המלצה | חיפוש הלכתי חכם (AI)
-
@יוסף3 כתב בהמלצה | חיפוש הלכתי חכם (AI):
בתור מי שמתענין בתחום, אבל לא ממש בקי בו,
אני תוהה האם אין דרך טובה יותר, בצורה הבאה:
לקחת מודל מתקדם, למשל GPT4o, ולהפעיל עליו מה שנקרא Fine-tuning,
על ידי חשיפתו לדרך הנכונה שצריך לענות, למשל לתת לו אלפי שאלות ותשובות של מבחני הרבנות הראשית בהלכה,
כך שיבין איך הוא אמור לענות.וכמובן להוסיף לו גם הוראות מתאמות אישית על מה לענות ועל מה לא ואיך לענות, ושתמיד יביא את המקור לתשובה שלו, ואולי אפשר לחבר זאת למשהו כמו ספריא/אוצריה שתמיד יביא לך את הציטוט המדוייק, וכדו'
אשמח לשמוע את דעתך על כיוון המחשבה שלי.
תודה
ברור שבעקרון זה יהיה יותר מוצלח, אבל מדובר בסדר גודל אחר לגמרי של פרוייקט, לא בתקציב של מפתח בודד, וכנראה גם לא של חברה קטנה או בינונית. כמו כן כמות הנתונים הנדרשת היא הרבה יותר גדולה ממה שתיארת, ואלפי שאלות זה לא ממש מספיק, צריך עשרות אלפי שאלות.
לכן פרוייקט שמשתמש במודל כמות שהוא ורק מביא לו את הנתונים ומצווה עליו להיצמד אליהם, הרבה יותר רלווונטי. (זה נקרא בשפה מקצועית RAG) -
היי חברים,
אני רוצה לשתף אתכם בנסיונות ליצור חיפוש תורני חכם מבוסס בינה מלאכותית.
אז לפני כמה חודשים הדגמתי חיפוש חכם בשולחן ערוך, וזה היה מבוסס על מודל שידע לסווג משפטים לסעיפים הנכונים בשולחן ערוך. אך זה היה כרוך באימון של המודל, מה שגרם לזה להיות מורכב.
הפעם השתמשתי בשיטה אחרת, היתרון שלה הוא שהיא ניתנת להרחבה בקלות גם למאגרים גדולים (אוצריא?) וגם לא הייתי צריך לאמן שום מודל, השתמשתי במודל קיים (עם זאת, יתכן שאימון כן יכול לעזור לו, במיוחד במושגים תורניים שהוא לא מכיר).
העקרון הוא כזה: יש מודל שיודע לתת לכל משפט ייצוג מספרי מתאים, שזה בעצם סדרה של מספרים, שאפשר להתייחס אליה כמציינת את המיקום של המשפט במרחב המשפטים. לדוגמה שני מספרים יכולים לשמש ציון של מיקום על ציר הX והY במרחב דו מימדי. אבל כאן משתמשים בהרבה מספרים, וזה בעצם מיקום במרחב רב מימדי. לוקחים את כל המשפטים שרוצים לחפש בהם, ונותנים להם את המספרים הללו. אחר כך לוקחים את השאילתה שהמשתמש רוצה, וגם לה נותנים ייצוג באותה שיטה, ומחפשים את הנקודה הקרובה ביותר במרחב.
תמונה להמחשה:
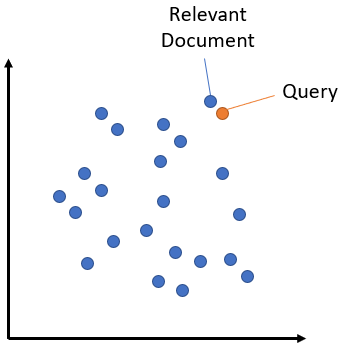
איך בעצם מייצרים את המספרים הללו? למעשה מדובר במודל שפה מתוחכם עם הרבה למידת מכונה, שהתאמן על משפטים דומים ושונים. אבל לסבר את האוזן נוכל להראות איך ניצור כאלו מספרים פשוט ממספר המילים שחוזרות על עצמן בכל קטע.
