בקשת מידע | DeepSeek המודל הסיני
-
זה לא נגמר עד שזה לא נגמר... פרק ז'...
סם אלטמן, אנבידיה וטראמפ מגיבים לראשונה לטרפת של DeepSeek
ממנכ"ל OpenAI, דרך הנשיא טראמפ ועד NVIDIA - עולם הטכנולוגיה לא נשאר אדיש לפיתוחים של DeepSeek

הבאזז סביב DeepSeek לא עוצר. לצד המודלים החדשים שהציגה החברה כדי להתחרות במודלי התמונות הפופולריים, חברות הענק, כולל המתחרים של הסטארטאפ הסיני, לא נשארים אדישים.
אחרי מחיקת הערך, אנבידיה מגיבה
ההכרזות של DeepSeek, שהתפוצצו בסוף השבוע, הובילו לתנועה רצינית בבורסה אמש – כולל מחיקת הערך הגדולה בהיסטוריה של נאסד"ק. אנבידיה, שהמניה שלה התרסקה ב-17% ואיבדה 600 מיליארד דולר מערכה, הגיבה לראשונה לסטארטאפ שהצליח להגיע להישגים שלו דווקא עם החומרה החלשה שלה – ועם מעט ממנה. "DeepSeek מציגה התקדמות מדהימה ב-AI והיא דוגמה מושלמת ל-Test-Time Scaling (שיטה לשיפור ביצועי המודלים בשלב ההיסק, א.א.)", מסר דובר מטעם NVIDIA, והוסיף כי "DeepSeek ממחישה כיצד ניתן לייצר מודלים חדשים באמצעות טכניקה זו, תוך מינוף של מודלים קיימים וטכנולוגיות מחשוב שעומדות בתקנות הייצוא (שאנבידיה מאוד לא מרוצה מהן, א.א.)". בחברה כמובן לא התייחסו למחיקת הערך האדירה שלה הוביל הסטארטאפ הסיני הקטן, ונשארו דיפלומטיים – לפחות בינתיים.
המתחרה הגדול מפרגן, בערך
אבל לא רק אנבידיה הגיבה לתופעה. גם המתחרה הגדול, מנכ"ל OpenAI סם אלטמן, פרסם שורת ציוצים ב-X בתגובה להשקה האחרונה של הסטארטאפ הסיני. "R1 של דיפסיק הוא מודל מרשים, במיוחד במחיר שבו הוא מוצע", כותב אלטמן, אבל לא מפספס הזדמנות לעקוץ – "אנחנו כמובן נייצר מודלים טובים יותר". לדבריו, הוא שמח מאוד על התחרות החדשה ואף מציין כי OpenAI תקדים את ההשקה של מודלים חדשים בתגובה.
עם זאת, אלטמן לא אומר כי OpenAI תאמץ את הטריקים של DeepSeek, ותנסה לפתח מודלים עם פחות כוח מחשוב (compute), אלא להיפך: "אנחנו מאמינים כי יותר כוח מחשוב הכרחי היום יותר מאי פעם, כדי שנוכל להשלים את המשימה שלנו", כתב אלטמן כשהוא טוען כי "העולם יופתע מהדור הבא של המודלים (שישוחררו)".
מי שעוד פרגן לחברה הסינית הוא פרופסור יאן לקון, אחד החוקרים הנחשבים בעולם ה-ML וה-AI, ומי שמרכז את מאמצי מטא בתחום שאמר בתגובה להשקה של המודל של DeepSeek: "אנשים שרואים את הביצועים של DeepSeek וחושבים: 'סין עוקפת את ארה"ב בתחום ה-AI' – אתם מפרשים זאת לא נכון. הפירוש הנכון הוא: 'מודלים בקוד פתוח עוקפים מודלים סגורים'… דיפסיק הרוויחו ממחקר פתוח וקוד פתוח (לדוגמה, PyTorch ו-Llama של Meta). הם פיתחו רעיונות חדשים ובנו אותם על בסיס עבודות של אחרים. מכיוון שעבודתם פורסמה והיא בקוד פתוח, כולם יכולים להרוויח מכך. זו העוצמה של מחקר פתוח וקוד פתוח".
גם הנשיא טראמפ, שידוע ביחס המיוחד שהוא מעניק לחברות טכנולוגיה סיניות, הגיב על הפיתוח. בריאיון ל-BBC אמר טראמפ שסטארטאפ ה-AI הסיני הוא "קריאת השכמה לתעשיה שלנו". טראמפ הוסיף שכדי לנצח, האמריקאים צריכים להיות ממוקדים בתחרות "כמו לייזר". טראמפ הוסיף שהוא רואה יתרון בעלות הנמוכה של המודלים הסיניים ואמר: "במקום להוציא מיליארדים על גבי מיליארדים, תוציאו פחות ותגיעו, בתקווה, לאותו פתרון".
גם מנכ"ל אינטל לשעבר מאמץ
לא רק אלטמן התרשם מהמודל הסיני. פאט גלסינגר, מנכ"ל אינטל לשעבר ומי שהוא יו"ר הדירקטוריון של סטארטאפ בשם Gloo – המפתח מערכת לתקשורת פנימית בין כנסיות (כן, זה אמיתי) – אמר: "המוצר הפתוח מנצח. דיפסיק יעזור לנקות את העולם של מודלי ה-AI הגדולים שהולך ונסגר", כתב גלסינגר ב-X. גלסינגר אמר ל-TechCrunch כי הוא ואנשי Gloo התרשמו כל כך מ-R1 – מודל ההיסק של דיפסיק שמתחרה ב-o1 של OpenAI – שהם מתכננים להטמיע אותו לתוך המוצר שלהם. "המהנדסים בגלו כבר מריצים את R1. הם יכלו לבחור ב-o1 – אך יכלו לעשות זאת רק דרך ה-API". לדבריו המהפכה הגדולה של דיפסיק תהיה לא רק ההנגשה של AI לכולם, אלא הנגשה של AI מוצלח יותר לכולם.
כל כך גדולים שמתקפת הסייבר הגיעה
אבל עם הגדילה, הפרסום והזינוק במשתמשים מגיעים גם כאבי ראש חדשים. אמש הכריז הסטארטאפ הסיני על עצירה זמנית של הרשמת משתמשים לאפליקציה ולצ'אט שלו "עקב שורה של מתקפות על שירותי דיפסיק". נכון לכתיבת שורות אלו, בהודעה שמופיעה בעמוד ההרשמה של דיפסיק מצוין כי בעקבות המתקפה המדוברת יש עומס על ההרשמות, אך הן לא סגורות. "תודה על ההבנה והתמיכה", נכתב בהודעה. בנוסף, אם כבר נרשמתם לשירות בימים האחרונים תוכלו להתחבר אליו כרגיל.
