שיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא
-
@NH-LOCAL אני מרגיש שפיצחתי את הסגנון התנכי של המודל
תנסו את זה:
למרות המצאותי וקש ראשי אבקש שהצחוק ימשיך להתגלגל כי כן דרכי וגם דרכך נשמח ונודה יחדותאמר ראשי לישון נשכבתי פן מחר אבכה ובעייפות נהלכתי
המשך אדר שמח!
-
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
ומה זה?
הייתי מאמין שהוא יחשוב שזה תנך
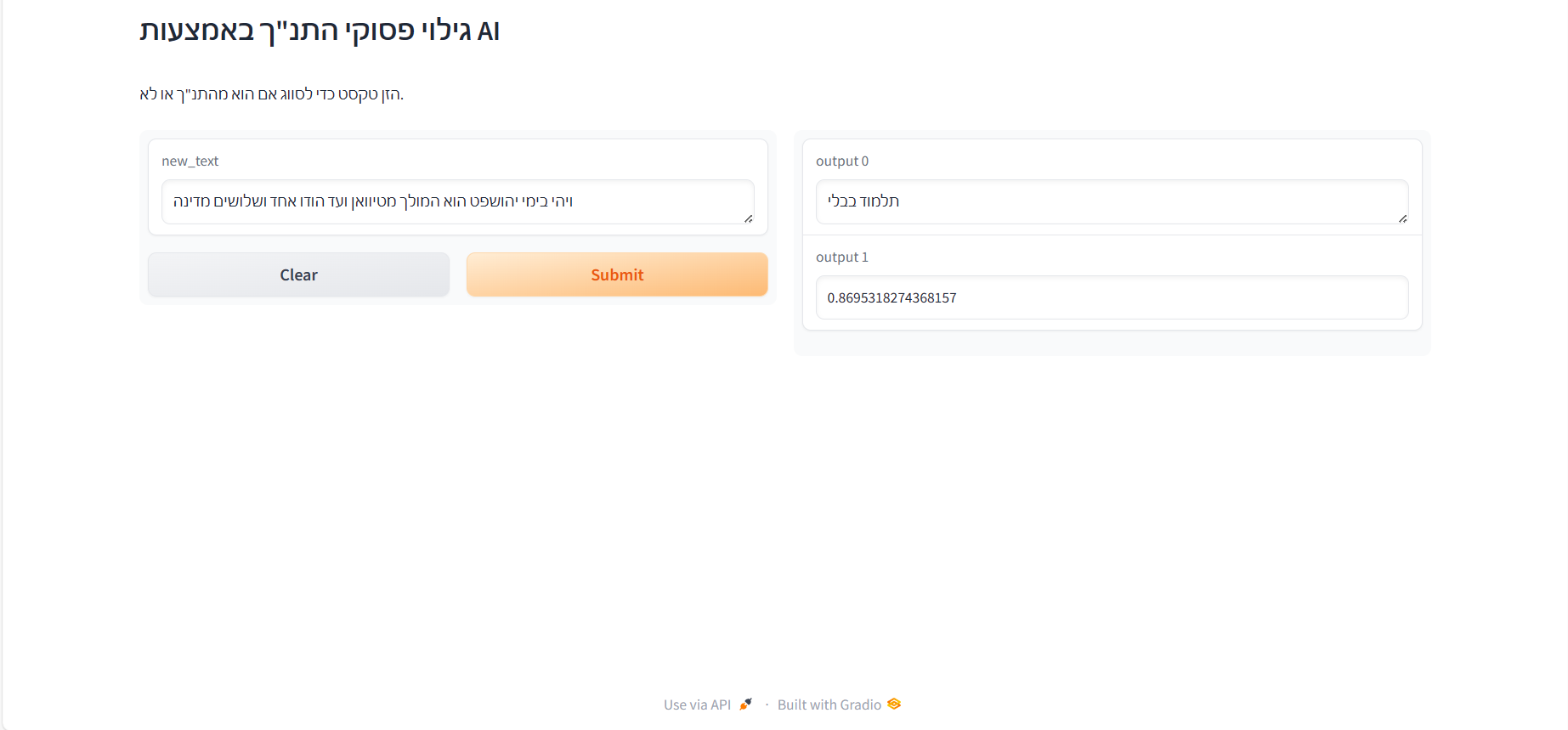
המודל מזהה את המילה "ועד" כתלמוד.
