להורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!
-
@משה-מזרחי כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
@אלף-שין
לא חושב שאפשר להבין ככה
תסמן את כל מה שיצא לך - בכחול , ואז תלחץ על זה
@אלף-שין כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
@דאנציג
זה מה שנפתח לי,
זה אומר שזה מתחיל לעבוד, או שיש תקלה [יתכן שזה בגלל חדר מחשבים לא עובד?]?> Active code page: 1255 > note: if you have an AMD or NVIDIA GPU then you need to pass -ngl 9999 to enable GPU offloading > {"build":1500,"commit":"a30b324","function":"server_cli","level":"INFO","line":2859,"msg":"build info","tid":"9434528","timestamp":1714631815} > {"function":"server_cli","level":"INFO","line":2862,"msg":"system info","n_threads":4,"n_threads_batch":-1,"system_info":"AVX = 1 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | ","tid":"9434528","timestamp":1714631815,"total_threads":4} > llama_model_loader: loaded meta data with 23 key-value pairs and 291 tensors from dictalm2.0.Q4_K_M.gguf (version GGUF V3 (latest)) > llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. > llama_model_loader: - kv 0: general.architecture str = llama > llama_model_loader: - kv 1: general.name str = models > llama_model_loader: - kv 2: llama.vocab_size u32 = 33152 > llama_model_loader: - kv 3: llama.context_length u32 = 32768 > llama_model_loader: - kv 4: llama.embedding_length u32 = 4096 > llama_model_loader: - kv 5: llama.block_count u32 = 32 > llama_model_loader: - kv 6: llama.feed_forward_length u32 = 14336 > llama_model_loader: - kv 7: llama.rope.dimension_count u32 = 128 > llama_model_loader: - kv 8: llama.attention.head_count u32 = 32 > llama_model_loader: - kv 9: llama.attention.head_count_kv u32 = 8 > llama_model_loader: - kv 10: llama.attention.layer_norm_rms_epsilon f32 = 0.000010 > llama_model_loader: - kv 11: llama.rope.freq_base f32 = 10000.000000 > llama_model_loader: - kv 12: general.file_type u32 = 15 > llama_model_loader: - kv 13: tokenizer.ggml.model str = llama > llama_model_loader: - kv 14: tokenizer.ggml.tokens arr[str,33152] = ["<unk>", "<s>", "</s>", "<0x00>", "<... > llama_model_loader: - kv 15: tokenizer.ggml.scores arr[f32,33152] = [0.000000, 0.000000, 0.000000, 0.0000... > llama_model_loader: - kv 16: tokenizer.ggml.token_type arr[i32,33152] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ... > llama_model_loader: - kv 17: tokenizer.ggml.bos_token_id u32 = 1 > llama_model_loader: - kv 18: tokenizer.ggml.eos_token_id u32 = 2 > llama_model_loader: - kv 19: tokenizer.ggml.unknown_token_id u32 = 0 > llama_model_loader: - kv 20: tokenizer.ggml.add_bos_token bool = true > llama_model_loader: - kv 21: tokenizer.ggml.add_eos_token bool = false > llama_model_loader: - kv 22: general.quantization_version u32 = 2 > llama_model_loader: - type f32: 65 tensors > llama_model_loader: - type q4_K: 193 tensors > llama_model_loader: - type q6_K: 33 tensors > llm_load_vocab: mismatch in special tokens definition ( 323/33152 vs 259/33152 ). > llm_load_print_meta: format = GGUF V3 (latest) > llm_load_print_meta: arch = llama > llm_load_print_meta: vocab type = SPM > llm_load_print_meta: n_vocab = 33152 > llm_load_print_meta: n_merges = 0 > llm_load_print_meta: n_ctx_train = 32768 > llm_load_print_meta: n_embd = 4096 > llm_load_print_meta: n_head = 32 > llm_load_print_meta: n_head_kv = 8 > llm_load_print_meta: n_layer = 32 > llm_load_print_meta: n_rot = 128 > llm_load_print_meta: n_embd_head_k = 128 > llm_load_print_meta: n_embd_head_v = 128 > llm_load_print_meta: n_gqa = 4 > llm_load_print_meta: n_embd_k_gqa = 1024 > llm_load_print_meta: n_embd_v_gqa = 1024 > llm_load_print_meta: f_norm_eps = 0.0e+00 > llm_load_print_meta: f_norm_rms_eps = 1.0e-05 > llm_load_print_meta: f_clamp_kqv = 0.0e+00 > llm_load_print_meta: f_max_alibi_bias = 0.0e+00 > llm_load_print_meta: f_logit_scale = 0.0e+00 > llm_load_print_meta: n_ff = 14336 > llm_load_print_meta: n_expert = 0 > llm_load_print_meta: n_expert_used = 0 > llm_load_print_meta: causal attn = 1 > llm_load_print_meta: pooling type = 0 > llm_load_print_meta: rope type = 0 > llm_load_print_meta: rope scaling = linear > llm_load_print_meta: freq_base_train = 10000.0 > llm_load_print_meta: freq_scale_train = 1 > llm_load_print_meta: n_yarn_orig_ctx = 32768 > llm_load_print_meta: rope_finetuned = unknown > llm_load_print_meta: ssm_d_conv = 0 > llm_load_print_meta: ssm_d_inner = 0 > llm_load_print_meta: ssm_d_state = 0 > llm_load_print_meta: ssm_dt_rank = 0 > llm_load_print_meta: model type = 7B > llm_load_print_meta: model ftype = Q4_K - Medium > llm_load_print_meta: model params = 7.25 B > llm_load_print_meta: model size = 4.07 GiB (4.83 BPW) > llm_load_print_meta: general.name = models > llm_load_print_meta: BOS token = 1 '<s>' > llm_load_print_meta: EOS token = 2 '</s>' > llm_load_print_meta: UNK token = 0 '<unk>' > llm_load_print_meta: LF token = 13 '<0x0A>' > llm_load_tensors: ggml ctx size = 0.15 MiB -
@NH-LOCAL כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
אתה בהחלט צודק. ממש לאחרונה עלה מודל בעברית מלאה. אבל הוא כבד יותר מהמודל באנגלית ששמתי בפוסט הראשי
@NH-LOCAL יש לך אותו? כמה הוא כבד?
-
@אלף-שין כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
@דאנציג
זה מה שנפתח לי,
זה אומר שזה מתחיל לעבוד, או שיש תקלה [יתכן שזה בגלל חדר מחשבים לא עובד?]?
Active code page: 1255
note: if you have an AMD or NVIDIA GPU then you need to pass -ngl 9999 to enable GPU offloadingזה אומר שהוא מתחיל לעבוד
@דאנציג כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
אגב, @sivan22 עם llamafile וההגדרות של @NH-LOCAL המודל בעברית עובד לי הרבה יותר מהר מאשר עם התוכנה LM STUDIO, שגם מנצלת יותר משאבים במחשב (גם GPU וגם CPU), ובכל זאת יותר איטי אצלי (ותחושה שלי גם פחות מדויק).
מעניין. אני מרגיש בדיוק הפוך - נראה שתוכנת LMSTUDIO מנצלת את המשאבים בצורה המיטבית וככה עושה את הכל מהיר יותר
(למעשה, אפשר לבדוק את זה - אמור להיות נתונים של מספר הטוקנים לשנייה) -
אחרי כמה שניות נפתח לך חלון בכרום. לפחות לי זה היה ככה.
-
@שמואל-רבינוביץ כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
כשאני פותח את הקבצים שנקראים כך
dictalm2.0.Q4_K_M.gguf
וכך
llamafile-0.8
הוא שואל איך לפתוח את זה כשאני בוחר לפתוח אותו בדפדפן גוגל אז נפתח לי דפדפן ללא שם ומבצע לי הורדה של הקובץאת הקבצים האלו לא צריך לפתוח!
בקבצים האלו
start-language-model
start-language-model-on-gpu
הוא עושה לי את הבעיה של המסך השחוראת אחד הקבצים האלו צריך להפעיל, ואם יש לך מסך שחור, אז כנראה שהמחשב שלך חלש מדאי ולא יכול להפעיל את זה.
