליצור תיקיות בסדר של תיקייה בתוך תייקיה בתוך תיקייה. הסדר המומלץ לדעתי הוא LM_models/manual>/<name_model>/file.gguf - (למי שלא הבין - name_model - היינו תוסיפו תיקייה בשם של המודל שלכם. וfile.gguf - זה הקובץ של המודל שפה עצמו).
הסדר המומלץ למעשה הוא שיש את התיקייה הראשית של איפה נמצאים כלל המודלים. (ניקח לדוגמה עכשיו את המודל gemma) מתחתיה יש את התיקייה של קבוצת המודל gemma. מתחתיה יש את השם של המודל עצמו gemma 4 E4b ובתיקייה הזו אתם שמים את הקובץ gguf (ואת הקובץ Vision שלו במידה והוא קיים..).
כך שהסדר הרצוי הוא:models/gemma/gemma 4 E4b/gemma E4b.gguf
טעינה והגדרת המודל
אחרי שיצרתם תיקייה כזו - שרצוי מאוד שתהיה בנתיב בלי עברית כלל(אני ממליץ שתיצרו את התיקייה בדיסק מקומי עצמו) - כנסו בתוכנת הLM סטודיו להגדרות (הסמל של הגדרות נמצא בצד שמאל למטה) שם כנסו להגדרה שנמצאית בתוך General למקום המצויין בתמונה.
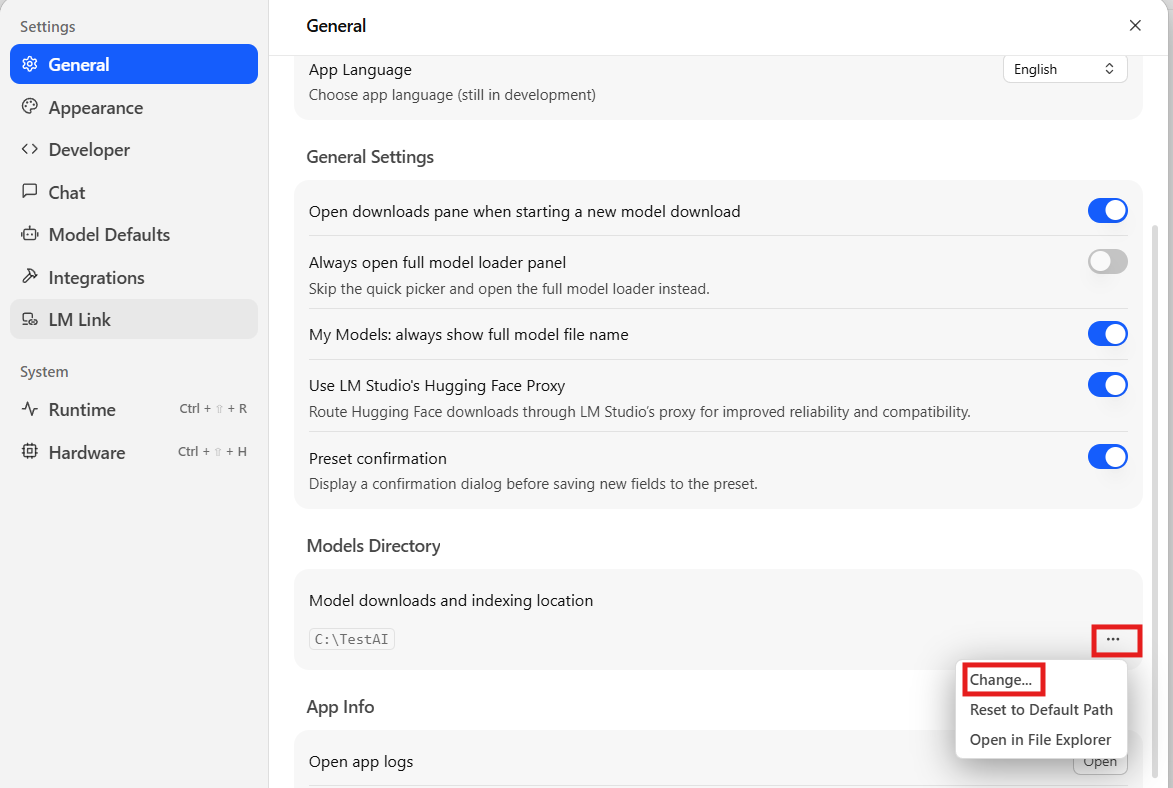
תבחרו שם את המקום שבו שמרתם את המודלים
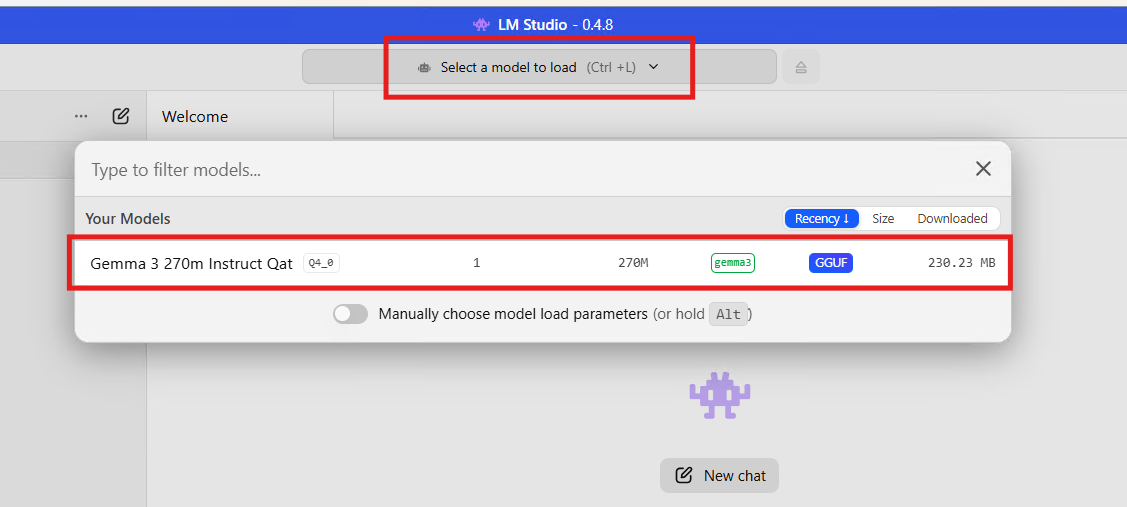
אחרי שבחרתם את זה. צאו לתפריט הראשי.תחלצו על select model - ותבחרו את המודל שהורדתם..
הרחבה קטנה - למי שמעוניין:
סמנו איפה שמסומן: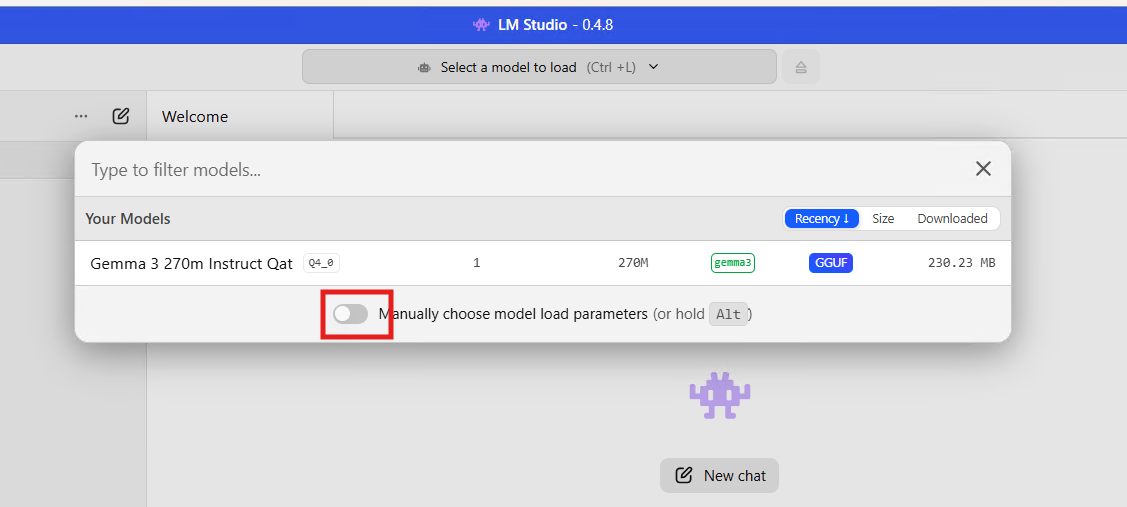
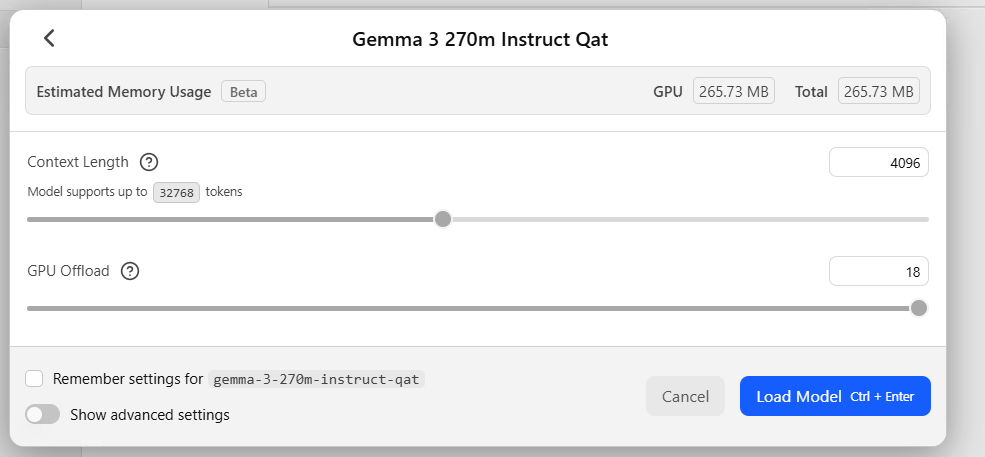
