שיתוף | מרוץ ה-AI מתקדם במהירות האור - OpenAI הציגה את מודל o3
-
@NH-LOCAL כתב בשיתוף | מרוץ ה-AI מתקדם במהירות האור - OpenAI הציגה את מודל o3:
לפני שבועיים בלבד, היא שחררה את מודל o1 המלא ואת מודל o1 pro (בעלות של 200$ לחודש, אבל זה כבר נושא אחר) - שהציגו ביצועים אפילו טובים יותר!
שאתה תשבח את זה?
הם הרסו את O1, והעבירו אותו ל200$*. גם כן שדרוג... זמני המקוואות בק"ס קיבלו שדרוג יותר גדול....*ובמקומו שמו חיקוי עלוב של O1...
@י-פל כתב בשיתוף | מרוץ ה-AI מתקדם במהירות האור - OpenAI הציגה את מודל o3:
שאתה תשבח את זה?
הם הרסו את O1, והעבירו אותו ל200$. גם כן שדרוג... זמני המקוואות בק"ס קיבלו שדרוג יותר גדול....נכון ולא נכון. אני גם מרגיש ככה בחלק מהשימושים, אבל מדד livebench שהוא כנראה אחד האמינים בתחום חושב אחרת.

-
@י-פל כתב בשיתוף | מרוץ ה-AI מתקדם במהירות האור - OpenAI הציגה את מודל o3:
שאתה תשבח את זה?
הם הרסו את O1, והעבירו אותו ל200$. גם כן שדרוג... זמני המקוואות בק"ס קיבלו שדרוג יותר גדול....נכון ולא נכון. אני גם מרגיש ככה בחלק מהשימושים, אבל מדד livebench שהוא כנראה אחד האמינים בתחום חושב אחרת.
@NH-LOCAL כתב בשיתוף | מרוץ ה-AI מתקדם במהירות האור - OpenAI הציגה את מודל o3:
נכון ולא נכון
עובדתית, הוא לא חושב יותר מ4 שניות.
נכון או לא?
אם ענית כן, אז המודל טיפש יותר, ולא מעניינת אותי המציאות [או יותר נכון: המדדים]...גאה להיות חלק:
otzaria.org -
@NH-LOCAL כתב בשיתוף | מרוץ ה-AI מתקדם במהירות האור - OpenAI הציגה את מודל o3:
נכון ולא נכון
עובדתית, הוא לא חושב יותר מ4 שניות.
נכון או לא?
אם ענית כן, אז המודל טיפש יותר, ולא מעניינת אותי המציאות [או יותר נכון: המדדים]... -
אני לא יודע איזה אינטרנט יש לכם אבל ניסיתי התכתבות שני סינונים (על המודל שפתוח לכולם), בסינון רימון תוך שנייה ענה ובנטפרי היה צריך לחשוב קצת
-
אני לא יודע איזה אינטרנט יש לכם אבל ניסיתי התכתבות שני סינונים (על המודל שפתוח לכולם), בסינון רימון תוך שנייה ענה ובנטפרי היה צריך לחשוב קצת
-
קשה להאמין, אבל רק לפני 3 חודשים, פרסמתי את הפוסט הזה על שחרור מודל o1 וכבר מודל o3 הוצג! (על o2 OpenAI פשוט דילגה)
קצת רקע:
מודל o1 הוא מודל שהציגה Openai לפני מספר חודשים, המודל עובד בשיטה חדשה המכונה COT = שרשרת חשיבה. השיטה עובדת כך שהמודל חושב זמן מסויים (בין מספר שניות למספר דקות) עד שהוא עונה תשובה, מה שמקפיץ את ביצועי המודל בתחומים כמו מתמטיקה ותכנות.
בשלב הראשון הציגה החברה את מודל o1, אבל שחררה לציבור (למנויים בלבד) מודל חכם פחות, בשם o1 preview, אם כי גם הוא הציג ביצועים מדהימים כשלעצמו, כתבתי עליהם כאן.
ההתפתחויות האחרונות:
לפני שבועיים בלבד, היא שחררה את מודל o1 המלא ואת מודל o1 pro (בעלות של 200$ לחודש, אבל זה כבר נושא אחר) - שהציגו ביצועים אפילו טובים יותר!