נניח שיש לנו שני קטעי מתכונים ושני קטעים מספר על טיולים, ואנ ורוצים לתת לכל קטע ייצוג, אז נספור את מספר הפעמים שמופיעים המילים "חלב" "ביצים" "ירושלים" "כביש", בכל אחד מהקטעים הללו, ונגלה שבעצם הייצוג של שני קטעי המתכונים די דומה (נניח שאחד מהם הוא 2,3,0,0 והשני הוא 1,2,0,0 - כלומר המילה חלב מופיעה פעם אחת, ביצים פעמיים וכביש וירושלים בכלל לא.) אבל קטעי הטיולים דווקא כן דומים למדי (0,0,3,5 ו1,0,2,6).
אז זה השלב הראשון.
לפעמים זה לא מספיק, אז בשביל זה יש את השלב השני. שולחים את התוצאות (נניח 10 התוצאות הראשונות) למודל שפה גדול (נניח GPT 3.5) ונותנים לו למיין את התוצאות לפי הרלוונטיות שלהם. זה אמור לשפר מאד את התוצאות, כי מודל השפה אמור להבין איזו תשובה הכי רלוונטית לשאלה.
השתמשתי להדגמה בספר "ילקוט יוסף - קיצושו"ע אורח חיים" של מרן הראשל"צ משום שהוא כתוב בשפה קלה, שגם מודלי שפה יכולים להבין. אבל די בקלות אפשר להרחיב אותו לכל ספר שהוא.
יאללה מספיק דיבורים, תביא את הלינק וגמרנו:
https://huggingface.co/spaces/sivan22/Halacha-semantic-searchשימו לב שכדי להשתמש במודל שפה (שלב ב) צריך לספק לו מפתח API של openAI, ניתן להשיג אותו (בתשלום) באתר של openAI. אבל החיפוש הרגיל עובד לכולם.
-
היי חברים,
אני רוצה לשתף אתכם בנסיונות ליצור חיפוש תורני חכם מבוסס בינה מלאכותית.
אז לפני כמה חודשים הדגמתי חיפוש חכם בשולחן ערוך, וזה היה מבוסס על מודל שידע לסווג משפטים לסעיפים הנכונים בשולחן ערוך. אך זה היה כרוך באימון של המודל, מה שגרם לזה להיות מורכב.
הפעם השתמשתי בשיטה אחרת, היתרון שלה הוא שהיא ניתנת להרחבה בקלות גם למאגרים גדולים (אוצריא?) וגם לא הייתי צריך לאמן שום מודל, השתמשתי במודל קיים (עם זאת, יתכן שאימון כן יכול לעזור לו, במיוחד במושגים תורניים שהוא לא מכיר).
העקרון הוא כזה: יש מודל שיודע לתת לכל משפט ייצוג מספרי מתאים, שזה בעצם סדרה של מספרים, שאפשר להתייחס אליה כמציינת את המיקום של המשפט במרחב המשפטים. לדוגמה שני מספרים יכולים לשמש ציון של מיקום על ציר הX והY במרחב דו מימדי. אבל כאן משתמשים בהרבה מספרים, וזה בעצם מיקום במרחב רב מימדי. לוקחים את כל המשפטים שרוצים לחפש בהם, ונותנים להם את המספרים הללו. אחר כך לוקחים את השאילתה שהמשתמש רוצה, וגם לה נותנים ייצוג באותה שיטה, ומחפשים את הנקודה הקרובה ביותר במרחב.
תמונה להמחשה:
איך בעצם מייצרים את המספרים הללו? למעשה מדובר במודל שפה מתוחכם עם הרבה למידת מכונה, שהתאמן על משפטים דומים ושונים. אבל לסבר את האוזן נוכל להראות איך ניצור כאלו מספרים פשוט ממספר המילים שחוזרות על עצמן בכל קטע.
