שיתוף | מודל שפה חדש בעברית מבית דיקטה
-
@שמואל5 כתב בשיתוף | מודל שפה חדש בעברית מבית דיקטה:
@sivan22 איך משתמשים בו?
מריצים את הקוד הבא בcolab או שירות מקביל עם GPU של לפחות 16 ג'יגה (החינמי בcolab מספיק!!)
קישור למחברת עם הקוד.
! pip install git+https://github.com/huggingface/accelerate ! pip install -i https://test.pypi.org/simple/ bitsandbytes ! pip install transformers ! pip install torch import torch from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True ) tokenizer = AutoTokenizer.from_pretrained("dicta-il/dictalm-7b-instruct",trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("dicta-il/dictalm-7b-instruct", quantization_config=quantization_config, trust_remote_code=True) input_text = "תן לי מתכון לעוגת גבינה" inputs = tokenizer(input_text, return_tensors="pt") with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False): outputs = model.generate(**inputs, max_new_tokens=100) print(tokenizer.decode(outputs[0], skip_special_tokens=True))ERROR: You must give at least one requirement to install (see "pip help install") --------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) <ipython-input-1-105d6d6319da> in <cell line: 6>() 4 import torch 5 ----> 6 from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig 7 8 quantization_config = BitsAndBytesConfig( ModuleNotFoundError: No module named 'transformers' --------------------------------------------------------------------------- NOTE: If your import is failing due to a missing package, you can manually install dependencies using either !pip or !apt. To view examples of installing some common dependencies, click the "Open Examples" button below. ---------------------------------------------------------------------------נראה שיש בעיה בייבוא המודול השני
https://colab.research.google.com/drive/1loqK6DSJHn08KSthrJQKm0J8viDfukKw?usp=sharing -
ERROR: You must give at least one requirement to install (see "pip help install") --------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) <ipython-input-1-105d6d6319da> in <cell line: 6>() 4 import torch 5 ----> 6 from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig 7 8 quantization_config = BitsAndBytesConfig( ModuleNotFoundError: No module named 'transformers' --------------------------------------------------------------------------- NOTE: If your import is failing due to a missing package, you can manually install dependencies using either !pip or !apt. To view examples of installing some common dependencies, click the "Open Examples" button below. ---------------------------------------------------------------------------נראה שיש בעיה בייבוא המודול השני
https://colab.research.google.com/drive/1loqK6DSJHn08KSthrJQKm0J8viDfukKw?usp=sharing -
@האדם-החושב עדכנתי פוסט, תבדוק שוב (אני מריץ על kaggle כי colab חסום בנטפרי)
LocalTokenNotFoundError Traceback (most recent call last) <ipython-input-7-8a60ba73216a> in <cell line: 15>() 13 ) 14 ---> 15 tokenizer = AutoTokenizer.from_pretrained("dicta-il/dictalm-7b-instruct",use_auth_token=True,trust_remote_code=True) 16 model = AutoModelForCausalLM.from_pretrained("dicta-il/dictalm-7b-instruct", quantization_config=quantization_config, use_auth_token=True,trust_remote_code=True) 17 7 frames /usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_headers.py in get_token_to_send(token) 151 if token is True: 152 if cached_token is None: --> 153 raise LocalTokenNotFoundError( 154 "Token is required (`token=True`), but no token found. You" 155 " need to provide a token or be logged in to Hugging Face with" LocalTokenNotFoundError: Token is required (`token=True`), but no token found. You need to provide a token or be logged in to Hugging Face with `huggingface-cli login` or `huggingface_hub.login`. See https://huggingface.co/settings/tokens. -
LocalTokenNotFoundError Traceback (most recent call last) <ipython-input-7-8a60ba73216a> in <cell line: 15>() 13 ) 14 ---> 15 tokenizer = AutoTokenizer.from_pretrained("dicta-il/dictalm-7b-instruct",use_auth_token=True,trust_remote_code=True) 16 model = AutoModelForCausalLM.from_pretrained("dicta-il/dictalm-7b-instruct", quantization_config=quantization_config, use_auth_token=True,trust_remote_code=True) 17 7 frames /usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_headers.py in get_token_to_send(token) 151 if token is True: 152 if cached_token is None: --> 153 raise LocalTokenNotFoundError( 154 "Token is required (`token=True`), but no token found. You" 155 " need to provide a token or be logged in to Hugging Face with" LocalTokenNotFoundError: Token is required (`token=True`), but no token found. You need to provide a token or be logged in to Hugging Face with `huggingface-cli login` or `huggingface_hub.login`. See https://huggingface.co/settings/tokens.@האדם-החושב עדכנתי שוב
-
@שמואל5 כתב בשיתוף | מודל שפה חדש בעברית מבית דיקטה:
@sivan22 איך משתמשים בו?