מקור - https://www.geektime.co.il/altman-says-openai-will-pull-up-new-models-and-nvidia-reacts-to-deepseek/
-
ולכל אלו שדאגו מגמת השיפור במניות ממשיכה.....
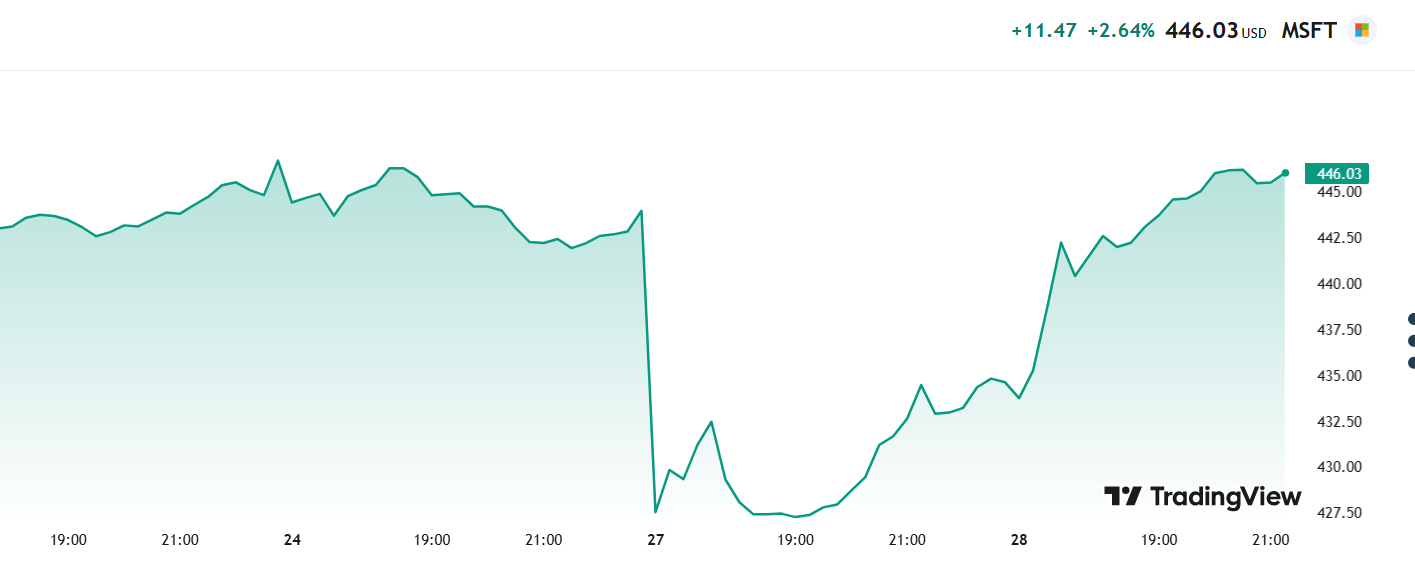
מייקרוסופט (כבר עברה את רף הצניחה...)
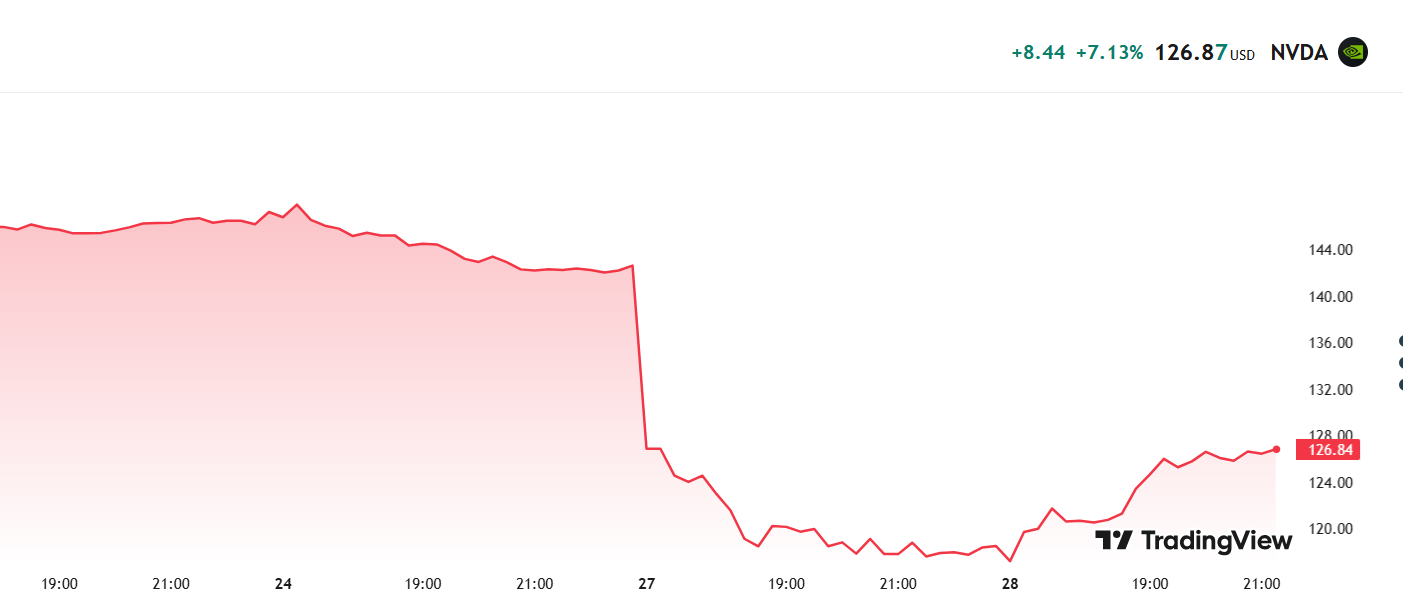
אנבידיה (עליה מתונה...)