נניח שיש לנו שני קטעי מתכונים ושני קטעים מספר על טיולים, ואנ ורוצים לתת לכל קטע ייצוג, אז נספור את מספר הפעמים שמופיעים המילים "חלב" "ביצים" "ירושלים" "כביש", בכל אחד מהקטעים הללו, ונגלה שבעצם הייצוג של שני קטעי המתכונים די דומה (נניח שאחד מהם הוא 2,3,0,0 והשני הוא 1,2,0,0 - כלומר המילה חלב מופיעה פעם אחת, ביצים פעמיים וכביש וירושלים בכלל לא.) אבל קטעי הטיולים דווקא כן דומים למדי (0,0,3,5 ו1,0,2,6).
אז זה השלב הראשון.
לפעמים זה לא מספיק, אז בשביל זה יש את השלב השני. שולחים את התוצאות (נניח 10 התוצאות הראשונות) למודל שפה גדול (נניח GPT 3.5) ונותנים לו למיין את התוצאות לפי הרלוונטיות שלהם. זה אמור לשפר מאד את התוצאות, כי מודל השפה אמור להבין איזו תשובה הכי רלוונטית לשאלה.
השתמשתי להדגמה בספר "ילקוט יוסף - קיצושו"ע אורח חיים" של מרן הראשל"צ משום שהוא כתוב בשפה קלה, שגם מודלי שפה יכולים להבין. אבל די בקלות אפשר להרחיב אותו לכל ספר שהוא.
יאללה מספיק דיבורים, תביא את הלינק וגמרנו:
https://huggingface.co/spaces/sivan22/Halacha-semantic-searchשימו לב שכדי להשתמש במודל שפה (שלב ב) צריך לספק לו מפתח API של openAI, ניתן להשיג אותו (בתשלום) באתר של openAI. אבל החיפוש הרגיל עובד לכולם.
@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
שימו לב שכדי להשתמש במודל שפה (שלב ב) צריך לספק לו מפתח API של openAI, ניתן להשיג אותו (בתשלום) באתר של openAI. אבל החיפוש הרגיל עובד לכולם.
יש להבנתי מודלים שנותנים API חינם, זה אפשרי להשתמש איתם או שזה מיועד רק עבור GPT?
-
@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
שימו לב שכדי להשתמש במודל שפה (שלב ב) צריך לספק לו מפתח API של openAI, ניתן להשיג אותו (בתשלום) באתר של openAI. אבל החיפוש הרגיל עובד לכולם.
יש להבנתי מודלים שנותנים API חינם, זה אפשרי להשתמש איתם או שזה מיועד רק עבור GPT?
-
@sivan22 זה דבר שכל אחד יכול לעשות? [מבחינת ידע ואמצעים?] א"כ יש אפשרות שתתן הדרכה איך אני יכול לעשות כזה דבר על ספר משלי?
אשמח!
תודה רבה@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 זה דבר שכל אחד יכול לעשות? [מבחינת ידע ואמצעים?] א"כ יש אפשרות שתתן הדרכה איך אני יכול לעשות כזה דבר על ספר משלי?
אשמח!
תודה רבהיחסית זה פשוט, והרבה יותר קל מלאמן מודל.
צריך קצת ידע בפייתון, ובפרט בספריית pandas כדי להפוך את הספר לטבלה שכל רשומה היא שורה (או קטע) בספר. אלא אם כן אתה רוצה לעשות את זה ידנית....
ואז הקוד הוא די פשוט, שוב פייתון, משהו כזה (בהנחה שיש לך קובץ אקסל שכל שורה היא קטע מהספר):
import pandas ad pd df = pd.read_excel('הקובץ שלך'.xlsx) from langchain_huggingface.embeddings import HuggingFaceEmbeddings model_name = "intfloat/multilingual-e5-large" model_kwargs = {'device': 'cpu'} # or 'cuda' encode_kwargs = {'normalize_embeddings': False} embeddings_model = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs ) df['embeddings'] =embeddings_model.embed_documents(df['text'].apply (lambda x: 'passage: ' + x ).to_list()) query = "בשבת ערב ראש חודש האם אומרים רצה או יעלה ויבוא" queryEmbedd = embeddings_model.embed_query('query: '+query) from sentence_transformers import util df['similarity'] = df['embeddings'].apply(lambda x: util.cos_sim(x, queryEmbedd)) results = df.sort_values(by='similarity', ascending=False) resultsזהו. ב21 שורות סיימנו (כולל שורות ריקות).