תנסה את זה במקום ותראה:
ויהי בימי יהושפט הוא המולך מטיוואן להודו אחד ושלשים מדינה -
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
המודל מזהה את המילה "ועד" כתלמוד.
אבל את הפסוק המקורי הוא כן מזהה כתנך
למרות המילה ועד
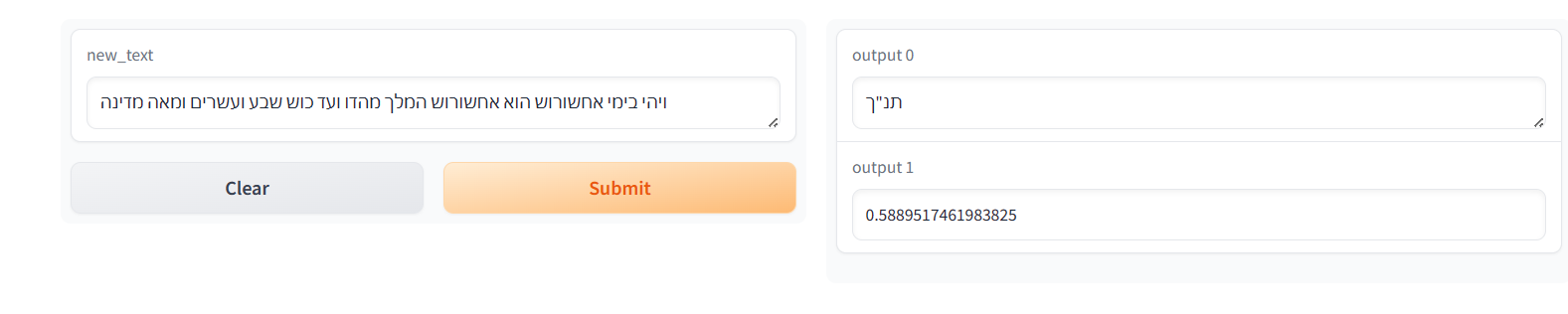
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
המודל מזהה את המילה "ועד" כתלמוד.
אבל את הפסוק המקורי הוא כן מזהה כתנך
למרות המילה ועד
צריך עיון רב
ככל הנראה יש מילים עם משקל הנוטים יותר לשימוש בתנך ויש עם יותר משקל בתלמוד בבלי.
כנראה המודל מחשב לפי כל המילים ומשקלם לאן ראוי לשייך את המשפט.
אפשר לבדוק כל משפט עם מפרקים אותו לגורמים לראות איך התהליך קורה. -
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
המודל מזהה את המילה "ועד" כתלמוד.
אבל את הפסוק המקורי הוא כן מזהה כתנך
למרות המילה ועד
צריך עיון רב
ככל הנראה יש מילים עם משקל הנוטים יותר לשימוש בתנך ויש עם יותר משקל בתלמוד בבלי.
כנראה המודל מחשב לפי כל המילים ומשקלם לאן ראוי לשייך את המשפט.
אפשר לבדוק כל משפט עם מפרקים אותו לגורמים לראות איך התהליך קורה.@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
המודל מזהה את המילה "ועד" כתלמוד.
אבל את הפסוק המקורי הוא כן מזהה כתנך
למרות המילה ועד
צריך עיון רב
ככל הנראה יש מילים עם משקל הנוטים יותר לשימוש בתנך ויש עם יותר משקל בתלמוד בבלי.
כנראה המודל מחשב לפי כל המילים ומשקלם לאן ראוי לשייך את המשפט.
אפשר לבדוק כל משפט עם מפרקים אותו לגורמים לראות איך התהליך קורה.הנה דוגמא:
תחפשו: שלום לרחוק ולקרוב
המודל מזהה כאחר. למרות שכתוב בתנ"ך אבל אלו מילים שנשמעים כמו השיחה שלנו כיום.תחפשו: שלום לרחוק ולקרוב אמר ורפאתיו
המודל מזהה כתלמוד בבליתחפשו: שלום לרחוק ולקרוב אמר ורפאתיו לאמר
המודל מזהה כתנך. המילה "לאמר" מאוד תנכית ולכן זה קובע את המשקל של שאר המשפט. -
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
המודל מזהה את המילה "ועד" כתלמוד.