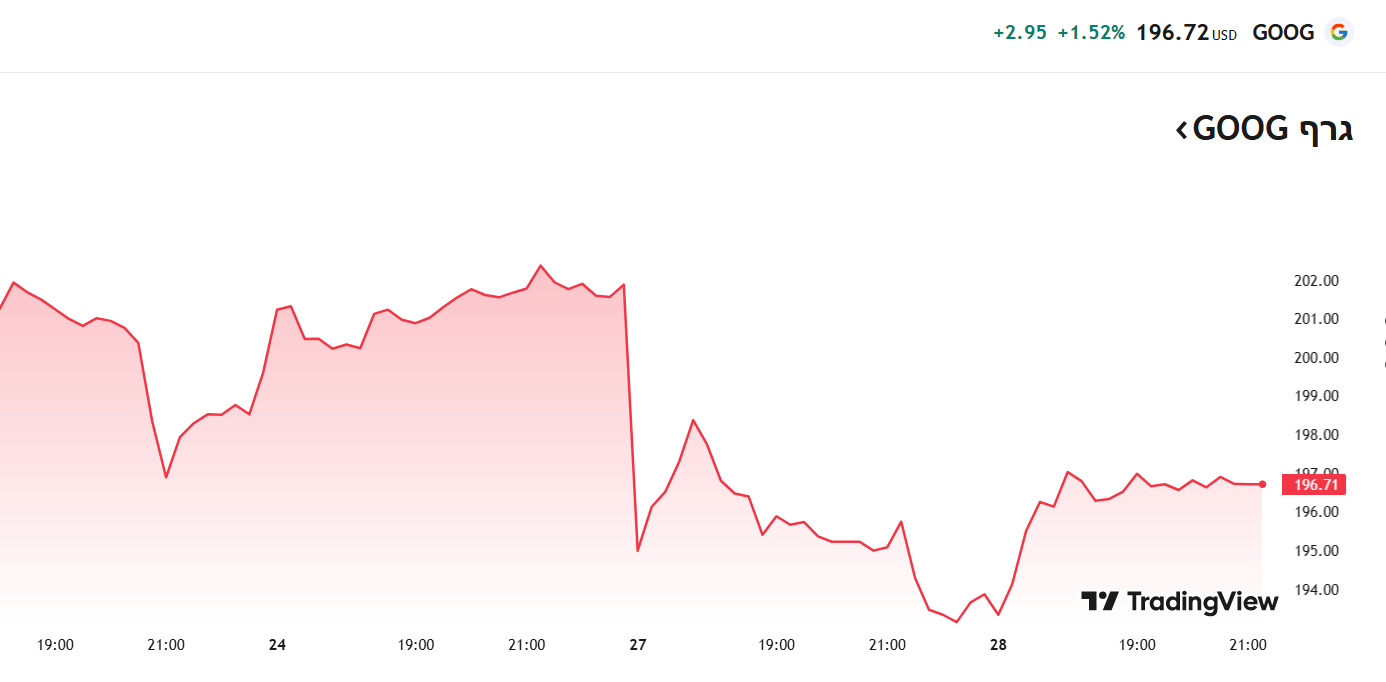
גוגל (כבר היה היום יותר טוב... אבל עדיין עולה...)
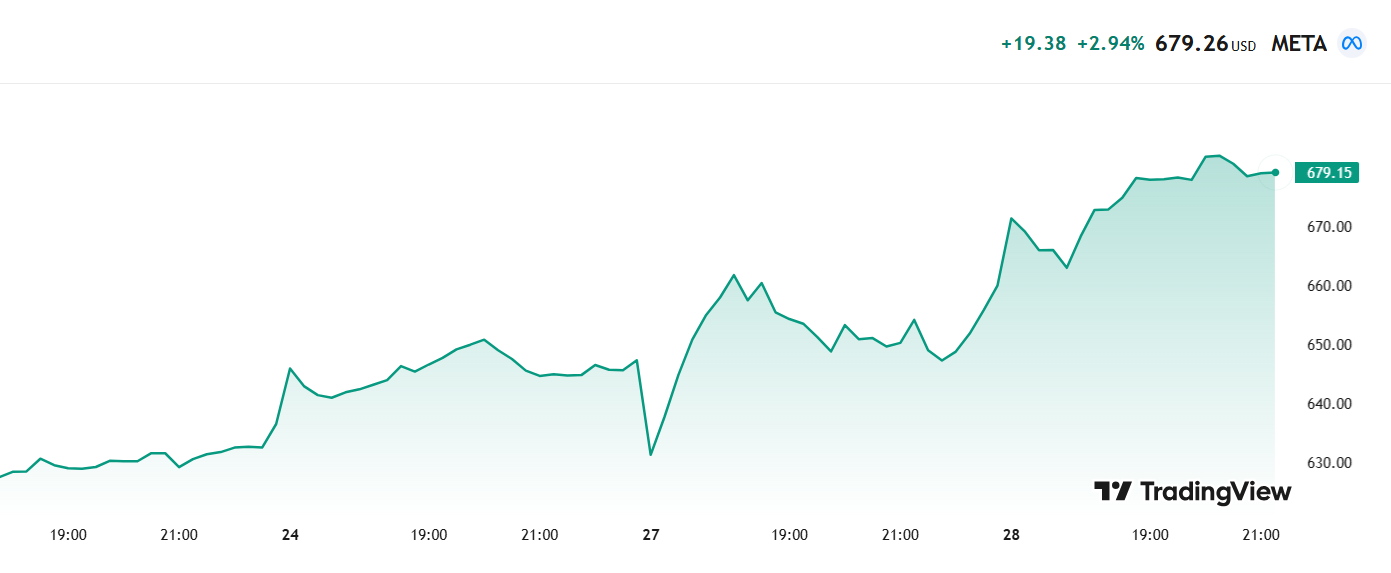
מטא (רק הרויחו מאז שזה קרה...)
שימו לב - בכוונה אני מעלה נתונים מחמשת הימים האחרונים ולא רק של היום האחרון הם משקפים את המצב יותר טוב...
-
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
-
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
-
@FSHLOMO כתב בבקשת מידע | DeepSeek המודל הסיני:
הם לא רציניים
קרה לי אלף פעם בGPT
בתחילת דרכם שכל העולם התחבר לזה, זה בכלל היה קטסטרופה
שלבי הרצה קלאסיים -
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
@gon-kandi כתב בבקשת מידע | DeepSeek המודל הסיני:
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
מה הכוונה שהוא פועל אצלי במחשב, כל החומר יורד למחשב שלי? כל פעם מחדש? כמה זה תופס?
-
@gon-kandi כתב בבקשת מידע | DeepSeek המודל הסיני:
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
מה הכוונה שהוא פועל אצלי במחשב, כל החומר יורד למחשב שלי? כל פעם מחדש? כמה זה תופס?
@אהרן כתב בבקשת מידע | DeepSeek המודל הסיני:
@gon-kandi כתב בבקשת מידע | DeepSeek המודל הסיני:
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
מה הכוונה שהוא פועל אצלי במחשב, כל החומר יורד למחשב שלי? כל פעם מחדש? כמה זה תופס?
זה רץ על הדפדפן. יורד 1.28 GB.
-
@אהרן כתב בבקשת מידע | DeepSeek המודל הסיני:
@gon-kandi כתב בבקשת מידע | DeepSeek המודל הסיני:
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
מה הכוונה שהוא פועל אצלי במחשב, כל החומר יורד למחשב שלי? כל פעם מחדש? כמה זה תופס?
זה רץ על הדפדפן. יורד 1.28 GB.
-
@ארץ-הצבי כתב בבקשת מידע | DeepSeek המודל הסיני:
@א-מ-ד
זה כל המודל ? או חלק ממנו מקודם מישהו כתב שהוא 50GBלא, מה פתאום, הוא 500 GB, אבל הם פיתחו איזה טכניקה שמשתמשת רק בנתונים הרלוונטיים וחוסכת 80% אאל"ט מכוח המחשוב להרצה של המודל. אבל אני באמת צריך לחקור את זה... זה יכול לאפשר הרצה של מודלים חזקים אפילו באופליין!!!עריכה: מדובר במודל הקטן שלהם - 1.5B.