קצת הסברים:
שורה 2 אנו לוקחים את הנתונים מהקובץ.
שורות 4-10 אנו מורידים מודל.
שורה 13 יוצרים את הייצוג המספרי עבור הנתונים.
שורות 15-16 יוצרים את הייצוג המספרי עבור השאילתה.
שורות 19-20 ממייינים את הנתונים לפי רמת הדימיון לשאילתה.
זהו. מציגים את התוצאה בשורה האחרונה. -
@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 זה דבר שכל אחד יכול לעשות? [מבחינת ידע ואמצעים?] א"כ יש אפשרות שתתן הדרכה איך אני יכול לעשות כזה דבר על ספר משלי?
אשמח!
תודה רבהיחסית זה פשוט, והרבה יותר קל מלאמן מודל.
צריך קצת ידע בפייתון, ובפרט בספריית pandas כדי להפוך את הספר לטבלה שכל רשומה היא שורה (או קטע) בספר. אלא אם כן אתה רוצה לעשות את זה ידנית....
ואז הקוד הוא די פשוט, שוב פייתון, משהו כזה (בהנחה שיש לך קובץ אקסל שכל שורה היא קטע מהספר):
import pandas ad pd df = pd.read_excel('הקובץ שלך'.xlsx) from langchain_huggingface.embeddings import HuggingFaceEmbeddings model_name = "intfloat/multilingual-e5-large" model_kwargs = {'device': 'cpu'} # or 'cuda' encode_kwargs = {'normalize_embeddings': False} embeddings_model = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs ) df['embeddings'] =embeddings_model.embed_documents(df['text'].apply (lambda x: 'passage: ' + x ).to_list()) query = "בשבת ערב ראש חודש האם אומרים רצה או יעלה ויבוא" queryEmbedd = embeddings_model.embed_query('query: '+query) from sentence_transformers import util df['similarity'] = df['embeddings'].apply(lambda x: util.cos_sim(x, queryEmbedd)) results = df.sort_values(by='similarity', ascending=False) resultsזהו. ב21 שורות סיימנו (כולל שורות ריקות).
קצת הסברים:
שורה 2 אנו לוקחים את הנתונים מהקובץ.
שורות 4-10 אנו מורידים מודל.
שורה 13 יוצרים את הייצוג המספרי עבור הנתונים.
שורות 15-16 יוצרים את הייצוג המספרי עבור השאילתה.
שורות 19-20 ממייינים את הנתונים לפי רמת הדימיון לשאילתה.
זהו. מציגים את התוצאה בשורה האחרונה.@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
צריך קצת ידע בפייתון, ובפרט בספריית pandas כדי להפוך את הספר לטבלה שכל רשומה היא שורה (או קטע) בספר. אלא אם כן אתה רוצה לעשות את זה ידנית....
מה הכוונה שורה? שורה ממש? שורה שהיא חלק ממשפט אחד? כמות מילים?
זהו. מציגים את התוצאה בשורה האחרונה.
ואיך עושים שזה יהיה יפה כמו אצלך באתר מסודר ומעוצב?
-
@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
צריך קצת ידע בפייתון, ובפרט בספריית pandas כדי להפוך את הספר לטבלה שכל רשומה היא שורה (או קטע) בספר. אלא אם כן אתה רוצה לעשות את זה ידנית....
מה הכוונה שורה? שורה ממש? שורה שהיא חלק ממשפט אחד? כמות מילים?
זהו. מציגים את התוצאה בשורה האחרונה.
ואיך עושים שזה יהיה יפה כמו אצלך באתר מסודר ומעוצב?
@aiib אתה יכול להחליט לבד מה נקרא שורה, בספר עם סעיפים מתבקש שזה סעיף, אם זה ספר עם קטעים ארוכים אתה יכול להחליט שכל 20 מילים לדוגמה הם שורה.