אבל את הפסוק המקורי הוא כן מזהה כתנך
למרות המילה ועד
צריך עיון רב
ככל הנראה יש מילים עם משקל הנוטים יותר לשימוש בתנך ויש עם יותר משקל בתלמוד בבלי.
כנראה המודל מחשב לפי כל המילים ומשקלם לאן ראוי לשייך את המשפט.
אפשר לבדוק כל משפט עם מפרקים אותו לגורמים לראות איך התהליך קורה.הנה דוגמא:
תחפשו: שלום לרחוק ולקרוב
המודל מזהה כאחר. למרות שכתוב בתנ"ך אבל אלו מילים שנשמעים כמו השיחה שלנו כיום.תחפשו: שלום לרחוק ולקרוב אמר ורפאתיו
המודל מזהה כתלמוד בבליתחפשו: שלום לרחוק ולקרוב אמר ורפאתיו לאמר
המודל מזהה כתנך. המילה "לאמר" מאוד תנכית ולכן זה קובע את המשקל של שאר המשפט.חשוב לי להדגיש שלא מדובר במודל שפה גדול (מה שמכונה LLM) אלא במודל יותר פשוט מזה. לשם השוואה המודל הזה שוקל בסביבות 180KB לעומת מודל השפה BEREL-2.0 ששוקל כ700 מ"ב.
גם כמות הנתונים קטנה מאד באופן יחסי.
לאור זאת, התוצאות די מרשימות.אם באמת יש צורך בכזה מודל, אפשר לאמן את BEREL על מסד הנתונים של ספריא, ואז יתקבלו תוצאות טובות יותר.
-
חשוב לי להדגיש שלא מדובר במודל שפה גדול (מה שמכונה LLM) אלא במודל יותר פשוט מזה. לשם השוואה המודל הזה שוקל בסביבות 180KB לעומת מודל השפה BEREL-2.0 ששוקל כ700 מ"ב.
גם כמות הנתונים קטנה מאד באופן יחסי.
לאור זאת, התוצאות די מרשימות.אם באמת יש צורך בכזה מודל, אפשר לאמן את BEREL על מסד הנתונים של ספריא, ואז יתקבלו תוצאות טובות יותר.
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
חשוב לי להדגיש שלא מדובר במודל שפה גדול (מה שמכונה LLM) אלא במודל יותר פשוט מזה. לשם השוואה המודל הזה שוקל בסביבות 180KB לעומת מודל השפה BEREL-2.0 ששוקל כ700 מ"ב.
גם כמות הנתונים קטנה מאד באופן יחסי.
לאור זאת, התוצאות די מרשימות.אם באמת יש צורך בכזה מודל, אפשר לאמן את BEREL על מסד הנתונים של ספריא, ואז יתקבלו תוצאות טובות יותר.
האם זה טכנולוגיה שונה מLLM או שזה לא LLM כי זה לא Large?
-
חשוב לי להדגיש שלא מדובר במודל שפה גדול (מה שמכונה LLM) אלא במודל יותר פשוט מזה. לשם השוואה המודל הזה שוקל בסביבות 180KB לעומת מודל השפה BEREL-2.0 ששוקל כ700 מ"ב.
גם כמות הנתונים קטנה מאד באופן יחסי.
לאור זאת, התוצאות די מרשימות.אם באמת יש צורך בכזה מודל, אפשר לאמן את BEREL על מסד הנתונים של ספריא, ואז יתקבלו תוצאות טובות יותר.
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
חשוב לי להדגיש שלא מדובר במודל שפה גדול (מה שמכונה LLM) אלא במודל יותר פשוט מזה. לשם השוואה המודל הזה שוקל בסביבות 180KB לעומת מודל השפה BEREL-2.0 ששוקל כ700 מ"ב.
גם כמות הנתונים קטנה מאד באופן יחסי.
לאור זאת, התוצאות די מרשימות.אם באמת יש צורך בכזה מודל, אפשר לאמן את BEREL על מסד הנתונים של ספריא, ואז יתקבלו תוצאות טובות יותר.
מסכים לגמרי, יחסית זה עבודה נהדרת.
ממש כיף לי למצוא את הנקודות שינוי שלו בין מילה למילה.הנה דוגמה קטנה, התחלתי על המילה "מיתיבי" שזה הוא מזהה כתלמוד ואז הוספתי שתי מחרוזות בת שלש תיבות שגם כתובים בטקסט שיש לו כתנך ולא משנה כמה ארמית אני מוסיף הוא עדיין קורא לזה תנך.