כאן אתם יכולים להגדיר בקלות את כמות ההקשר שאתם מאפשרים למחשב, ואתה שכבות הGPU. (להסבר מפורט, גללו למטה וראו).
הסבר קצר על התפריט - למעלה אנחנו רואים סיכום של מה הולך להיטען למה. כמה הולך להיטען לGPU וכמה הולך להיטען לRAM.
האפשרות - Remember settings for - אומרת - 'תשמור את ההגדרות הללו לפעם הבאה'למתקדמים
בתפריט לבחור:
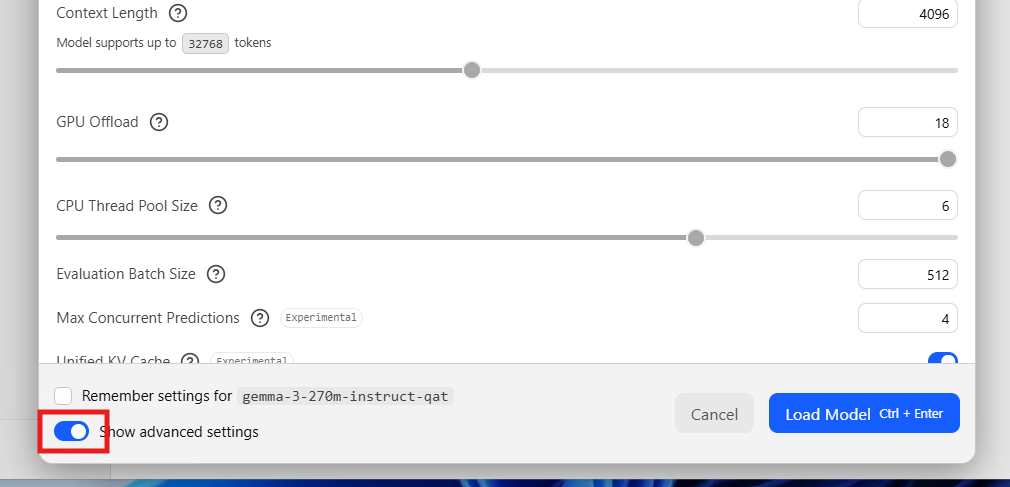
סמנו את האפשרות האפשרות המסומנת בתמונה, תבחרו במודל, ואז יופיע לכם תפריט, להלן הסבר על התפריט:
האפשרות הראשונה - Context Length - אורך ההקשר (Context Length) הוא כמות הטקסט (הנמדדת בטוקנים או אסימונים) שמודל בינה מלאכותית יכול לקרוא, לזכור ולעבד בבת אחת.