בשביל שזה ייראה יפה צריך עוד קצת קוד פייתון, תוכל לראות את הקוד כאן: https://huggingface.co/spaces/sivan22/Halacha-semantic-search/blob/main/app.py
-
@aiib אתה יכול להחליט לבד מה נקרא שורה, בספר עם סעיפים מתבקש שזה סעיף, אם זה ספר עם קטעים ארוכים אתה יכול להחליט שכל 20 מילים לדוגמה הם שורה.
בשביל שזה ייראה יפה צריך עוד קצת קוד פייתון, תוכל לראות את הקוד כאן: https://huggingface.co/spaces/sivan22/Halacha-semantic-search/blob/main/app.py
-
@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 האמת היא שאני בבסיס צריך הדרכה...
יש מצב?מה אני בוחר כאן?
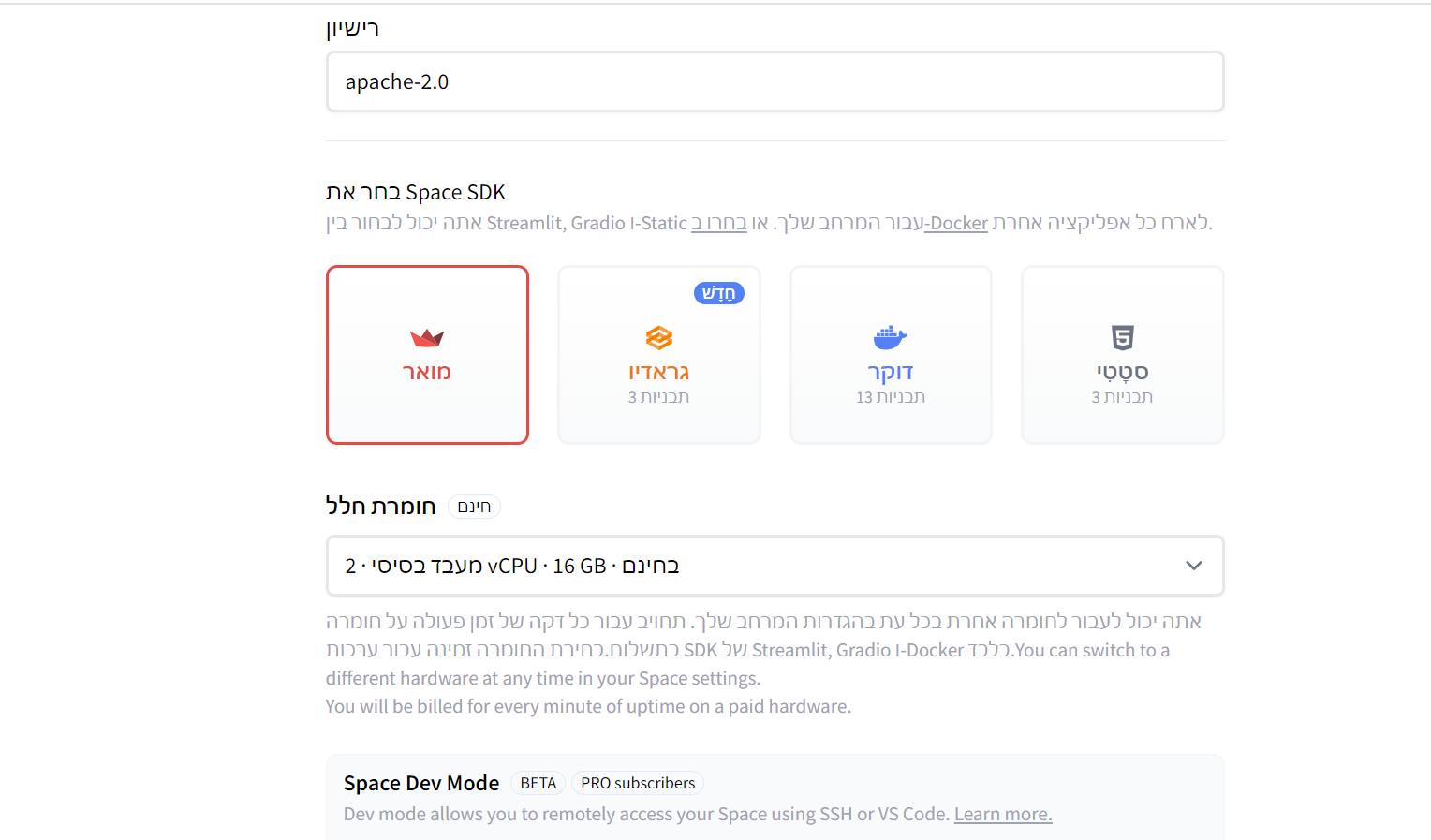
אם כבר אתה מנסה ליצור ספייס, פשוט תשכפל את שלי:
אני אולי אעשה space שאפשר להעלות אליו קובץ, ליצור לו ייצוגים מספריים ולחפש בהם.