מתיבי בראשית ברא אלוקים למימרא כי הכל ברא לכבודו בניחותא וכך הוא אדעתא דהכי ואז נח רישיה בגולתא דדהבה דיליה וקם ואתחשיב במיניה וביה אמר רבא לאביי אם כן ההוא גברא דעקר עציה מתוך חמרה ואזל למתיבתא דרקיע וערק לנפשיה מפני פורים גופיה אלו מציאות שפטור להכריז כי מצא לעצמו ומצא לחבריה וכך הווה במתא דידיהבעיני זה מרתק!
-
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
חשוב לי להדגיש שלא מדובר במודל שפה גדול (מה שמכונה LLM) אלא במודל יותר פשוט מזה. לשם השוואה המודל הזה שוקל בסביבות 180KB לעומת מודל השפה BEREL-2.0 ששוקל כ700 מ"ב.
גם כמות הנתונים קטנה מאד באופן יחסי.
לאור זאת, התוצאות די מרשימות.אם באמת יש צורך בכזה מודל, אפשר לאמן את BEREL על מסד הנתונים של ספריא, ואז יתקבלו תוצאות טובות יותר.
האם זה טכנולוגיה שונה מLLM או שזה לא LLM כי זה לא Large?
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
האם זה טכנולוגיה שונה מLLM או שזה לא LLM כי זה לא Large?
זה שונה מהותית. לעניינינו ההבדל המבדיל הוא המנגנון שנקרא attention שזהו בעצם חישוב מתמטי של יחס ומשקל של כל מילה ביחס למילה אחרת באותו משפט, שגורם לכל מילה להשפיע על משמעות המשפט ברמה אחרת, וכן לכך שמילה זהה לכאורה תקבל משמעות אחרת לגמרי לפי ההקשר שלה באותו משפט. וכמובן שגם זה נלמד בזמן האימון.
מעניין שה"מבחן" שנתנו לBEREL היה להבחין בין חֵלב לחָלב ועוד מילים כאלו, והוא עבר בהצלחה . פרטים במאמר המדעי.
-
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
האם זה טכנולוגיה שונה מLLM או שזה לא LLM כי זה לא Large?
זה שונה מהותית. לעניינינו ההבדל המבדיל הוא המנגנון שנקרא attention שזהו בעצם חישוב מתמטי של יחס ומשקל של כל מילה ביחס למילה אחרת באותו משפט, שגורם לכל מילה להשפיע על משמעות המשפט ברמה אחרת, וכן לכך שמילה זהה לכאורה תקבל משמעות אחרת לגמרי לפי ההקשר שלה באותו משפט. וכמובן שגם זה נלמד בזמן האימון.
מעניין שה"מבחן" שנתנו לBEREL היה להבחין בין חֵלב לחָלב ועוד מילים כאלו, והוא עבר בהצלחה . פרטים במאמר המדעי.
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
האם זה טכנולוגיה שונה מLLM או שזה לא LLM כי זה לא Large?
זה שונה מהותית. לעניינינו ההבדל המבדיל הוא המנגנון שנקרא attention שזהו בעצם חישוב מתמטי של יחס ומשקל של כל מילה ביחס למילה אחרת באותו משפט, שגורם לכל מילה להשפיע על משמעות המשפט ברמה אחרת, וכן לכך שמילה זהה לכאורה תקבל משמעות אחרת לגמרי לפי ההקשר שלה באותו משפט. וכמובן שגם זה נלמד בזמן האימון.
מעניין שה"מבחן" שנתנו לBEREL היה להבחין בין חֵלב לחָלב ועוד מילים כאלו, והוא עבר בהצלחה . פרטים במאמר המדעי.
יש למערכות האלו אלגוריתים? איך הם מחליטים כמה משקל לכל תיבה?
-
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
האם זה טכנולוגיה שונה מLLM או שזה לא LLM כי זה לא Large?
זה שונה מהותית. לעניינינו ההבדל המבדיל הוא המנגנון שנקרא attention שזהו בעצם חישוב מתמטי של יחס ומשקל של כל מילה ביחס למילה אחרת באותו משפט, שגורם לכל מילה להשפיע על משמעות המשפט ברמה אחרת, וכן לכך שמילה זהה לכאורה תקבל משמעות אחרת לגמרי לפי ההקשר שלה באותו משפט. וכמובן שגם זה נלמד בזמן האימון.