ממש בסוף השבוע האחרון, גוגל שחררה גם היא מודל חשיבה כזה בגרסת בטא. הוא נקרא בשם gemini-2.0-flash-thinking, וניתן לנסות אותו בחינם ב-AI STUDIO
וכעת לתכלס':
אתמול, הציגה החברה את מודל o3 שמציג קפיצת מדרגה מדהימה במבחנים הקשים ביותר
המודל עוד לא שוחרר לציבור, וכפי הנראה גם כשזה יקרה, הוא יעלה כסף. הרבה כסף. מכיוון שהמודל דורש כח עיבוד מטורף עבור כל שאלה.
לא כל הנתונים פורסמו, וגם אני עצמי לא הספקתי לעבור על כולם. אבל הגרף הבא די מספק. מדובר על אחד המדדים הקשים ביותר בתחום, וכדי לסבר את האוזן שימו לב לעובדה הבאה: ל-ARC-AGI-1 לקח 4 שנים לעבור מ-0% עם GPT-3 ב-2020 ל-5% ב-2024 עם GPT-4o.
במילים אחרות - אנחנו נמצאים בתוך עלייה אקספוננציאלית, בקו כמעט ישר כלפי מעלה! במילים אחרות - מהירות ההכפלה של אינטליגנציה מלאכותית היא ההתפתחות הטכנולוגית המהירה ביותר אי פעם משחר ההיסטוריה!
לטעמי, הגרף הזה אמנם לא נותן את התמונה המלאה על התחום, אבל מראה מצויין לאן פנינו מועדות!
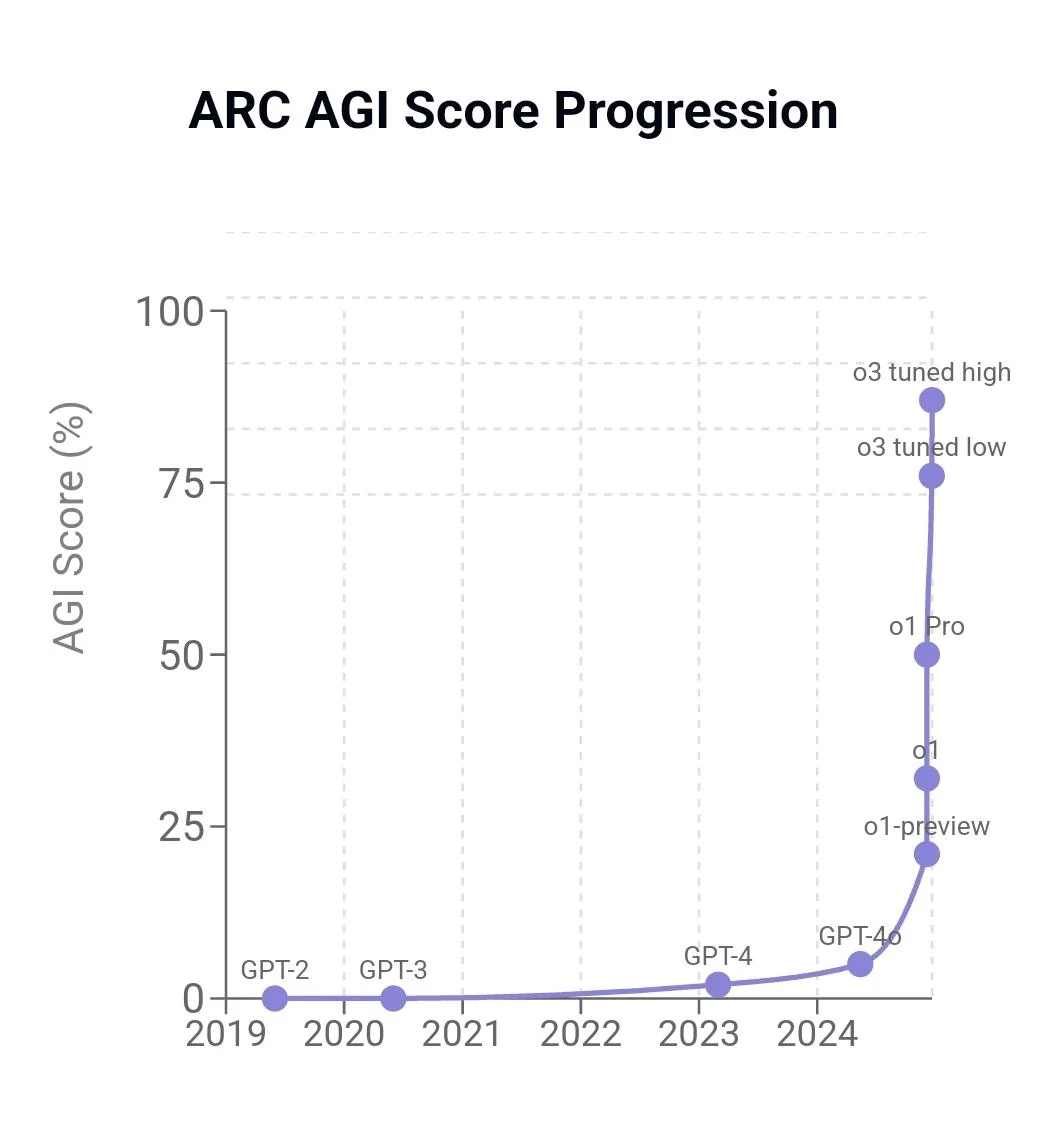
פרטים נוספים בפוסט הרשמי של מדד ARC:
https://arcprize.org/blog/oai-o3-pub-breakthroughלהתראות מתכנתים!