מה המאפיינים של המחשב שלך? -
@NH-LOCAL כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
מעניין. אני מרגיש בדיוק הפוך - נראה שתוכנת LMSTUDIO מנצלת את המשאבים בצורה המיטבית וככה עושה את הכל מהיר יותר
(למעשה, אפשר לבדוק את זה - אמור להיות נתונים של מספר הטוקנים לשנייה)לכאורה זה בגלל שלא הגדרתי כלום בLM STUDIO, אלא ישר פתחתי.
מה צריך להגדיר והיכן?
(אני לא יודע אנגלית, אלא מצליח לקרוא, וכאשר מסבירים לי אני מבין קצת...) -
@דאנציג לפי מה שאני מבין - בעקרון יש הגדרה אוטומטית לפי המפרט של המחשב שלך
בחלון בצד ימין - יש מגוון של הגדרות. בין השאר יש שם הגדרה של מס' שכבות ב-GPU - אפשר לנסות לשחק עם זה - כרגע זה מוגדר אצלי על 14
(אם אין לך מעבד גרפי של NVIDIA או AMD אז זה לא רלוונטי)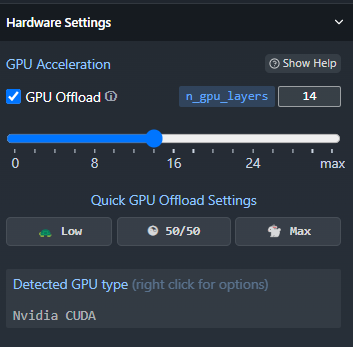
בנוסף ניתן להגדיר את מספר הסיבובים בו זמנית של ה-CPU. בדרך כלל מומלץ להתאים את זה למספר הליבות. אם יש לך 4 ליבות - מומלץ להגדיר את המספר ל-4.
[את המספר של הליבות אפשר לראות במנהל המשימות בכרטיסית CPU]בתמונה זו ההגדרה האחרונה ברשימה:
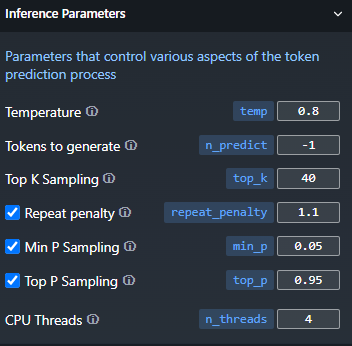
מקווה שאני מובן
-
@NH-LOCAL כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
מקווה שאני מובן
מובן מאוד, יישר כוח.
אני התכוונתי להוראות האלו, עכשיו מצאתי את ההגדרה הזו, ננסה עכשיו, אולי זה יביא תוצאות יותר טובות.אגב, אני חושב שכדאי להכניס את ההוראות, או לפחות קישור להוראות בפוסט הראשון שלך.
יישר כוח. -
@שמואל-רבינוביץ כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
יכול להיות שזה כבד מידי בשבילו?
לא.
אתה צריך להפעיל את הקובץ הזה start-language-model, אבל גם לי יש כזו בעיה עם המודל PHI3. אם אמצע פתרון בעז"ה בל"נ אכתוב לך. -
אשמח בכל מקרה איזה מודל אתה חושב שכן יעבוד לי ?
-
@שמואל-רבינוביץ
תנסה עם התוכנה LM STUDIO.כאן יש קישור להורדה, וכן קישור לכמה פוסטים למעלה שיעזרו לך להתקין.
עריכה:
תוכל לראות במדריך כאן אם חסר משהו במדריך אשמח שתודיע לי.
בהצלחה -
פוסט זה נמחק!
-
@דאנציג כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
אם חסר משהו במדריך אשמח שתודיע לי.
בצד ימין להגדיר שיהיה מימין לשמאל
-
@יוסי-מחשבים
זה באמת נצרך, אבל לא מצאתי היכן ההגדרה הזו, אשמח שתכוון אותי יותר.
תודה רבה -
@דאנציג כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
@יוסי-מחשבים
זה באמת נצרך, אבל לא מצאתי היכן ההגדרה הזו, אשמח שתכוון אותי יותר.
תודה רבהללחוץ על הסמל הגדרות, לגלול למטה ולבחור ב Right to left
-
@יוסי-מחשבים
והיכן הסמל הגדרות?