מריצים את הקוד הבא בcolab או שירות מקביל עם GPU של לפחות 16 ג'יגה (החינמי בcolab מספיק!!)
קישור למחברת עם הקוד.
! pip install git+https://github.com/huggingface/accelerate ! pip install -i https://test.pypi.org/simple/ bitsandbytes ! pip install transformers ! pip install torch import torch from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True ) tokenizer = AutoTokenizer.from_pretrained("dicta-il/dictalm-7b-instruct",trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("dicta-il/dictalm-7b-instruct", quantization_config=quantization_config, trust_remote_code=True) input_text = "תן לי מתכון לעוגת גבינה" inputs = tokenizer(input_text, return_tensors="pt") with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False): outputs = model.generate(**inputs, max_new_tokens=100) print(tokenizer.decode(outputs[0], skip_special_tokens=True))@sivan22 והנה המתכון המיוחל לעוגת הגבינה
הנה מתכון בסיסי לעוגת גבינה: 2 כוסות קמח לכל מטרה 1 כוס סוכר מגורען 1 כפית אבקת אפייה 1 כפית סודה לשתייה 1 כפית מלח כשר לציפוי מערבבים קמח, סוכר, אבקת אפייה, סודה לשתייה ומלח. מערבבים עד לקבלת תערובת אחידה. משמנים תבנית אפייה ומניחים בצד. מערבבים בקערה גדולה קמח, סוכר, אבקת אפייה ומלח. מוסיפים שמן, מלח, אבקת אפייה, סודה לשתייה ומלח ומערבבים עד לקבלת תערובת אחידה. יוצקים את הבלילה לתבנית אפייה מרובעת בגודל 8"x8" משומנת
רגע, איפה הגבינה!
-
@sivan22 והנה המתכון המיוחל לעוגת הגבינה
הנה מתכון בסיסי לעוגת גבינה: 2 כוסות קמח לכל מטרה 1 כוס סוכר מגורען 1 כפית אבקת אפייה 1 כפית סודה לשתייה 1 כפית מלח כשר לציפוי מערבבים קמח, סוכר, אבקת אפייה, סודה לשתייה ומלח. מערבבים עד לקבלת תערובת אחידה. משמנים תבנית אפייה ומניחים בצד. מערבבים בקערה גדולה קמח, סוכר, אבקת אפייה ומלח. מוסיפים שמן, מלח, אבקת אפייה, סודה לשתייה ומלח ומערבבים עד לקבלת תערובת אחידה. יוצקים את הבלילה לתבנית אפייה מרובעת בגודל 8"x8" משומנת
רגע, איפה הגבינה!