הכי חשוב: תזכרו מי הראשון שזיהה!

הכנסו לבלוג שלי למאמרים וגילויים נוספים
-
קשה להאמין, אבל רק לפני 3 חודשים, פרסמתי את הפוסט הזה על שחרור מודל o1 וכבר מודל o3 הוצג! (על o2 OpenAI פשוט דילגה)
קצת רקע:
מודל o1 הוא מודל שהציגה Openai לפני מספר חודשים, המודל עובד בשיטה חדשה המכונה COT = שרשרת חשיבה. השיטה עובדת כך שהמודל חושב זמן מסויים (בין מספר שניות למספר דקות) עד שהוא עונה תשובה, מה שמקפיץ את ביצועי המודל בתחומים כמו מתמטיקה ותכנות.
בשלב הראשון הציגה החברה את מודל o1, אבל שחררה לציבור (למנויים בלבד) מודל חכם פחות, בשם o1 preview, אם כי גם הוא הציג ביצועים מדהימים כשלעצמו, כתבתי עליהם כאן.
ההתפתחויות האחרונות:
לפני שבועיים בלבד, היא שחררה את מודל o1 המלא ואת מודל o1 pro (בעלות של 200$ לחודש, אבל זה כבר נושא אחר) - שהציגו ביצועים אפילו טובים יותר!
ממש בסוף השבוע האחרון, גוגל שחררה גם היא מודל חשיבה כזה בגרסת בטא. הוא נקרא בשם gemini-2.0-flash-thinking, וניתן לנסות אותו בחינם ב-AI STUDIO
וכעת לתכלס':
אתמול, הציגה החברה את מודל o3 שמציג קפיצת מדרגה מדהימה במבחנים הקשים ביותר
המודל עוד לא שוחרר לציבור, וכפי הנראה גם כשזה יקרה, הוא יעלה כסף. הרבה כסף. מכיוון שהמודל דורש כח עיבוד מטורף עבור כל שאלה.
לא כל הנתונים פורסמו, וגם אני עצמי לא הספקתי לעבור על כולם. אבל הגרף הבא די מספק. מדובר על אחד המדדים הקשים ביותר בתחום, וכדי לסבר את האוזן שימו לב לעובדה הבאה: ל-ARC-AGI-1 לקח 4 שנים לעבור מ-0% עם GPT-3 ב-2020 ל-5% ב-2024 עם GPT-4o.
במילים אחרות - אנחנו נמצאים בתוך עלייה אקספוננציאלית, בקו כמעט ישר כלפי מעלה! במילים אחרות - מהירות ההכפלה של אינטליגנציה מלאכותית היא ההתפתחות הטכנולוגית המהירה ביותר אי פעם משחר ההיסטוריה!
לטעמי, הגרף הזה אמנם לא נותן את התמונה המלאה על התחום, אבל מראה מצויין לאן פנינו מועדות!
פרטים נוספים בפוסט הרשמי של מדד ARC:
https://arcprize.org/blog/oai-o3-pub-breakthroughלהתראות מתכנתים!
הכי חשוב: תזכרו מי הראשון שזיהה!