-
@אהרן כתב בהמלצה | חיפוש הלכתי חכם (AI):
יש אפשרות להוריד את זה למחשב?
עיין כאן https://mitmachim.top/post/771276
-
@אהרן כתב בהמלצה | חיפוש הלכתי חכם (AI):
יש אפשרות להוריד את זה למחשב?
עיין כאן https://mitmachim.top/post/771276
-
@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
אני אולי אעשה space שאפשר להעלות אליו קובץ, ליצור לו ייצוגים מספריים ולחפש בהם.
הכי טוב!! אם זה בקלות אדרבה ואדרבה, מאמין שזה יעזור לי ולרבים!
תעדכן אם זה בתוכנית בזמן הקרוב...@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
אני אולי אעשה space שאפשר להעלות אליו קובץ, ליצור לו ייצוגים מספריים ולחפש בהם.
הכי טוב!! אם זה בקלות אדרבה ואדרבה, מאמין שזה יעזור לי ולרבים!
תעדכן אם זה בתוכנית בזמן הקרוב...זה מוכן: https://huggingface.co/spaces/sivan22/Semantic-Search-upload-your-file
תתאזר בסבלנות ליצירת הייצוג המספרי, זה יכול לקחת הרבה זמן (זה רץ בענן חינמי בלי GPU)
-
@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
אני אולי אעשה space שאפשר להעלות אליו קובץ, ליצור לו ייצוגים מספריים ולחפש בהם.
הכי טוב!! אם זה בקלות אדרבה ואדרבה, מאמין שזה יעזור לי ולרבים!
תעדכן אם זה בתוכנית בזמן הקרוב...זה מוכן: https://huggingface.co/spaces/sivan22/Semantic-Search-upload-your-file
תתאזר בסבלנות ליצירת הייצוג המספרי, זה יכול לקחת הרבה זמן (זה רץ בענן חינמי בלי GPU)
-
@sivan22 יש מצב ליצור כזה פרטי שלא כל אחד יוכל לגשת?
עריכה: הכי טוב שיהיה אפשרות למשהו קבוע כמו שאתה עשית לילקוט יוסף.
אבל אני כבר מגזים עם הדרישות...@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 יש מצב ליצור כזה פרטי שלא כל אחד יוכל לגשת?
אפשר באותו אתר, אבל בתשלום (חינם זה רק ציבורי).
עריכה: הכי טוב שיהיה אפשרות למשהו קבוע כמו שאתה עשית לילקוט יוסף.
וכמובן שאתה יכול ליצור פעם אחת את הייצוגים ולשמור אותם בענן, וכל פעם להוריד אותם מוכנים.
היום זה ממש שווה ללמוד פייתון, ובפרט את הספריות: pandas, transformers, וdatasets.
-
@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 יש מצב ליצור כזה פרטי שלא כל אחד יוכל לגשת?
אפשר באותו אתר, אבל בתשלום (חינם זה רק ציבורי).
עריכה: הכי טוב שיהיה אפשרות למשהו קבוע כמו שאתה עשית לילקוט יוסף.