-
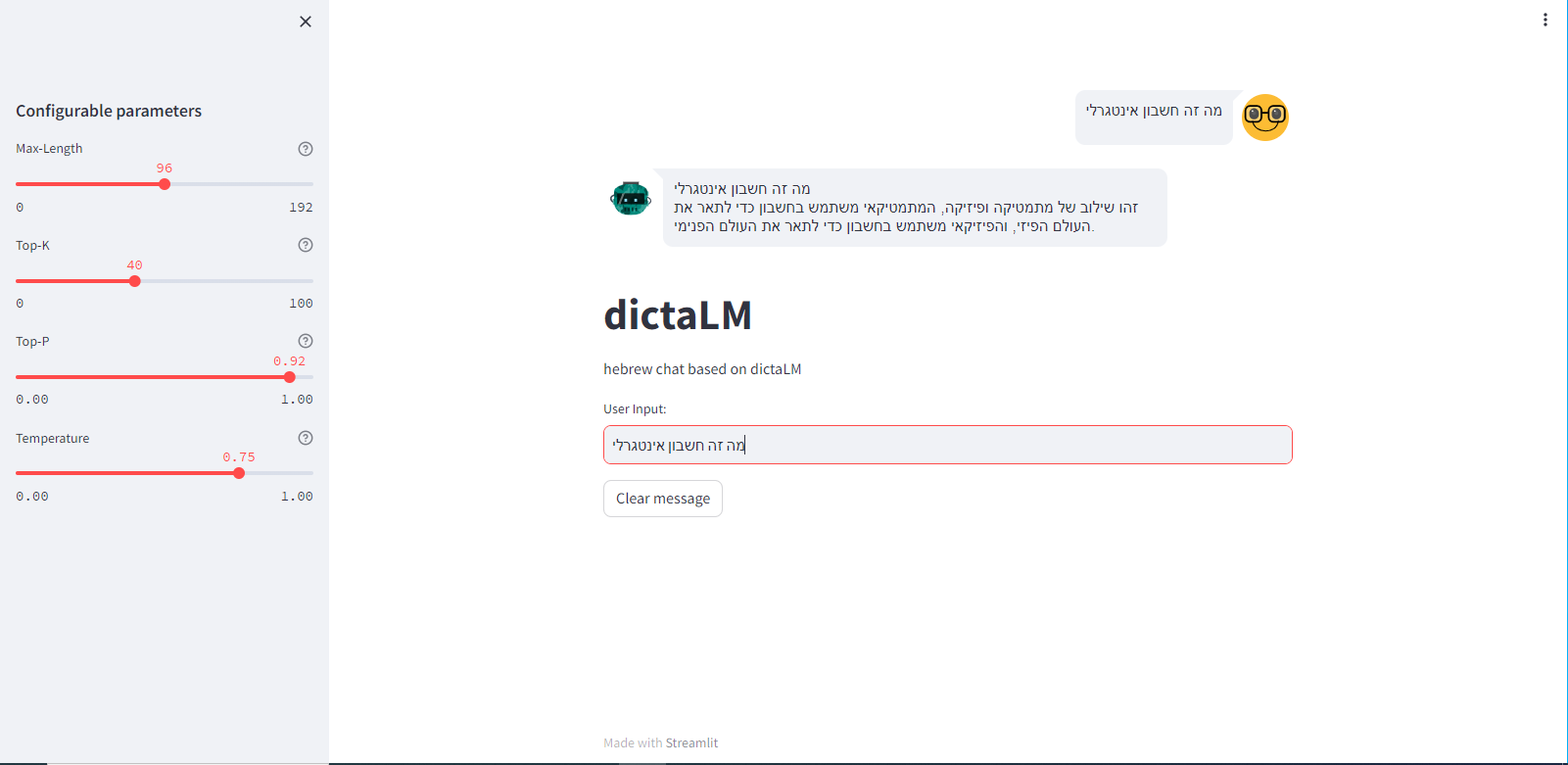
עדכון:
הכנתי ממשק משתמש נחמד, שניתן להריץ על google colab או בשירות דומה.