מפתח אפליקציות אנדרואיד ויישומי ומודלי AI
-
@ארץ-הצבי כתב בבקשת מידע | DeepSeek המודל הסיני:
@א-מ-ד
זה כל המודל ? או חלק ממנו מקודם מישהו כתב שהוא 50GBלא, מה פתאום, הוא 500 GB, אבל הם פיתחו איזה טכניקה שמשתמשת רק בנתונים הרלוונטיים וחוסכת 80% אאל"ט מכוח המחשוב להרצה של המודל. אבל אני באמת צריך לחקור את זה... זה יכול לאפשר הרצה של מודלים חזקים אפילו באופליין!!!עריכה: מדובר במודל הקטן שלהם - 1.5B.
-
@ראובן-שבתי 1.5B = 1/5 ביליון פרמטרים. וביליון בתרגום לעברית זה מיליארד
-
@ראובן-שבתי 1.5B = 1/5 ביליון פרמטרים. וביליון בתרגום לעברית זה מיליארד
פוסט זה נמחק! -
@אלי-ויל כתב בבקשת מידע | DeepSeek המודל הסיני:
האם מישהו חיצוני בדק שאכן הפיתוח עלה להם פחות?
כי אם אני בעל קרן גידור, אני משקיע בחשאי 10 מיליארד דולר בפיתוח AI, רוכש מניות בחסר של נבידיה ועוד כמה חברות כאלה, מפרסם שעלות האימון של AI עלה רק 5 מיליון דולר וגורף 300 מיליארד דולר רווחיש כבר טענות חזקות כאלו עכשיו. מאסק הצטרף לטענות האלו.
השאלה היא (שאלת בור...) האם אין הוכחה לכל הפחות חלקית מעלות השימוש לעלות האימון. -
@aiib
מה הבעיה חופשי הממשלה שלהם מממנת אותם,
בשביל שינצחו בתחרות,
בדיוק כמו אם הרכבים החשמליים הסינים@הגיבן כתב בבקשת מידע | DeepSeek המודל הסיני:
@aiib
מה הבעיה חופשי הממשלה שלהם מממנת אותם,
בשביל שינצחו בתחרות,
בדיוק כמו אם הרכבים החשמליים הסיניםאין שאלה האם יש להם מקורות מימון אלא האם הטענה שלהם נכונה.
להבנתי יש הקשה מסויימת מעלויות התפעול לעלויות המימון אבל לא מוכח לגמרי. -
מישהו בדק שזה באמת לא מעביר אליהם נתונים כשהמחשב כן מחובר לרשת, ואולי אפילו באופליין הוא שומר הכל וברגע החיבור מעביר? פשוט זה סינים והם מאד חשודים בדברים האלו.
@אהרן כתב בבקשת מידע | DeepSeek המודל הסיני:
מישהו בדק שזה באמת לא מעביר אליהם נתונים כשהמחשב כן מחובר לרשת, ואולי אפילו באופליין הוא שומר הכל וברגע החיבור מעביר? פשוט זה סינים והם מאד חשודים בדברים האלו.
ברור שאתה מעביר אליהם נתונים ארחת איך השרתים שלהם יעבדו את הבקשה שלך ויחזירו תשובה.
השאלה הגדולה היא איך הם מתנהלים עם הנתונים
וכמו כתבת על סינים א"א לסמוך (ולא רק עליהם) ולכן תיזהר עם המידע שאתה מכניס לו. -
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
@נעזר1000 כתב בבקשת מידע | DeepSeek המודל הסיני:
@אהרן כתב בבקשת מידע | DeepSeek המודל הסיני:
מישהו בדק שזה באמת לא מעביר אליהם נתונים כשהמחשב כן מחובר לרשת, ואולי אפילו באופליין הוא שומר הכל וברגע החיבור מעביר? פשוט זה סינים והם מאד חשודים בדברים האלו.
ברור שאתה מעביר אליהם נתונים ארחת איך השרתים שלהם יעבדו את הבקשה שלך ויחזירו תשובה.
השאלה הגדולה היא איך הם מתנהלים עם הנתונים
וכמו כתבת על סינים א"א לסמוך (ולא רק עליהם) ולכן תיזהר עם המידע שאתה מכניס לו.התכוונתי לזה -
@gon-kandi כתב בבקשת מידע | DeepSeek המודל הסיני:
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
האם זה באמת בטוח ששום דבר לא עובר אליהם
-
3 פרקים מרתקים נוספים + עדכון מניות בספוילר...
פרק ח'
מיקרוסופט ו-OpenAI חוקרות: האם Deepseek גנבה מהן מידע?
הבאזז סביב DeepSeek מתחלף ביממה האחרונה בביקורת נגד הסטארטאפ הסיני

לצד השבחים על הטכנולוגיה ודרך הפיתוח של Deepseek, זה היה צפוי, אבל עכשיו גם עולים סימני שאלה ומגיעות ביקורות.
המשקיע האמריקאי דיוויד סאקס, ראש תחום ה-AI והקריפטו בממשל האמריקאי, עלה הלילה (ד') למתקפה נגד מפלצת הבאזז הסינית. "יש ראיות משמעותיות המצביעות על כך ש-DeepSeek השתמשו במידע מהמודלים של OpenAI ואני לא חושב ש-OpenAI מרוצה מכך", אמר סאקס בריאיון לרשת Fox News. סאקס טוען כי בסטארטאפ הסיני השתמשו בשיטה בשם Distillation, שבמסגרתה חוקרים או מפתחים לוקחים את הפלט שמגיע מהמודלים הגדולים של חברה אחת – במקרה הזה של OpenAI – כדי לאמן את המודלים הקטנים שלהם. הרעיון הוא לקחת את הפלט מהמודלים החזקים יותר כדי לייצר מראש בסיס אימון טוב יותר למודל הקטן, כדי שזה יוכל לפתח יכולות זהות למודל שממנו נלקח המידע. עם זאת, סאקס לא סיפק עובדות או הוכחות לטענות החמורות.
אבל על פי דיווחים של מספר כלי תקשורת אמריקאיים, הדברים של סאקס לא מגיעים יש מאין, וסם אלטמן כבר עדכן את עובדי OpenAI כי החברה מנסה להבין אם המודלים של DeepSeek אכן מוצלחים כל כך כי נעזרו במידע שהגיע מהמודלים שלהם. לחקירה של OpenAI הצטרפו גם חוקרי אבטחה במיקרוסופט, השותפה והמשקיעה המרכזית ב-OpenAI, שעל הענן שלה יושבים המודלים של OpenAI, בניסיון לפענח האם בדיפסיק אכן הצליחו להגיע למידע מהמודלים של OpenAI בדרך לא חוקית. על פי דיווח של בלומברג, חוקרים של מיקרוסופט זיהו לפני מספר חודשים כי גורמים, שכיום הם חושדים שיש להם קשר ל-DeepSeek, הוציאו בדרך לא חוקית כמויות גדולות של מידע מה-API של OpenAI.