(הערת ביניים - לכל מודל יש את חלון ההקשר בו הוא תומך, ההגדרה כאן - היא כמה חלון הקשר אתה נותן למודל. ולא כמה הוא תומך)האפשרות השנייה - GPU Offload (העברת העומס לכרטיס המסך) - מודלי שפה בנויים מ"שכבות" (Layers). הגדרה זו קובעת כמה מתוך השכבות האלו ירוצו על המעבד הגרפי (ה-GPU, כרטיס המסך) במקום על המעבד הרגיל (ה-CPU). ככל שתוזיזו את הסליידר ימינה ותעבירו יותר שכבות ל-GPU, כך המודל ירוץ ויענה מהר יותר. עם זאת, זה דורש שיהיה לכם מספיק זיכרון VRAM פנוי (למעלה כתוב לכם כמה זה יוצא בג'יגות).
שימו לב - לרוב המחשבים (הביתיים) אין כרטיס גרפי, וגם אם יש לכם - ככה"נ תצטרכו להתקין דרייבר על המחשב שלכם כדי שזה יעבוד לכם.האפשרות השלישית - CPU Thread Pool Size (מספר הליבות במעבד) - מגדיר בכמה מליבות המעבד הרגיל (CPU) שלכם התוכנה תוכל להשתמש כדי לבצע את החישובים. מומלץ להגדיר מספר שקטן במעט מסך הליבות הכולל של המחשב שלכם, כדי לא "לתקוע" את המחשב לחלוטין ולתת למערכת ההפעלה שאר התוכנות להמשיך לעבוד בצורה חלקה ברקע.
אלא אם כן המעבד שלכם ממש חלש, או אז - תעשו כמעט כמו כמות הליבות, אבל תסגרו את כל החלונות ברקע.האפשרות הרביעית - Evaluation Batch Size (גודל אצווה להערכה) - קובע כמה טוקנים (חלקים של מילים) המודל קורא ומעבד בבת אחת כשהוא מנתח את הטקסט שכתבתם לו (ה-Prompt). מספר גבוה יותר יכול להאיץ את קריאת והבנת הטקסט הראשונית, אך יצרוך יותר זיכרון. לרוב, ברירת המחדל המוגדרת עובדת מצוין. (מניסיון - אם אתם תעלו את זה, זה לא ממש ימריץ את מהירות כתיבת התשובה ואין מה לשחק עם ההגדרות הברירת מחדל של זה..)
האפשרות החמישית - Max Concurrent Predictions (תחזיות במקביל):
זו הגדרה ניסיונית שקשורה לכמה בקשות המודל יכול לנסות לחשב באותו הזמן. לרובנו, שפשוט יושבים, מקלידים הודעה ומחכים לתשובה, אין מה לגעת פה. (מניסיון) תשאירו על ברירת המחדל.האפשרות השישית - Unified KV Cache (סידור חכם של הזיכרון):
הגדרה זו עוזרת לתוכנה לסדר ולנהל את הזיכרון הזמני של השיחה שלכם בצורה יותר יעילה. בשורה התחתונה: זה יכול לחסוך לכם קצת משאבים. מומלץ להשאיר דלוק. (גם אני לא הבנתי מה זה אומר כל כך, אבל כך מקובלני מgemini - 'ואחרי רבו אין לערער כלום") ' )
' )האפשרות השביעית והשמינית - RoPE Frequency Base / Scale (המתמטיקה מאחורי הקלעים):
כאן אנחנו נכנסים לקרביים של המתמטיקה של המודל. זה אלגוריתם שעוזר לו להבין איפה כל מילה נמצאת במשפט, בעיקר כשחופרים לו בטקסטים ארוכים. ההמלצה הכי חמה: אל תיגעו. תשאירו על מצב "Auto" ותנו לתוכנה לשבור את הראש. (גילוי נאות, גם אני לא הבנתי כל כך מה זה אומר..)האפשרות התשיעית - Offload KV Cache to GPU Memory (העברת זיכרון השיחה ל-VRAM):
במידה והרצתם את המודל על זיכרון גרפי, ויש לכם מקום פנוי - תוכלו להפעיל את האפשרות הזו, אפשרות זו גורמת לזה שזיכרון השיחה גם נשמע על הVRAM - וזה ממריץ את מהירות התשובה.