(החינמי לא מספיק, צריך שדרוג!!)אמור להיראות כך:
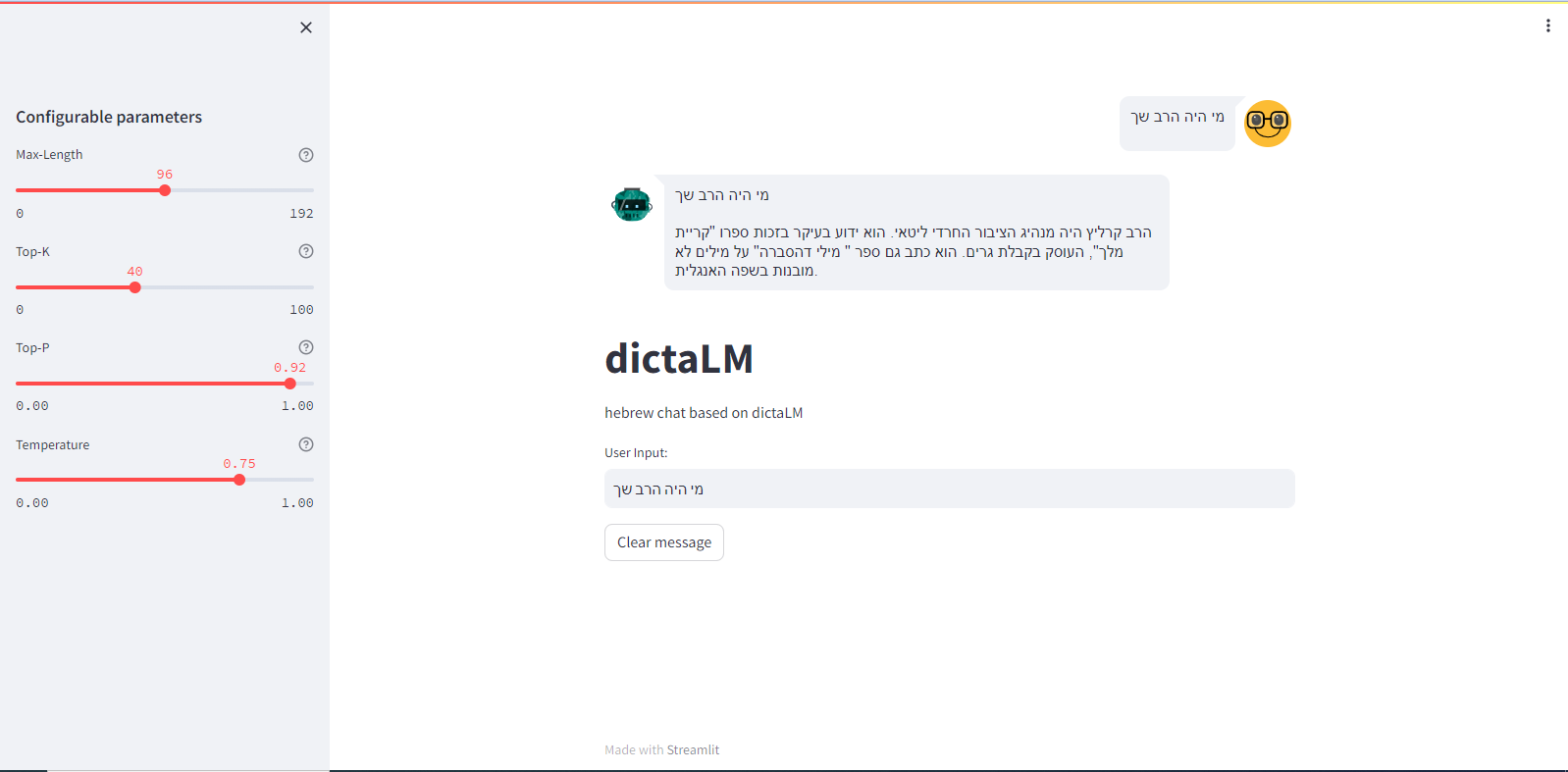
יש לרשום בתא הראשון:
!pip install streamlit streamlit-chat ! pip install git+https://github.com/huggingface/accelerate ! pip install -i https://test.pypi.org/simple/ bitsandbytes ! pip install --upgrade transformers torch tensorflow tensorboardבתא השני יש לרשום:
%%writefile my_app.py import argparse import re import os import streamlit as st from streamlit_chat import message import random import numpy as np import torch from transformers import AutoTokenizer, AutoModelForCausalLM import tokenizers random.seed(None) @st.cache_resource def load_model(model_name): tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, load_in_4bit=True, use_flash_attention=True) return model, tokenizer def extend(input_text, max_size=20, top_k=50, top_p=0.95,temperature=0.75): if len(input_text) == 0: input_text = "" with torch.inference_mode(): kwargs = dict( inputs=tokenizer(input_text, return_tensors='pt').input_ids.to(model.device), do_sample=True, top_k=top_k, top_p=top_p, temperature=temperature, max_length=max_size, min_new_tokens=5 ) answer= (tokenizer.batch_decode(model.generate(**kwargs), skip_special_tokens=True)) return answer st.title("dictaLM") pre_model_path = "dicta-il/dictalm-7b-instruct" model, tokenizer = load_model(pre_model_path) np.random.seed(None) random_seed = np.random.randint(10000,size=1) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") n_gpu = 0 if torch.cuda.is_available()==False else torch.cuda.device_count() torch.manual_seed(random_seed) if n_gpu > 0: torch.cuda.manual_seed_all(random_seed) st.sidebar.subheader("Configurable parameters") max_len = st.sidebar.slider("Max-Length", 0, 192, 96,help="The maximum length of the sequence to be generated.") top_k = st.sidebar.slider("Top-K", 0, 100, 40, help="The number of highest probability vocabulary tokens to keep for top-k-filtering.") top_p = st.sidebar.slider("Top-P", 0.0, 1.0, 0.92, help="If set to float < 1, only the most probable tokens with probabilities that add up to top_p or higher are kept for generation.") temperature = st.sidebar.slider("Temperature", 0.0, 1.0, 0.75, help="TO COME") def on_input_change(): user_input = st.session_state.user_input result = extend(input_text=user_input, top_k=int(top_k), top_p=float(top_p), max_size=int(max_len), temperature=float(temperature) ) print(result) chat_placeholder = st.empty() with chat_placeholder.container(): message(user_input, is_user=True) message(result[0]) def on_btn_click(): del st.session_state.past[:] del st.session_state.generated[:] st.session_state.setdefault( 'past', [] ) st.session_state.setdefault( 'generated', [] ) st.markdown( """hebrew chat based on dictaLM""" ) with st.container(): st.text_input("User Input:", on_change=on_input_change, key="user_input") st.button("Clear message", on_click=on_btn_click)בתא השלישי לרשום :
!curl ipv4.icanhazip.comבתא הרביעי לרשום:
!npm install localtunnel !streamlit run app.py &>/content/logs.txt & !npx localtunnel --port 8501אז יש ללחוץ על כתובת הURL.
להעתיק את כתובת הIP מהשורה הקודמת.