וכמובן שאתה יכול ליצור פעם אחת את הייצוגים ולשמור אותם בענן, וכל פעם להוריד אותם מוכנים.
היום זה ממש שווה ללמוד פייתון, ובפרט את הספריות: pandas, transformers, וdatasets.
@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 יש מצב ליצור כזה פרטי שלא כל אחד יוכל לגשת?
אפשר באותו אתר, אבל בתשלום (חינם זה רק ציבורי).
אתה בטוח? כי גם כשבחרתי מצב חינם הוא נתן לי אופציה של פרטי. ככה נראה לי...
עריכה: הכי טוב שיהיה אפשרות למשהו קבוע כמו שאתה עשית לילקוט יוסף.
וכמובן שאתה יכול ליצור פעם אחת את הייצוגים ולשמור אותם בענן, וכל פעם להוריד אותם מוכנים.
אני מתכוון ליצור ספייס שמיועד לחיפוש בספר פלוני [כמו שאתה עשית עם הילקוט יוסף] ספציפי.
-
@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 יש מצב ליצור כזה פרטי שלא כל אחד יוכל לגשת?
אפשר באותו אתר, אבל בתשלום (חינם זה רק ציבורי).
אתה בטוח? כי גם כשבחרתי מצב חינם הוא נתן לי אופציה של פרטי. ככה נראה לי...
עריכה: הכי טוב שיהיה אפשרות למשהו קבוע כמו שאתה עשית לילקוט יוסף.
וכמובן שאתה יכול ליצור פעם אחת את הייצוגים ולשמור אותם בענן, וכל פעם להוריד אותם מוכנים.
אני מתכוון ליצור ספייס שמיועד לחיפוש בספר פלוני [כמו שאתה עשית עם הילקוט יוסף] ספציפי.
-
@aiib אין שום בעיה, רק תצטרך קודם ליצור את הייצוגים ולשמור אותם בענן. מומלץ דרך ספריית datasets ושמירה בhuggingface_hub. מושגים שאם מעניין אותך בינה מלאכותית "למעיישה", אתה חייב לדעת.
-
@aiib כתב בהמלצה | חיפוש הלכתי חכם (AI):
@sivan22 האמת היא שאני בבסיס צריך הדרכה...
יש מצב?מה אני בוחר כאן?
אם כבר אתה מנסה ליצור ספייס, פשוט תשכפל את שלי:
אני אולי אעשה space שאפשר להעלות אליו קובץ, ליצור לו ייצוגים מספריים ולחפש בהם.
@sivan22 כתב בהמלצה | חיפוש הלכתי חכם (AI):
אם כבר אתה מנסה ליצור ספייס, פשוט תשכפל את שלי:
אני מעלה קובץ טקסט [וורד הוא מסרב לקבל, אז המרתי לקובץ טקסט] ואני מקבל את השגיאה הבאה:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe0 in position 0: invalid continuation byte Traceback: File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 575, in _run_script self._session_state.on_script_will_rerun( File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/state/safe_session_state.py", line 65, in on_script_will_rerun self._state.on_script_will_rerun(latest_widget_states) File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/state/session_state.py", line 517, in on_script_will_rerun self._call_callbacks() File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/state/session_state.py", line 530, in _call_callbacks self._new_widget_state.call_callback(wid) File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/state/session_state.py", line 274, in call_callback callback(*args, **kwargs) File "/home/user/app/app.py", line 105, in run df = get_df(uploaded_file) File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/caching/cache_utils.py", line 165, in wrapper return cached_func(*args, **kwargs) File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/caching/cache_utils.py", line 194, in __call__ return self._get_or_create_cached_value(args, kwargs) File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/caching/cache_utils.py", line 221, in _get_or_create_cached_value return self._handle_cache_miss(cache, value_key, func_args, func_kwargs) File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/caching/cache_utils.py", line 277, in _handle_cache_miss computed_value = self._info.func(*func_args, **func_kwargs) File "/home/user/app/app.py", line 21, in get_df stringio = StringIO(uploaded_file.getvalue().decode("utf-8"))
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}