מעניין שה"מבחן" שנתנו לBEREL היה להבחין בין חֵלב לחָלב ועוד מילים כאלו, והוא עבר בהצלחה . פרטים במאמר המדעי.
יש למערכות האלו אלגוריתים? איך הם מחליטים כמה משקל לכל תיבה?
-
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
יש למערכות האלו אלגוריתים? איך הם מחליטים כמה משקל לכל תיבה?
למידת מכונה, כמו כל רשת נוירונים. הוא לומד מהטעויות שלו, ומתקן את המשקלים לפי התוצאות המבוקשות.
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
יש למערכות האלו אלגוריתים? איך הם מחליטים כמה משקל לכל תיבה?
למידת מכונה, כמו כל רשת נוירונים. הוא לומד מהטעויות שלו, ומתקן את המשקלים לפי התוצאות המבוקשות.
תודה רבה!
אז אם הבנתי נכון בML אין אלגוריתים אלא המערכת יוצרת לעצמה הבנה על פי האימון ושם זה מסתיים.
האם אפשר לראות מה המערכת למדה? איפה המודל שומר את המידע שרכש?
אני מתאר לעצמי שזה לא על רגל אחת אבל תודה בכל אופן. -
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
האם זה טכנולוגיה שונה מLLM או שזה לא LLM כי זה לא Large?
זה שונה מהותית. לעניינינו ההבדל המבדיל הוא המנגנון שנקרא attention שזהו בעצם חישוב מתמטי של יחס ומשקל של כל מילה ביחס למילה אחרת באותו משפט, שגורם לכל מילה להשפיע על משמעות המשפט ברמה אחרת, וכן לכך שמילה זהה לכאורה תקבל משמעות אחרת לגמרי לפי ההקשר שלה באותו משפט. וכמובן שגם זה נלמד בזמן האימון.
מעניין שה"מבחן" שנתנו לBEREL היה להבחין בין חֵלב לחָלב ועוד מילים כאלו, והוא עבר בהצלחה . פרטים במאמר המדעי.
-
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
זה שונה מהותית.
אז איך קוראים לטכנולוגיה הזו?
@מישהו12 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
זה שונה מהותית.
אז איך קוראים לטכנולוגיה הזו?
זהו מודל של למידת מכונה, אבל מדור קודם ללא attention.
המודל הזה ספציפית הוא זה: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html -
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
יש למערכות האלו אלגוריתים? איך הם מחליטים כמה משקל לכל תיבה?
למידת מכונה, כמו כל רשת נוירונים. הוא לומד מהטעויות שלו, ומתקן את המשקלים לפי התוצאות המבוקשות.
תודה רבה!
אז אם הבנתי נכון בML אין אלגוריתים אלא המערכת יוצרת לעצמה הבנה על פי האימון ושם זה מסתיים.
האם אפשר לראות מה המערכת למדה? איפה המודל שומר את המידע שרכש?
אני מתאר לעצמי שזה לא על רגל אחת אבל תודה בכל אופן.@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
האם אפשר לראות מה המערכת למדה? איפה המודל שומר את המידע שרכש?
אפשר לראות, ובמקרה הנוכחי זה נשמר בתוך שתי קבצים בעלי סיומת pkl. בפועל, בן אדם לא יכול להבין את המודל, מכיוון שמדובר ברצף של תווים חסרי משמעות , כמו קוד בינארי של תוכנה.
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
חשוב לי להדגיש שלא מדובר במודל שפה גדול (מה שמכונה LLM) אלא במודל יותר פשוט מזה. לשם השוואה המודל הזה שוקל בסביבות 180KB לעומת מודל השפה BEREL-2.0 ששוקל כ700 מ"ב.
גם BEREL לא נחשב מודל שפה גדול, אלא מודל שפה קטן (SLM), מודלים גדולים מכילים עשרות-מאות מליארדי פרמטרים. שמתבטאים במשקל של מאות ג'יגה.
למעשה, המודל הנוכחי הוא בכלל לא מודל שפה במובן המוכר, מאחר שהוא לא יכול ליצור טקסט אלא בסך הכל לסווג טקסט לקבוצות שונות באמצעות עיבוד שפה טבעית (המכונה NLP)
ככלל, המושג "בינה מלאכותית" ו"למידת מכונה", הוא מושג רחב מאוד שקיים כבר עשרות שנים. הרבה לפני שמודלי השפה הגדולים, יוצרי התמונות והבינה המלאכותית הכללית פרצו לחיינו.