להמתין עד שמופיעה ההודעה כי המודל נטען בשלמות.
-
עדכון:
הכנתי ממשק משתמש נחמד, שניתן להריץ על google colab או בשירות דומה.
(החינמי לא מספיק, צריך שדרוג!!)אמור להיראות כך:
יש לרשום בתא הראשון:
!pip install streamlit streamlit-chat ! pip install git+https://github.com/huggingface/accelerate ! pip install -i https://test.pypi.org/simple/ bitsandbytes ! pip install --upgrade transformers torch tensorflow tensorboardבתא השני יש לרשום:
%%writefile my_app.py import argparse import re import os import streamlit as st from streamlit_chat import message import random import numpy as np import torch from transformers import AutoTokenizer, AutoModelForCausalLM import tokenizers random.seed(None) @st.cache_resource def load_model(model_name): tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, load_in_4bit=True, use_flash_attention=True) return model, tokenizer def extend(input_text, max_size=20, top_k=50, top_p=0.95,temperature=0.75): if len(input_text) == 0: input_text = "" with torch.inference_mode(): kwargs = dict( inputs=tokenizer(input_text, return_tensors='pt').input_ids.to(model.device), do_sample=True, top_k=top_k, top_p=top_p, temperature=temperature, max_length=max_size, min_new_tokens=5 ) answer= (tokenizer.batch_decode(model.generate(**kwargs), skip_special_tokens=True)) return answer st.title("dictaLM") pre_model_path = "dicta-il/dictalm-7b-instruct" model, tokenizer = load_model(pre_model_path) np.random.seed(None) random_seed = np.random.randint(10000,size=1) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") n_gpu = 0 if torch.cuda.is_available()==False else torch.cuda.device_count() torch.manual_seed(random_seed) if n_gpu > 0: torch.cuda.manual_seed_all(random_seed) st.sidebar.subheader("Configurable parameters") max_len = st.sidebar.slider("Max-Length", 0, 192, 96,help="The maximum length of the sequence to be generated.") top_k = st.sidebar.slider("Top-K", 0, 100, 40, help="The number of highest probability vocabulary tokens to keep for top-k-filtering.") top_p = st.sidebar.slider("Top-P", 0.0, 1.0, 0.92, help="If set to float < 1, only the most probable tokens with probabilities that add up to top_p or higher are kept for generation.") temperature = st.sidebar.slider("Temperature", 0.0, 1.0, 0.75, help="TO COME") def on_input_change(): user_input = st.session_state.user_input result = extend(input_text=user_input, top_k=int(top_k), top_p=float(top_p), max_size=int(max_len), temperature=float(temperature) ) print(result) chat_placeholder = st.empty() with chat_placeholder.container(): message(user_input, is_user=True) message(result[0]) def on_btn_click(): del st.session_state.past[:] del st.session_state.generated[:] st.session_state.setdefault( 'past', [] ) st.session_state.setdefault( 'generated', [] ) st.markdown( """hebrew chat based on dictaLM""" ) with st.container(): st.text_input("User Input:", on_change=on_input_change, key="user_input") st.button("Clear message", on_click=on_btn_click)בתא השלישי לרשום :
!curl ipv4.icanhazip.comבתא הרביעי לרשום:
!npm install localtunnel !streamlit run app.py &>/content/logs.txt & !npx localtunnel --port 8501אז יש ללחוץ על כתובת הURL.