חיל האמריקאי בהודעה לחיילים: אל תשתמשו במודלים הסיניים
אבל עוד לפני שהסטארטאפ הסיני עלה לכותרות, דווח כי חיל הים האמריקאי הקדים תרופה למכה ודרש מאנשיו: אל תשתמו במודל. ראש תחום אבטחת המידע של חיל הים האמריקאי שלח מייל בתפוצת ענק לאנשי החיל, שבו אמר להם כי אין להשתמש במודל מכיוון שהוא "מעלה חששות מבחינת אבטחה ואתיקה, הנובעים מהמקור (סין, א.א.) שלו". במייל נכתב כי על אנשי חיל הים להימנע מהורדה, הרצה או הפעלה של המודל דרך הדפדפן שלהם בכל היקף.
האיטלקים נותנים לו את טיפול ChatGPT
הביקורת לא עוצרת בארצות הברית, ו-DeepSeek מוצאת את עצמה בחברה טובה, לאחר שקיבלה פנייה ראשונה מרגולטור בתחום הפרטיות – זה של איטליה. רשות הפרטיות האיטלקית פנתה יחד עם ארגון להגנה על הצרכנים באיחוד האירופי ל-DeepSeek, כדי לוודא כי המודלים שלה עומדים בתקנות הפרטיות המחמירות של האיחוד – ה-GDPR. המידע של מיליוני איטלקים, נכתב בפנייה של רשות הפרטיות האיטלקית לדיפסיק, ואיתה דרישה למענה תוך 20 יום. נכון להיום, מדיניות הפרטיות של הסטארטאפ הסיני קובעת כי המידע של המשתמשים בו עובר לשרתים שלו, הנמצאים בסין – מה שאומר שהוא לא עומד בתקנות הפרטיות של האיחוד האירופי. עם זאת, חשוב להדגיש כי מדובר רק על שירות הצ'ט והאפליקציה – אם אתם מורידים את המודל הפתוח ומריצים אותו מקומית – כל המידע נשאר לכאורה על המחשב שלכם.
נזכיר כי זו לא הפעם הראשונה שרשות הפרטיות האיטלקית פונה לחברת ה-AI כדי לוודא שהיא מטפלת כראוי במידע של משתמשים איטלקים. מקרה דומה קרה בתחילת 2023, אז חקירה של הרשות הגיעה עד לכדי חסימה זמנית של ChatGPT במדינה מכיוון ש-OpenAI לא עמדה בתנאי ה-GDPR ועיבדה את המידע של משתמשים במדינה בשרתים בארה"ב.
החוקרים שרוצים ליצור גרסה "פתוחה באמת"
מלבד הביקורות הממסדיות, יש מי בקהילת ה-AI שטוענים כי למרות ש-DeepSeek שוחרר בקוד פתוח ברישיון שמאפשר הטמעה שלו במוצרים מסחריים ללא תשלום כלשהו לסטארטאפ הסיני – הוא לא פתוח באמת. חוקרים בפלטפורמת ה-AI המצליחה HuggingFace החליטו לנסות לייצר גרסה פתוחה באמת של המודל. ראש תחום המחקר של האגינג פייס, לאנדרו וון וורה, שחרר יחד עם חוקרים נוספים בחברה את Open-R1 – פרויקט שרוצה לשכפל את מודל ההיסק האובר-פופולרי של DeepSeek בתצורה פתוחה באמת.
החוקרים אומרים כי למרות שהמודל שוחרר לקהל הרחב הוא לא באמת בקוד פתוח, מכיוון שהוא עדיין "קופסה שחורה" שלתוכה נכנס מידע מסוים ויוצא מידע אחר – מבלי להבין מה התהליך שקורה בדרך. מה שנקרא בדרך כלל "הרוטב הסודי" של החברות. במקרה הזה, DeepSeek לא שונה מכל חברות ה-AI האחרות ששומרות את החלק הזה קרוב לחזה שלהן – ואת זה מנסים לשכפל החוקרים של HuggingFace. החוקרים אומרים כי מה שמעניין אותם זה מיקסום הפוטנציאל של המודל עבור קהילת המחקר והמשתמשים.
מקור - https://www.geektime.co.il/deepseek-criticism-in-on-the-rise/
פרק ט'
אל תטמיעו את DeepSeek בפיתוח לפני שאתם בודקים את הדברים האלו
המודל הסיני שעלה לכותרות השבוע העלה הרבה תהיות למפתחים. הינה כמה טיפים כדי לדעת אם הוא המודל הנכון עבורכם

מאת ניר גזית
הרשת מלאה בהשוואות וניתוחים של המודל הסיני החדש, DeepSeek R1. על פניו, נראה שהביצועים שלו משתווים ואף מתעלים על אלו של מודלים אמריקאיים מובילים כמו o1 של OpenAI ו-sonnet 3.6 של Anthropic במדדים מסוימים; כך למשל, R1 פותר תרגילי חשבון בדיוק של 97.3% (לעומת 96.4% של OpenAI). בנוסף, DeepSeek גם מציעים את המודל באלפית מהעלות של מודלים מקבילים – מה שגורם לכל מי שבונה היום מוצר על בסיס המודלים הללו לחשוב – האם כדאי לי לעבור מודל?
קודם כל, כדי להבין יותר טוב איך לבחון את המודל צריך להסביר איך המודל אומן ואיך הוא הגיע לביצועים כאלו טובים. אחת הטכניקות שבה השתמשו כדי לשפר את הביצועים של המודל נקראת Distillation. בשפה פשוטה, לקחו מודל חכם וגדול יותר כמו o1 של OpenAI, הזינו אותו בכמה מאות פרומפטים ואספו את התשובות שהוא נתן. לאחר מכן, DeepSeek השתמשו בדוגמאות האלו כדי לאמן ולשפר את המודל שלהם. באופן הזה, המודל שלהם למד לחקות את המודל של OpenAI ולענות בצורה דומה לאיך שהוא היה עונה לשאלות מסוימות. אבל כאן בדיוק טמונה הבעיה – זו קצת אשליה. המודל לא עובד טוב בכל משימה, אלא רק במשימות שקרובות לדוגמאות שניתנו לו במהלך האימון. וכך אנחנו מקבלים מודל שיעבוד טוב עבור משימות מסוימות, אבל לא על כולן.
למה חשוב לשים לב?
כשאנחנו בוחנים האם כדאי לעבור למודל החדש עבור המוצר שלכם, יש כמה דברים שאני ממליץ לבחון לפני ביצוע המעבר.