- החיפוש של גוגל משתמש באלגוריתמים של בינה מלאכותית להתאמת התוצאות המתאימות ביותר.
- סינון הספאם במייל מתבסס על מודל סיווג טקסטים
- גוגל טרנסלייט ודומיו מתבסס על בינה מלאכותית של עיבוד שפה טבעית
- זיהוי קולי, כנ"ל
ועוד..
-
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
האם אפשר לראות מה המערכת למדה? איפה המודל שומר את המידע שרכש?
אפשר לראות, ובמקרה הנוכחי זה נשמר בתוך שתי קבצים בעלי סיומת pkl. בפועל, בן אדם לא יכול להבין את המודל, מכיוון שמדובר ברצף של תווים חסרי משמעות , כמו קוד בינארי של תוכנה.
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
חשוב לי להדגיש שלא מדובר במודל שפה גדול (מה שמכונה LLM) אלא במודל יותר פשוט מזה. לשם השוואה המודל הזה שוקל בסביבות 180KB לעומת מודל השפה BEREL-2.0 ששוקל כ700 מ"ב.
גם BEREL לא נחשב מודל שפה גדול, אלא מודל שפה קטן (SLM), מודלים גדולים מכילים עשרות-מאות מליארדי פרמטרים. שמתבטאים במשקל של מאות ג'יגה.
למעשה, המודל הנוכחי הוא בכלל לא מודל שפה במובן המוכר, מאחר שהוא לא יכול ליצור טקסט אלא בסך הכל לסווג טקסט לקבוצות שונות באמצעות עיבוד שפה טבעית (המכונה NLP)
ככלל, המושג "בינה מלאכותית" ו"למידת מכונה", הוא מושג רחב מאוד שקיים כבר עשרות שנים. הרבה לפני שמודלי השפה הגדולים, יוצרי התמונות והבינה המלאכותית הכללית פרצו לחיינו.
- החיפוש של גוגל משתמש באלגוריתמים של בינה מלאכותית להתאמת התוצאות המתאימות ביותר.
- סינון הספאם במייל מתבסס על מודל סיווג טקסטים
- גוגל טרנסלייט ודומיו מתבסס על בינה מלאכותית של עיבוד שפה טבעית
- זיהוי קולי, כנ"ל
ועוד..
@NH-LOCAL כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
@Whenever כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
האם אפשר לראות מה המערכת למדה? איפה המודל שומר את המידע שרכש?
אפשר לראות, ובמקרה הנוכחי זה נשמר בתוך שתי קבצים בעלי סיומת pkl. בפועל, בן אדם לא יכול להבין את המודל, מכיוון שמדובר ברצף של תווים חסרי משמעות , כמו קוד בינארי של תוכנה.
@sivan22 כתב בשיתוף | מודל AI קטן שיצרתי - זיהוי האם מחרוזת היא מהתנ"ך או לא:
חשוב לי להדגיש שלא מדובר במודל שפה גדול (מה שמכונה LLM) אלא במודל יותר פשוט מזה. לשם השוואה המודל הזה שוקל בסביבות 180KB לעומת מודל השפה BEREL-2.0 ששוקל כ700 מ"ב.
גם BEREL לא נחשב מודל שפה גדול, אלא מודל שפה קטן (SLM), מודלים גדולים מכילים עשרות-מאות מליארדי פרמטרים. שמתבטאים במשקל של מאות ג'יגה.
למעשה, המודל הנוכחי הוא בכלל לא מודל שפה במובן המוכר, מאחר שהוא לא יכול ליצור טקסט אלא בסך הכל לסווג טקסט לקבוצות שונות באמצעות עיבוד שפה טבעית (המכונה NLP)
תודה רבה!
ניסיתי באמת להוריד את הקובץ אבל הוא נפתח כתווים מוזרים.שוב תודה על ההסבר, יש לי הרבה מה ללמוד:)
https://en.wikipedia.org/wiki/Neural_network_(machine_learning)
https://www.freecodecamp.org/news/deep-learning-neural-networks-explained-in-plain-english/רציתי לתת לך עוד מוניטין אבל כבר הבאתי לך שש היום וזה מוגבל

שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}