למעשה - האורך של השיחה - הוא חלק מטעינת המודל עצמו..האפשרות העשירית - Keep Model in Memory (להשאיר את המודל בהיכון/דלוק):
קובץ של מודל (ה-GGUF) שוקל כמה ג'יגות טובות. כשההגדרה הזו דלוקה, המודל נשאר טעון בזיכרון של המחשב גם אחרי שהוא סיים לענות לכם. התוצאה? כשתוסיפו עוד שאלה, הוא יתחיל לכתוב מיד ולא תצטרכו לחכות שהוא ייטען מחדש מהכונן הקשיח. חוסך המון זמן. (המלצה שלי - להשאיר דלוק)האפשרות האחת עשרה - Try mmap() (טעינה בדרך קיצור):
זו פקודת "קסם" של המערכת שיודעת לקחת את קובץ המודל מהכונן הקשיח ולמפות אותו ישר לזיכרון בדרך קיצור סופר מהירה. תמיד מומלץ להשאיר את זה דלוק. (ת'אמת - אין לי מושג למה יש אפשרות שלא לטעון מהר..)האפשרות השתיים עשרה - Seed (גרעין אקראיות - לשלוט ב"יצירתיות"):
תחשבו על זה כמו ה"מצב רוח" של המודל. כשהתיבה לא מסומנת (וכתוב Random Seed בצד), המודל מגריל מספר אקראי בכל פעם שאתם שולחים הודעה. זה אומר שאם תשאלו אותו את אותה שאלה בדיוק פעמיים, תקבלו תשובות קצת שונות. אם תסמנו את התיבה ותקלידו מספר ספציפי (למשל 1234), המודל יהפוך ל"רובוטי" לחלוטין - הוא ייתן לכם בדיוק (טוב, לא בדיוק, אבל בהחלט תרגישו שהוא הופך להיות יותר ויותר משעמם) את אותה התשובה שוב ושוב עבור אותה שאלה. לרוב המוחלט של השימושים, הרבה יותר כיף וטבעי להשאיר את זה על אקראי (לא מסומן).האפשרות השלוש עשרה - Flash Attention - עוד משהו שגורם למחשב לענות לכם יותר מהר, מומלץ להשאיר דלוק.. (אם כי אפשרות זו נתמכת לרוב רק על ידי מעבדים גרפיים, ולא על ידי מעבדים רגילים. ובכל זאת עדיף להשאיר דולק. 'אם לא יעיל, לא יזיק..'
האפשרות הארבע עשרה - K Cache Quantization (דחיסת "מפתחות" השיחה):
דמיינו שהזיכרון של המודל הוא כמו מחברת שבה הוא רושם כל מה שנאמר בשיחה כדי לא לשכוח. האפשרות הזו מאפשרת למחשב "לכווץ" את הכתב במחברת (לבצע קוונטיזציה) כדי שייכנסו בה הרבה יותר דפים.
איך זה עובד? בברירת מחדל זה מוגדר על F16 (איכות מקסימלית בלי דחיסה). אם תבחרו שם מספר נמוך יותר (כמו Q4), המחשב ידחוס את הזיכרון חזק יותר.