הכנסו לבלוג שלי למאמרים וגילויים נוספים
@NH-LOCAL לכל המתלהבים אני ממליץ לקרוא את זה: https://pub.towardsai.net/why-openais-o1-model-is-a-scam-eb3356c3d70e
הוא טוען שהטכנולוגיה קיימת כבר שנים ואין כאן חידוש, פשוט קצת עבודה בעיניים. אתה יכול לגרום לכל מודל לחשוב. אז בוודאי שזה לא מודל חדש, זה סה''כ מנגנון מעל המודל. והרעיון ה"מהפכני" הוא לאמן אותו על הבנצ'מארקים עצמם, כדי להטות את התוצאות.
-
@NH-LOCAL לכל המתלהבים אני ממליץ לקרוא את זה: https://pub.towardsai.net/why-openais-o1-model-is-a-scam-eb3356c3d70e
הוא טוען שהטכנולוגיה קיימת כבר שנים ואין כאן חידוש, פשוט קצת עבודה בעיניים. אתה יכול לגרום לכל מודל לחשוב. אז בוודאי שזה לא מודל חדש, זה סה''כ מנגנון מעל המודל. והרעיון ה"מהפכני" הוא לאמן אותו על הבנצ'מארקים עצמם, כדי להטות את התוצאות.
@sivan22 כתב בשיתוף | מרוץ ה-AI מתקדם במהירות האור - OpenAI הציגה את מודל o3:
@NH-LOCAL לכל המתלהבים אני ממליץ לקרוא את זה: https://pub.towardsai.net/why-openais-o1-model-is-a-scam-eb3356c3d70e
הוא טוען שהטכנולוגיה קיימת כבר שנים ואין כאן חידוש, פשוט קצת עבודה בעיניים. אתה יכול לגרום לכל מודל לחשוב. אז בוודאי שזה לא מודל חדש, זה סה''כ מנגנון מעל המודל. והרעיון ה"מהפכני" הוא לאמן אותו על הבנצ'מארקים עצמם, כדי להטות את התוצאות.
והוא https://arcprize.org/blog/oai-o3-pub-breakthrough טוען שבאמת אין הוספה של נתונים לאימון, אלא שימוש בטכנולוגיות כאלו ואחרות.
כמעט כל רעיון חדש אינו טכנולוגיה חדשה, אלא מימוש שלה, לא? -
@NH-LOCAL לכל המתלהבים אני ממליץ לקרוא את זה: https://pub.towardsai.net/why-openais-o1-model-is-a-scam-eb3356c3d70e
הוא טוען שהטכנולוגיה קיימת כבר שנים ואין כאן חידוש, פשוט קצת עבודה בעיניים. אתה יכול לגרום לכל מודל לחשוב. אז בוודאי שזה לא מודל חדש, זה סה''כ מנגנון מעל המודל. והרעיון ה"מהפכני" הוא לאמן אותו על הבנצ'מארקים עצמם, כדי להטות את התוצאות.
@sivan22 אתה יודע מה מצחיק בכל מפקפקי ה-AI למיניהם? שתוך כמה חודשים הם נאלצים לבלוע את הלשון או לאכול את הכובע, פשוט בגלל שמודל חדש שיוצא שובר את התאוריות הקודמות שלהם.
זה התחיל במחקר מעמיק שבוצע על GPT 3.5 וקבע שנתונים סינטטיים יזיקו בהכרח לאיכות של מודל. הבעיה היא, שעד שהמחקר פורסם, שוחררו מודלים חדשים בעולם האמיתי (כמו PHI3 של מיקרוסופט) שהוכיחו את ההפך הגמור.
ולגבי המאמר שהבאת,
לאעברתי על כולו, והציטוט הבא צץ לנגד עיני מיד (מתורגם לשם הנוחות):FrontierMath, אמת מידה חדשה לחלוטין במתמטיקה, שימשה לבדיקת ה-LLMs הטובים ביותר. היוצרים של מערך הנתונים הזה מזכירים:
כל הבעיות הן חדשות ולא פורסמו, מה שמבטל חששות לזיהום נתונים שפוגעים במדדים קיימים.
ואם מסתכלים על התוצאות - הפתעה, הפתעה - o1-preview לא הגיעה למקום הראשון (או אפילו השני). ואני אפילו לא מזכיר שזה פתר פחות מ-1% מהבעיות המפורטות במערך הנתונים הזה.
אתה יכול גם לראות ש-o1-preview לא הציג ביצועים טובים בהרבה בהשוואה ל-GPT-4o, דגם הבסיס של o1.
זה עשוי לרמוז למסקנה ש-CoT כוונן עדין לביצועים טובים יותר במדדים, אבל בפועל הוא לא עשה שום התקדמות משמעותית.