גם בSETTINGS לא מצאתי:
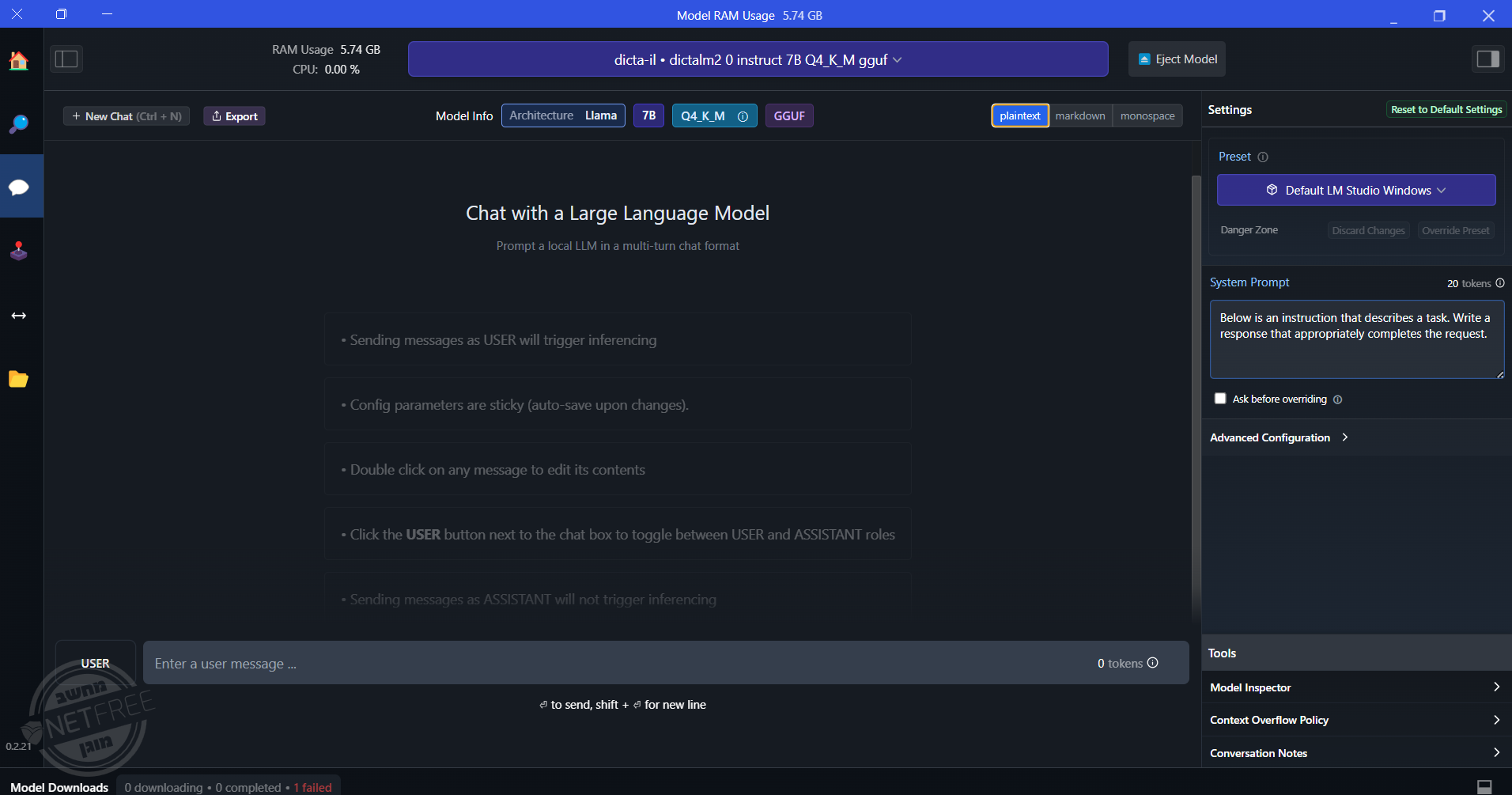
-
@דאנציג כתב בלהורדה | כך תריצו מודל בינה מלאכותית על המחשב שלכם - בקלי קלות!:
גם בSETTINGS לא מצאתי
לי מופיע (ווינדוס 11):
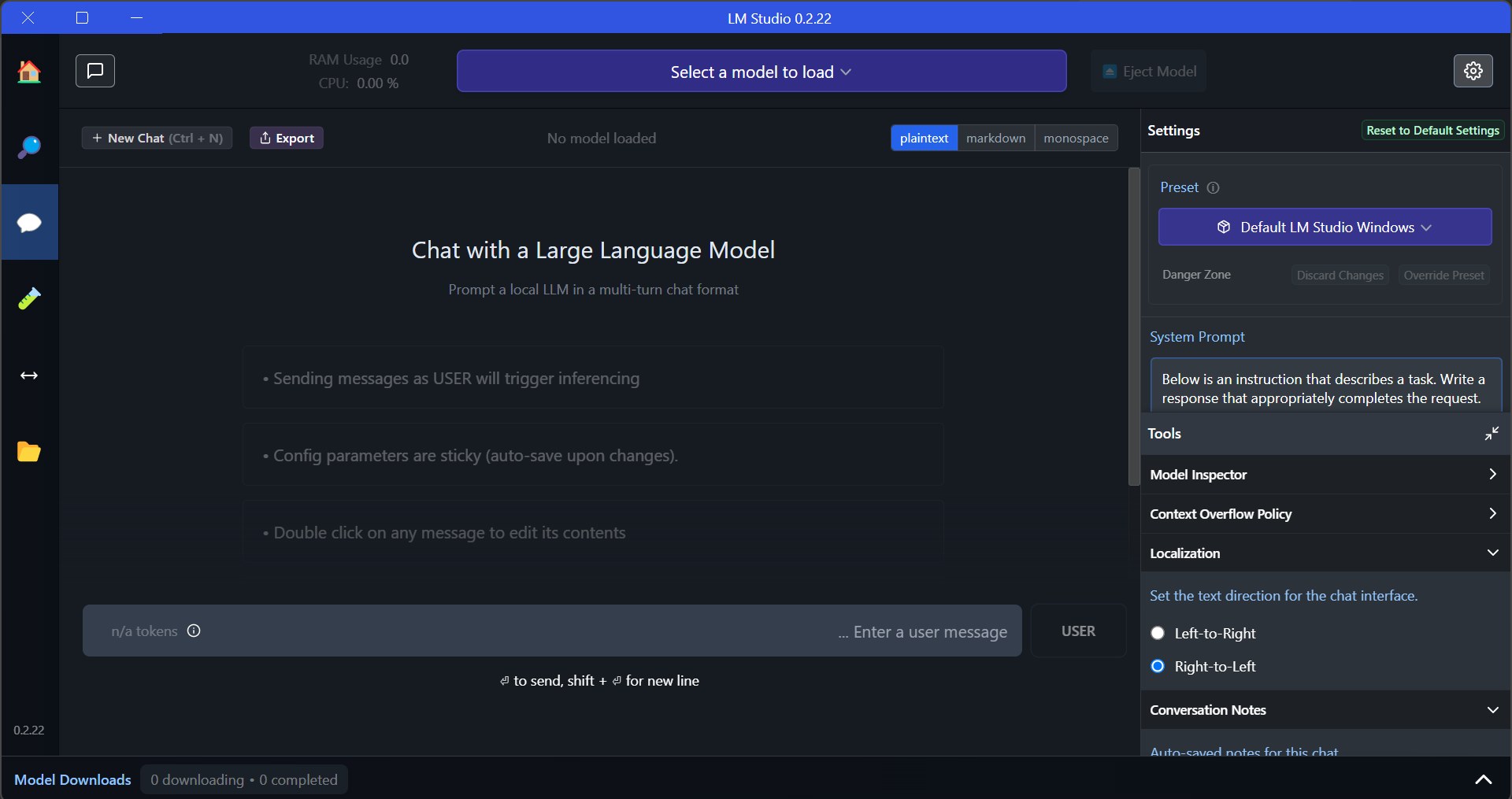
{if(result!=null&&result!=''){var a=document.createElement('a');a.href='https://www.google.co.il/search?q=site:mitmachim.top '+encodeURIComponent(result.trim());a.target='_blank';a.click();}}})();};){kind=link}