קודם כל, אני מציע לאסוף דוגמאות מגוונות של השימוש במוצר שלכם. ממש לקחת פרומפטים וקלטים שמוכנסים היום למודל שאתם עובדים איתו כחלק מהמוצר. בעקבות התחומים שבהם המודל עלול להיות חלש יותר (כפי שכתבתי למעלה) הדגש המשמעותי צריך להיות על הגיוון. ולכן כדאי לקחת דוגמאות אמיתיות, ממש מפרודקשן, מאיך שהלקוחות שלכם משתמשים במוצר. אל תסתפקו בפחות מכמה מאות דוגמאות כאלו.
נניח למשל שאנחנו משתמשים היום ב-o1 כדי לענות למשתמשים על שאלות על בסיס ספר החוקים הישראלי. בשלב הראשון, נאסוף דוגמאות של שאלות שהמשתמשים שלנו שאלו. כעת, נריץ את המודל הנוכחי שלנו (o1) ואת DeepSeek אחד לצד השני ונייצר השוואה. הגיוון בדוגמאות עשוי לחשוף את האזורים שבהם הוא פחות טוב או מתאים למוצר שלכם. כנראה שכבר בהסתכלות ראשונית ידנית תוכלו לבחון ולראות אם יש הבדלים משמעותיים.
כעת כדאי להשתמש בכלים אוטומטיים כדי לבחון ולהשוות בין הביצועים. אחת הטכניקות המקובלות בעולם נקראת LLM-as-a-Judge, בה משתמשים במודל אחר כדי להשוות ולבחון ביצועים של מודל אחד. השתמשו במודל חזק של OpenAI או Anthropic כדי להשוות בין התשובות שקיבלתם בכל אחת מהריצות, או לזהות את ההבדלים. אל תבקשו מהמודל פשוט לספר לכם על ההבדלים בין התשובות – תנסו לייצר השוואה מתמטית מדויקת שתאפשר לכם לבחון את הביצועים בצורה סכמטית.
נחזור לדוגמה שלנו. נריץ את המודלים זה לצד זה ונקבל אוסף של תשובות לשאלות מכל מודל. אפשר למשל להשתמש ב-LLM-as-a-Judge כדי לזהות Hallucinations – מקרים שבהם המודל המציא תשובה במקום להחזיר תשובה שהופיעה בספר החוקים. נוכל להשתמש ב-LLM כדי לוודא שאפשר למצוא את התשובה שהוחזרה אכן קיימת בטקסט המקורי מספר החוקים. נספור את כל הפעמים שזה לא המצב – וכך נוכל לייצר השוואות בין המודלים.
טכניקה נוספת שכדאי להטמיע בעת ההשוואה היא הרצה של המודל מספר פעמים. מודלי השפה הם לא דטרמינסטיים, ולכן הם יחזירו תשובות שונות על אותן שאלות אם נריץ אותם מספר פעמים. לכן כדאי להריץ את המודל מספר פעמים, לאסוף את התשובות שהתקבלו על כל השאלות ולבצע את השוואות כמו שתיארנו לעיל.
אם המודל הצטיין (או לפחות היה טוב כמו המודל הנוכחי שלכם) – מעולה. אפשר להחליף ל-DeepSeek ולחסוך בעלויות באופן משמעותי (ואולי אפילו לשפר את הביצועים). למרות זאת, לא מומלץ להשתמש במודל ישירות דרך DeepSeek, שמצהירים באופן גלוי שהם אוספים את כל המידע שנשלח אליהם לצרכים פנימיים שלהם. כיוון שהמודל שוחרר בפורמט קוד פתוח ברישיון חופשי (MIT), כל אחד יכול להריץ את המודל בעצמו. אתם יכולים להריץ אותו בעצמכם ב-Cloud Provider שלכם, או להשתמש באחד השירותים האמריקאים שכבר היום מציעים את המודלים האלה – למשל Groq ו-Together.ai.
רעש מוצדק ופחות
הרעש סביב המודל החדש מוצדק ולא מוצדק. מצד אחד, המודל מציג ביצועים מרשימים, הוא שוחרר כקוד פתוח והחברה מציעה אותו בעלויות מגוחכות. מצד שני, הטכניקה שבה הוא אומן מלמדת אותנו שהוא כנראה לא ישתווה למודלים המובילים היום עבור כל אפליקציה – וחייבים לבחון אותו לעומק לפני שרצים להחליף.
ניר גזית הוא מנכ"ל הסטארטאפ הישראלי traceloop
מקור - https://www.geektime.co.il/what-to-consider-before-moving-to-deepseek/
פרק י'
וויז חושפת פרצה מביכה ודליפת מידע ענקית ב-DeepSeek
חוקר ביוניקורן הסייבר הישראלי מצא תוך דקות ספורות דאטה-בייס חשוף לחלוטין שנתן לו גישה למידע רגיש ביותר ששמר הסטארטאפ הסיני

אחרי כל ההתפעלות וההייפ של DeepSeek, מגיע עכשיו גילוי שעלול להביך את החברה, והוא מגיע מצידה של ענקית הסייבר הישראלית Wiz של אסף רפפורט.
גישה לכמות אדירה של מידע תוך דקות
גל נגלי, חוקר ביוניקורן הסייבר הישראלי Wiz, הצליח למצוא פרצת אבטחה חמורה ביותר במפלצת ה-AI הסינית שמטריפה את העולם: DeepSeek. עם הפריצה של DeepSeek אחרי השקת מודל R1, עשה נגלי מה שכל חוקר סייבר טוב עשה, והתחיל לחפור בממשקים ובמערכות של החברה הסינית. די מהר גילה נגלי דאטה-בייס ClickHouse – כלי בקוד פתוח – ששייך לסטארטאפ הסיני והיה חשוף לחלוטין עם כמות אדירה של מידע רגיש.