בתכל'ס - אם אתם מרגישים שהמחשב "נחנק" בשיחות ארוכות או שהזיכרון (RAM/VRAM) מתמלא – זה הכפתור 'שיציל אתכם'. כל עוד הכל רץ חלק, אין סיבה לגעת בזה.האפשרות החמש עשרה - V Cache Quantization (דחיסת "ערכי" השיחה):
זה האח התאום של הסעיף הקודם. בזמן ש-K שומר את ה"כותרות", ה-V שומר את ה"תוכן" של הזיכרון הזמני.
הערה חשובה: כדי שהאפשרות הזו תעבוד, אתם חייבים להשאיר את ה-Flash Attention (אפשרות 13) דלוק. המחשב משתמש ב-Flash Attention בתור ה"מכווץ" המהיר שלו.בשורה התחתונה: שילוב של שניהם (K ו-V) יחד עם בחירה בערך נמוך מ-F16, יאפשר לכם להריץ שיחות ארוכות כאורך הגלות גם על מחשב פשוט..
שימו לב שהאפשרויות 14 ו15 הם ניסיוניות (Experimental) - אם פתאום המודלים מתחילים להשתבש לכם, או לחזור על דברים בלי כל תוכן, מומלץ לכבות..
הנחיית מערכת
אחרי שהגדרתם את המודל יש כזה דבר לתת לו "הנחיית מערכת" = היינו הנחייה שקובעת את הזהות, מטרה, מומחיות, חוקים וכו' שחלים על מודל לאורך כל השיחה.
לא מספיק לכתוב "אתה עוזר חכם", אלא צריך להגדיר למודל מיהו, מה תפקידו המדוייק, מה סגנון הכתיבה, מבנה הפלט, סביבת הריצה שלו, הכלים השונים שעומדים לרשותו ועוד.
כשכותבים למודל בהנחיית המערכת "אתה מומחה לכתיבת קוד Python", זה מכניס אותו למאגר הידע של Python שבתוכו.
ככל שמשקיעים יותר בהנחיית המערכת ונותנים בה למודל יותר מידע רלוונטי, התוצאות טובות יותר בעשרות אחוזים.
