להורדה | כך תריצו מודל שפה חזק על המחשב הביתי שלכם
-
@NH-LOCAL כתב בהמלצה | כך תריצו מודל שפה חזק על המחשב הביתי שלכם:
ככלל, זה המאגר של דיקטה בגיטהאב, אבל אני לא רואה שם משהו ספציפי של המודל הנ"ל
זה לא זה?
https://github.com/Dicta-Israel-Center-for-Text-Analysis/alephbertgimmel
אגב הביאו שם קישור לדרופבוקס להוריד את המודול, ומלבד קבצי טקסט וקובץ פייתון אני לא רואה שם כלום, איך אמורים להריץ את זה?[לא הורדתי את זה עדיין למחשב שלי כי זה שוקל 4+ ג'יגה, ואני רוצה לדעת שזה שימושי לפני שאני מוריד, סליחה אם אני משגע אותך, אבל ראיתי שאתה מבין ב AI] -
@האדם-החושב אני ינסה. אבל איפה הקישור להורדת המודול?
-
@NH-LOCAL
https://bit.ly/3vzlvgG
[הובא בהמשך השרשור שם בפרוג] -
@האדם-החושב עובד יפה. זה התוצאה:
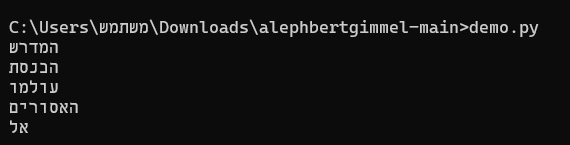
המודל הספציפי שבהדגמה שלהם, מבצע השלמה של מילה מתוך משפט.
המשפט בדוגמה היה:
דני הלך לבית [MASK] היום.המודל אמור להשלים את מה שבמילה "[MASK]". והוא נתן כמה אפשרויות כמופיע בתמונה. מה שבעצם נותן את התוצאה:
דני הלך לבית הכנסת היום
דני הלך לבית האסורים היוםוכן הלאה...
בקיצור: לא ממש יוצר טקסט ב-AI, אלא משלים טקסט ב-AI. זה טוב בעיקר להשלמה של מילים במקרה של סריקה פגומה של ספרים ישנים וכן הלאה. כמו שמפורט גם בפרוג - עיין בספוילר.
והנה כמה היבטים בתחום התורני שהמודל עשוי לסייע בהם:תחום זיהוי תמונה והפיכתה לטקסט (ocr) עשוי להסתייע רבות במודל שכזה, שכן מתחילת ימי הדפוס הוא אומץ בחום רב על ידי עם הספר, והודפסו עשרות אלפי כותרים של ספרי קודש בעברית, רבים מאד מהם בפונט שמכונה "כתב רש"י" שהוא בעצם פונט של עברית שמבוסס על צורת כתיבה שהיתה מקובלת בספרד של ימי הביניים (הסיבה לכינוי זה הוא משום שהספר הראשון שהודפס בפונט זה היה פירוש רש"י לתורה. רש"י עצמו מעולם לא השתמש בכתב זה.)
מלבד הבעיה שדפוסים רבים לא היו חדים והאותיות היו מטושטות או שבורות, עברית היא שפה קשה לזיהוי מחמת אותיות רבות שדומות זו לזו (ב-כ-נ, ח-ת-ה, ו-ז-ן, ס-ם), בעיה שאף מתעצמת עם השימוש בכתב רש"י (א-ש, ט-ע-מ, ס-ם, ק-ה).
נקודה נוספת היא שספרים רבים משלבים פונט עברי רגיל מרובע יחד עם כתב רש"י. מתכונת מקובלת היא שהמילה הראשונה בקטע היא בכתב מרובע והשאר בכתב רש"י. או שהטקסט המרכזי בספר הוא בכתב מרובע, והחיבורים סביב הם בכתב רש"י [הש"ס כדוגמה קלאסית, מקראות גדולות, שולחן ערוך ועוד.]מכל הסיבות הללו, זיהוי טקסט של ספרי קודש ברמת דיוק גבוהה הינו אתגר משמעותי.
אחד הפתרונות לבעיה זו היא שילובו של מודל שפה שבהבנה נכונה של ההקשר יוכל לתקן אוטומטית שגיאות ולשפר מאד את איכות הזיהוי. בתחום זה ראוי לציון מאמר חשוב מאת חוקרים באוניברסיטת בר אילן שהגיעו לאחוז דיוק של 99.85 באמצעות מודל עיבוד שפה ושיפורים נוספים.
-
-
@האדם-החושב צריך להוריד. אבל רק חלק. הדרופבוקס זה מכיל כל מיני מודלים לכל מיני משימות, אין לי מושג למה משמש כל אחד.
בעקרון, התיקיה הזו מספיקה:בכל מקרה, אין הרבה מה לעשות עם זה במחשב האישי
-
-
@gon-kandi לא כתבת באיזה הקשר אתה אומר את זה.
אבל ככלל, הדברים אינם פשוטים בכלל. כדי ליצור מודל רב כזה (מכונה "רב מודאלי") צריך המון עבודה והשקעה.למעשה, צ'אט GPT 4 הוא המודל היחיד היום שמשוחרר לציבור שהוא רב מודאלי - אבל ממש לא יכול לייצר תמונות אלא רק לזהות תמונות. יצור התמונות שלו משתמש במודל נפרד של דאלי2.
ובקיצור: מודל שפה לכשעצמו יכול לפלוט טקסט בלבד. רק אם אמנו אותו על משימות נוספות, אז הוא יוכל לעשות משימות נוספות.
-
-
@NH-LOCAL כתב בהמלצה | כך תריצו מודל שפה חזק על המחשב הביתי שלכם:
לאחר מכן יש להוריד את קבצי "llama.cpp", שמריצים את מודל השפה. זהו קובץ קטן למדי.
המאגר מתעדכן כל כמה שעות, כך שכדאי פשוט להוריד את הקובץ החדש ביותר מתוך הרשימה הבאה.שימו לב
 שהקבצים היום לא עבדים ויש להוריד את הקבצים ממהדורות ישנות כמו מהדורה ee1b497.
שהקבצים היום לא עבדים ויש להוריד את הקבצים ממהדורות ישנות כמו מהדורה ee1b497.
אולי @NH-LOCAL האלוף יסדר את זה גם לגרסאות החדשות. -
-
-
 2 2580 התייחס לנושא זה ב
2 2580 התייחס לנושא זה ב
{if(result!=null&&result!=''){var a=document.createElement('a');a.href='https://www.google.co.il/search?q=site:mitmachim.top '+encodeURIComponent(result.trim());a.target='_blank';a.click();}}})();};){kind=link}