והנה, הפתעה הפתעה(!!!) שלושה חודשים בלבד אחרי פרסום המאמר המלומד, יוצא מודל חדש שמקבל 25.2% במדד ה"בלתי פתיר" הזה
אגב, הוא לא היחיד המופתע. הנה ציטוט של טרנס טאו, אחד המתמטיקאים המפורסמים והגאונים ביותר בעולם על מדד FrontierMath המדובר:

-
@sivan22 אתה יודע מה מצחיק בכל מפקפקי ה-AI למיניהם? שתוך כמה חודשים הם נאלצים לבלוע את הלשון או לאכול את הכובע, פשוט בגלל שמודל חדש שיוצא שובר את התאוריות הקודמות שלהם.
זה התחיל במחקר מעמיק שבוצע על GPT 3.5 וקבע שנתונים סינטטיים יזיקו בהכרח לאיכות של מודל. הבעיה היא, שעד שהמחקר פורסם, שוחררו מודלים חדשים בעולם האמיתי (כמו PHI3 של מיקרוסופט) שהוכיחו את ההפך הגמור.
ולגבי המאמר שהבאת,
לאעברתי על כולו, והציטוט הבא צץ לנגד עיני מיד (מתורגם לשם הנוחות):FrontierMath, אמת מידה חדשה לחלוטין במתמטיקה, שימשה לבדיקת ה-LLMs הטובים ביותר. היוצרים של מערך הנתונים הזה מזכירים:
כל הבעיות הן חדשות ולא פורסמו, מה שמבטל חששות לזיהום נתונים שפוגעים במדדים קיימים.
ואם מסתכלים על התוצאות - הפתעה, הפתעה - o1-preview לא הגיעה למקום הראשון (או אפילו השני). ואני אפילו לא מזכיר שזה פתר פחות מ-1% מהבעיות המפורטות במערך הנתונים הזה.
אתה יכול גם לראות ש-o1-preview לא הציג ביצועים טובים בהרבה בהשוואה ל-GPT-4o, דגם הבסיס של o1.
זה עשוי לרמוז למסקנה ש-CoT כוונן עדין לביצועים טובים יותר במדדים, אבל בפועל הוא לא עשה שום התקדמות משמעותית.
והנה, הפתעה הפתעה(!!!) שלושה חודשים בלבד אחרי פרסום המאמר המלומד, יוצא מודל חדש שמקבל 25.2% במדד ה"בלתי פתיר" הזה
אגב, הוא לא היחיד המופתע. הנה ציטוט של טרנס טאו, אחד המתמטיקאים המפורסמים והגאונים ביותר בעולם על מדד FrontierMath המדובר:
@NH-LOCAL כתב בשיתוף | מרוץ ה-AI מתקדם במהירות האור - OpenAI הציגה את מודל o3:
אתה יכול גם לראות ש-o1-preview לא הציג ביצועים טובים בהרבה בהשוואה ל-GPT-4o, דגם הבסיס של o1.
זה משפט לא הגיוני בעליל!!!
גאה להיות חלק:
otzaria.org -
@NH-LOCAL כתב בשיתוף | מרוץ ה-AI מתקדם במהירות האור - OpenAI הציגה את מודל o3:
אתה יכול גם לראות ש-o1-preview לא הציג ביצועים טובים בהרבה בהשוואה ל-GPT-4o, דגם הבסיס של o1.
זה משפט לא הגיוני בעליל!!!
@י-פל אני כבר עייפתי. כל הטיעונים שם מוכרים טחונים ולעוסים. כמו בקורונה, גם כאן יש כמה מכחישי AI כמו כותב המאמר הנ"ל וגארי מרקוס למי שמכיר
הטיעונים לעוסים ולא באמת משנים משהו. הוא טוען ש:
"אתה יכול לגרום לכל מודל לחשוב. אז בוודאי שזה לא מודל חדש, זה סה''כ מנגנון מעל המודל. והרעיון ה"מהפכני" הוא לאמן אותו על הבנצ'מארקים עצמם, כדי להטות את התוצאות."
הבעיה היא שאם זה היה כל כך קל, כל החברות הגדולות היו עושות את זה מזמן כדי לנצח במירוץ, וגם OpenAI היו משחררים את זה כבר מזמן במקום לעבוד על המוצר שנה ויותר. (השמועות על השיטה הזו נפוצו כבר בדצמבר 2023 תחת השם Q*)

שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}