להעתיק את כתובת הIP מהשורה הקודמת.
להמתין עד שמופיעה ההודעה כי המודל נטען בשלמות.
@sivan22 מסיבה כלשהי colab אצלי מסרב להכיר בזה שaccelerate מותקן, למרות שההתקנה עברה בהצלחה.
לפניות בעניין הפורום וכל נושא אחר:
m@men770.gqיחי אדוננו מורנו ורבינו מלך המשיח לעולם ועד!
-
דיקטה שחררו מודל שפה בעברית בעל 7B פרמטרים, בינתיים בגרסה ראשונית. שמו של המודל: dictaLM. המודל שוחרר כקוד פתוח תחת רישיון cc 4.0.
מדובר במודל ג'נרטיבי ראשון שמשוחרר בקוד פתוח.הנה קישור לנייר הלבן בarxiv.
והנה כרטיס המודל בhuggingface.הוא שוחרר בשני גרסאות, בסיסית ומונחית פקודות, האחרונה יכולה לנהל שיח בסגנון צ'אט.
בנוסף שוחרר מודל ג'נרטיבי תורני בשם dictaLM-rab. המודל אומן על 50% עברית מודרנית ו50% עברית תורנית ממקורות שונים. למודל זה לא קיימת גרסת צ'אט.כרגע לא קיים ממשק נוח לשימוש במודל זה, וניתן לבחון אותו רק באמצעות כתיבת קוד כפי הדוגמאות בכרטיס המודל בhuggingface.
עדכון: ניתן להריץ דוגמא כאן.
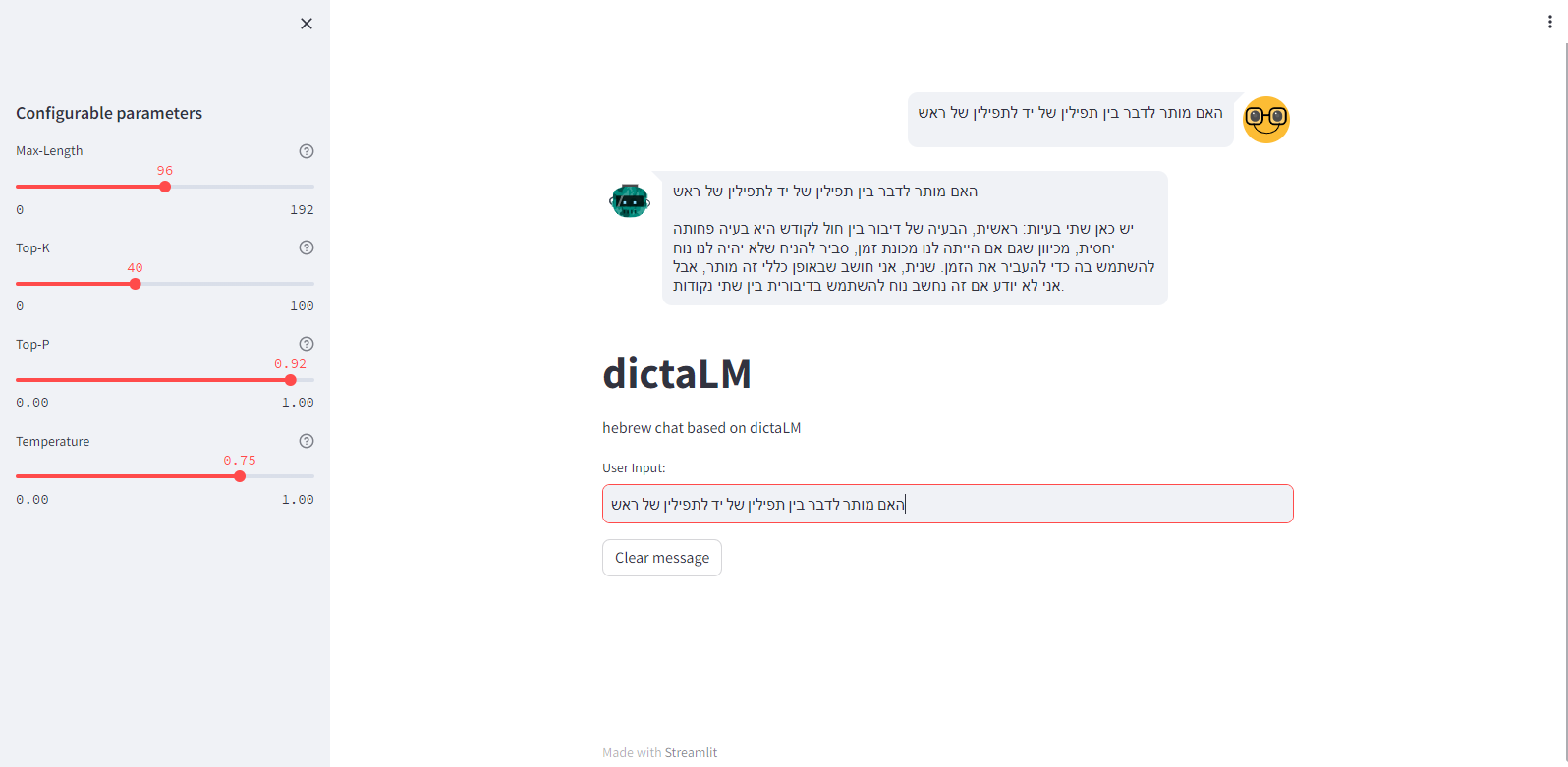