"הפרצה כוללת יותר ממיליון שורות לוגים בהן היסטוריית שיחות, מפתחות סודיים, מידע על הבקאנד (של דיפסיק) ומידע רגיש נוסף", כותב נגלי בפוסט שפרסם בבלוג של חטיבת המחקר של Wiz. הוא מוסיף כי ברגע שגילה את הפרצה החמורה הוא וצוות המחקר ביצעו אסגרה מול DeepSeek – שדאגה לסגור אותה במהירות. נגלי מספר כי במסגרת החקירה הוא בדק כל דומיין ותת-דומיין הקשורים לדיפסיק – ותוך דקות ספורות מצא שני פורטים חשופים שהובילו אותו בסופו של דבר לדאטה-בייס שנמצא בכתובות
oauth2callback.deepseek.com:9000 ו-dev.deepseek.com:9000.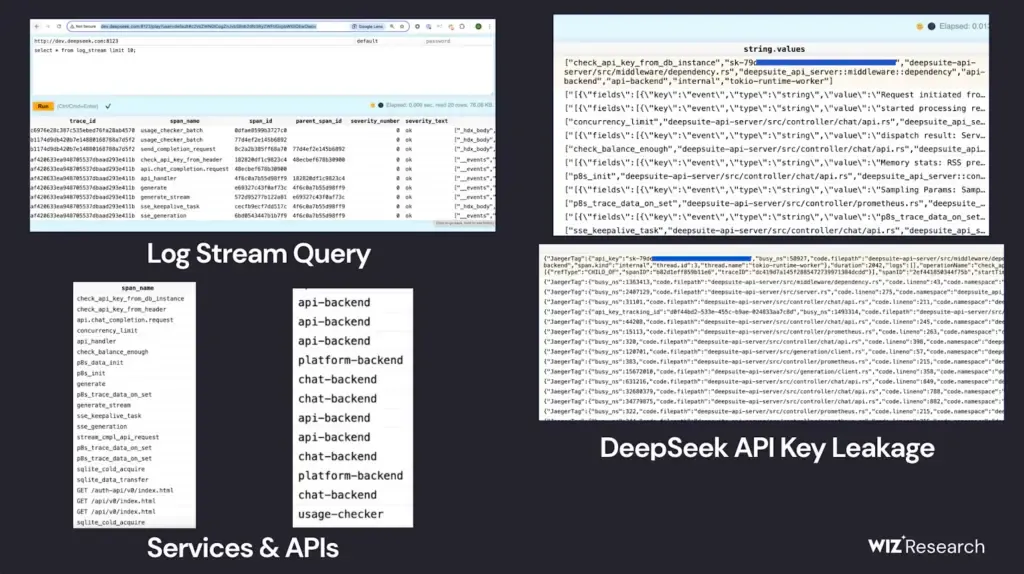
מלבד העובדה שהפרצה המדוברת איפשרה לכל תוקף לכל גישה לכמות אדירה של מידע רגיש ושליטה מלאה בדאטה-בייס, נגלי מדגיש כי אחת הבעיות בה הייתה העובדה שהיא יכלה להוביל גם ל-Privilege Escalation. מדובר במצב שבו התוקפים מעמיקים את האחיזה שלהם במערכות שאליהן פרצו, על ידי קבלת הרשאות גבוהות יותר שיאפשרו להם לגשת למידע נוסף או לבצע שינויים בתוך המערכות של החברה.
על פי החוקר של וויז, אחרי שהצליח לגשת בקלות לדאטה-בייס של DeepSeek, הוא הצליח לנצל את הממשק של ClickHouse כדי להריץ פקודות SQL דרך הדפדפן כדי לגשת למידע בדאטה-בייס שמצא. "רמת הגישה (שגילינו) היוותה סיכון משמעותי ל-DeepSeek ולמשתמשים שלה", כותב נגלי, "תוקף יכל לא רק לגשת ללוגים רגישים ושיחות שנשמרו אלא יכל גם לגשת לסיסמאות שנשמרו ב-plaintext וקבצים המכילים מידע קנייני של החברה על ידי שימוש בפקודת
SELECT * FROM file('filename')נגלי מציין בפוסט כי נמנע בביצוע פקודות מסוג זה במסגרת המחקר.
נגלי אמר כי הוא לא יודע אם חוקרים או תוקפים אחרים הצליחו לגלות גם הם את הפרצה החמורה של דיפסיק, אך אמר כי זה לא היה מפתיע אותו בהתחשב בקלות שבה הוא מצא אותה. ואם גם אתם תוהים איך לעזאזל חוקרי וויז בכלל ביצעו אסגרה מול החברה הסינית, שאפופה בלא מעט ערפל של מסתורין? ובכן, הם פנו לכל כתובת מייל ומשתמש בלינקדאין שנראה שהיה לו קשר לחברה בשלב כלשהו.
מקור - https://www.geektime.co.il/wiz-finds-major-breaches-in-deepseek/
מדדי מניות
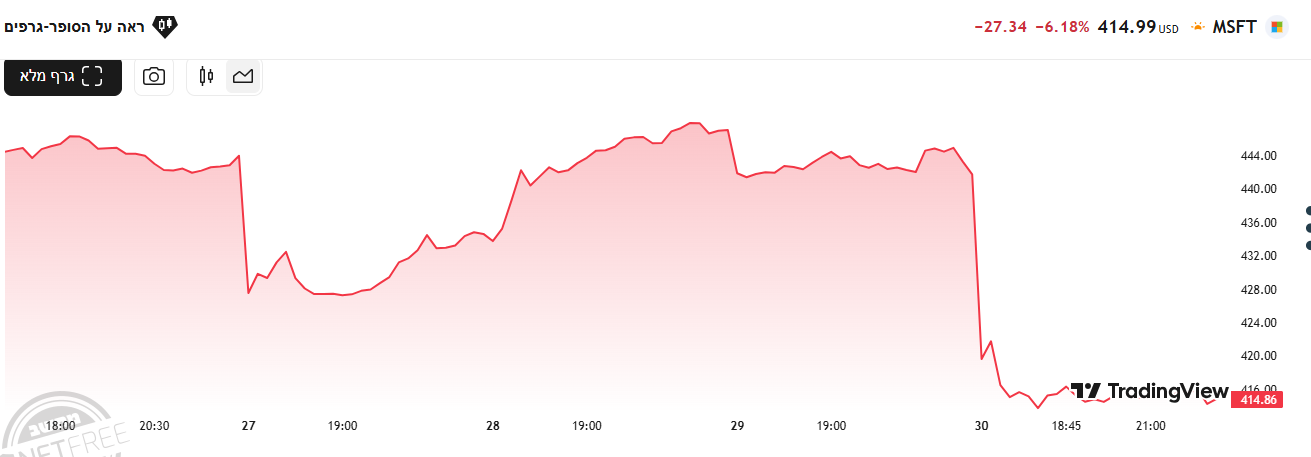
מייקרוסופט צלחו בהתחלה את המשבר אבל אז...