יש מאגר בגיטהאב שמרכז דליפות של הנחיות מערכת של מודלי העל כמו Claude ו-Gemini, ושם אפשר לראות שהנחיות המערכת שלהם הן יותר ספר רכב מאשר הנחיה...קרדיט על ההסבר ל'הנחיית מערכת' ל @א.מ.ד.
את ההגדרה הזו אפשר להגדיר בLM כמו שרואים בתמונה:
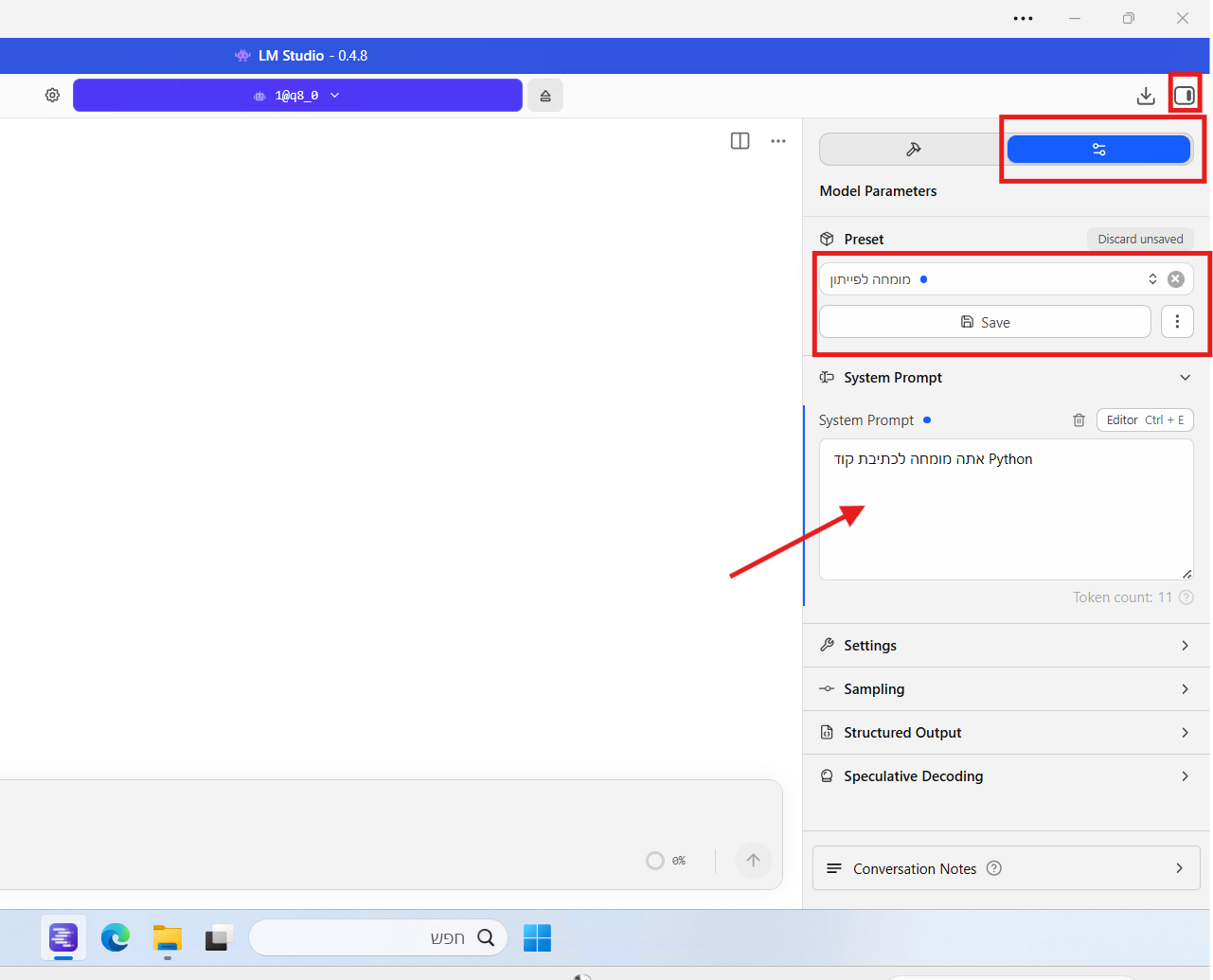
יש לבחור על החלונית למעלה, ללחוץ על התפריט הימני.
בsystem promt - לכתוב את ההנחייה.
לתת שם בpreset, ללחוץ save - והנה לכם "הנחיית מערכת".
ולסיום:
בהמשך אולי אפרסם מדריך לJAN (עוד תוכנה כמו LM סטודיו אבל הרבה יותר פשוטה), ולMCP בסיסי (גישה לסייר קבצים, שינוי הגדרות במחשב וכד'..)
הערה חשובה - הסיבה שבגללה לא הבאתי שום קישור היא מכוונת, נא לא לשאול שום שאלות בנידון. תודה רבה, ובתקווה להבנה
במדריך זה יש חלקים שבהם הניסוח הוא בלעדי לGemini AI, ומחובתי לציין זאת כאן..
שימו לב - מדריך זה התמקד בעיקר לאיך להריץ את המודלים בפועל על תוכנת LM studio, להסבר מפורט, רשימת מודלים ועוד כנסו לפה -מדריך מפורט ומושקע שכתב @א.מ.ד. מומלץ מאוד לקרוא בעיון.
אשמח לשמוע הערות והארות על המדריך. ולתקן טעויות במידת הצורך..
-
 א א.מ.ד. התייחס לנושא זה
א א.מ.ד. התייחס לנושא זה
-
 ח חובבן מקצועי התייחס לנושא זה
ח חובבן מקצועי התייחס לנושא זה
-
 ה המלאך התייחס לנושא זה
ה המלאך התייחס לנושא זה
-
 ש שניאור שמח העביר נושא זה מ-עזרה הדדית - בינה מלאכותית
ש שניאור שמח העביר נושא זה מ-עזרה הדדית - בינה מלאכותית
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}