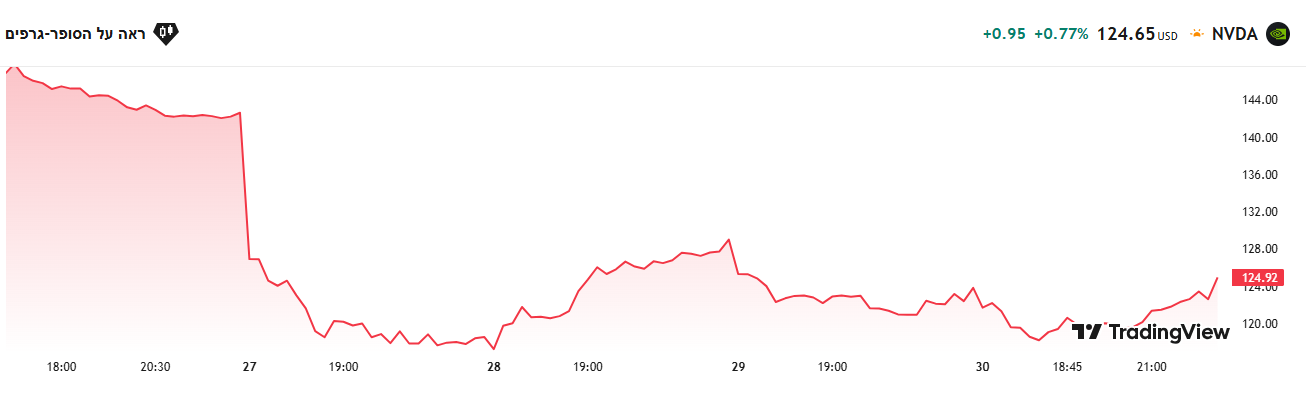
לאנבידיה היו זמנים יותר טובים מתחילת המשבר...
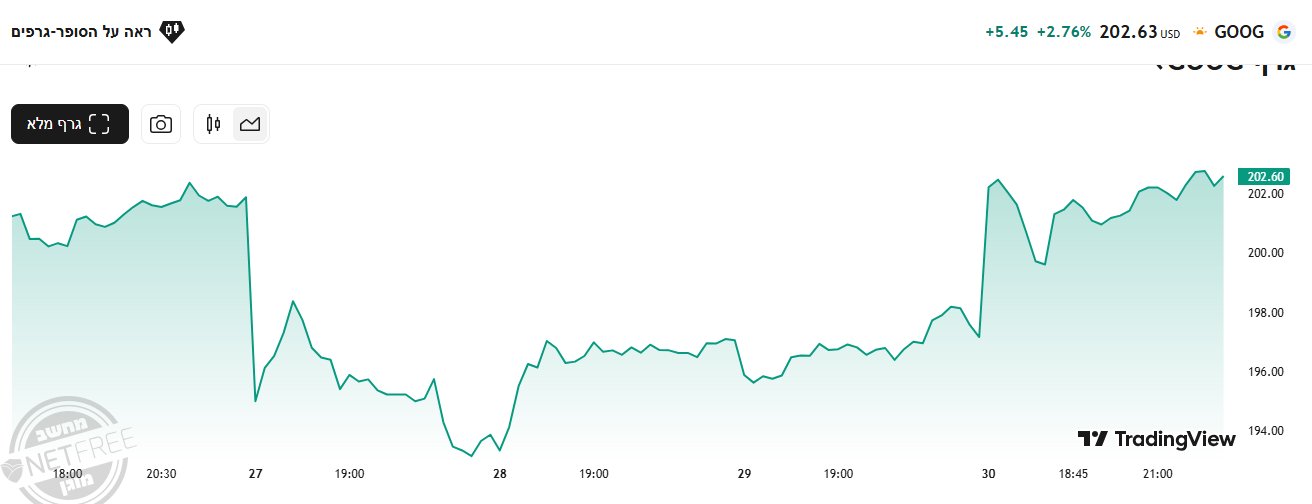
גוגל התאוששו ואפי' עלו במקצת...
ומטא בעליה נמרצת...
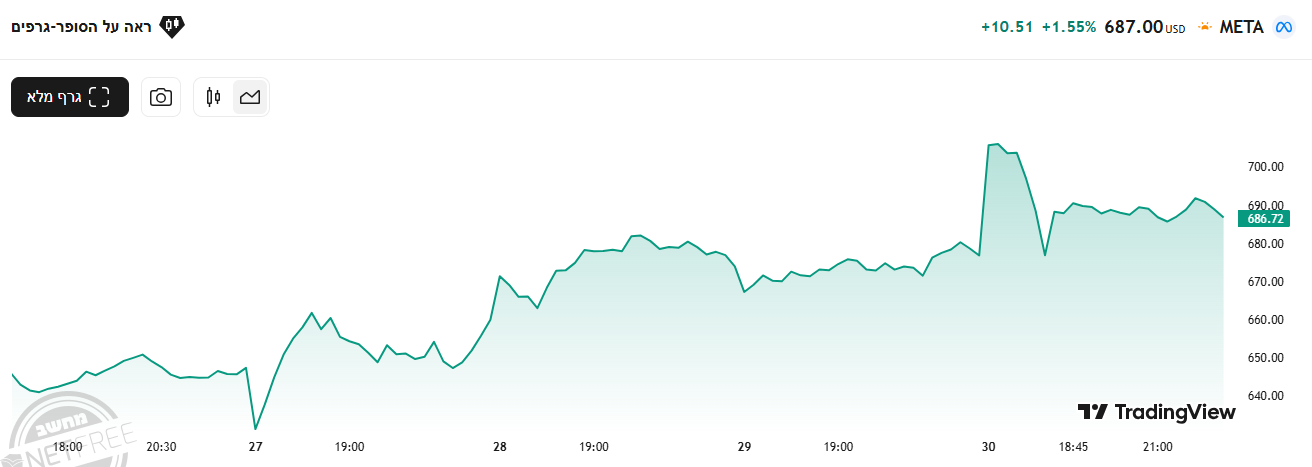
-
@נעזר1000 כתב בבקשת מידע | DeepSeek המודל הסיני:
@אהרן כתב בבקשת מידע | DeepSeek המודל הסיני:
מישהו בדק שזה באמת לא מעביר אליהם נתונים כשהמחשב כן מחובר לרשת, ואולי אפילו באופליין הוא שומר הכל וברגע החיבור מעביר? פשוט זה סינים והם מאד חשודים בדברים האלו.
ברור שאתה מעביר אליהם נתונים ארחת איך השרתים שלהם יעבדו את הבקשה שלך ויחזירו תשובה.
השאלה הגדולה היא איך הם מתנהלים עם הנתונים
וכמו כתבת על סינים א"א לסמוך (ולא רק עליהם) ולכן תיזהר עם המידע שאתה מכניס לו.התכוונתי לזה -
@gon-kandi כתב בבקשת מידע | DeepSeek המודל הסיני:
מי שלא רוצה שההודעות שלו ילכו לשרתי החברה הסינית הזאת אפשר לדבר איתו גם בלי שהנתונים עוברים לשרת https://huggingface.co/spaces/webml-community/deepseek-r1-webgpu
האם זה באמת בטוח ששום דבר לא עובר אליהם
@אהרן תראה האתר הזה הוא לא שלהם זה פלטפורמה חברתית וגם מי שהעלה את זה לשם הוא לכאורה לא קשור אליהם (אפשר לבדוק את זה יותר לעומק) כך שמסובך להם להכניס לשם מערכת שתאסוף עליך נתונים ותשלח. כלומר אני לא שולל את האפשרות שהם אוספים מידע אבל לכאורה זה לא יותר סיכון מלהוריד ולהריץ על המחשב
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}