ובהקשר זה נציין שאין כרגע גירסה מוקטנת (כגון GPTQ או 4bit) כך שזה לא יהיה אפשרי להריץ אותו על המחשב הביתי, לפחות בינתיים. אם יהיו לי עדכונים, אעדכן.@sivan22 אוף, אתם מדברים גבוה מידי בשביל פשוטי עם כמוני.
לאינדקס האפליקציות והמדריכים שפירסמתי לחץ כאן
אפשר ליצור איתי קשר במייל
Ykingsmart1@gmail.com -
@sivan22 מסיבה כלשהי colab אצלי מסרב להכיר בזה שaccelerate מותקן, למרות שההתקנה עברה בהצלחה.
-
@sivan22 מסיבה כלשהי colab אצלי מסרב להכיר בזה שaccelerate מותקן, למרות שההתקנה עברה בהצלחה.
-
@Men770 כתב בשיתוף | מודל שפה חדש בעברית מבית דיקטה:
@sivan22 מסיבה כלשהי colab אצלי מסרב להכיר בזה שaccelerate מותקן, למרות שההתקנה עברה בהצלחה.
אתה חי? שנתיים וחצי לא היית כאן. ברוכים הבאים!!!
בוודאי היו לך מאות התראות
")
-
@sivan22 אוף, אתם מדברים גבוה מידי בשביל פשוטי עם כמוני.
@Ykingsmart כתב בשיתוף | מודל שפה חדש בעברית מבית דיקטה:
@sivan22 אוף, אתם מדברים גבוה מידי בשביל פשוטי עם כמוני.
לכן פרסמתי את הפוסט דווקא במתמחים טופ ולא בפורום אחר.
בכל אופן קצת רקע כללי תוכל לקרוא כאן.
-
@sivan22 ועוד אחת.
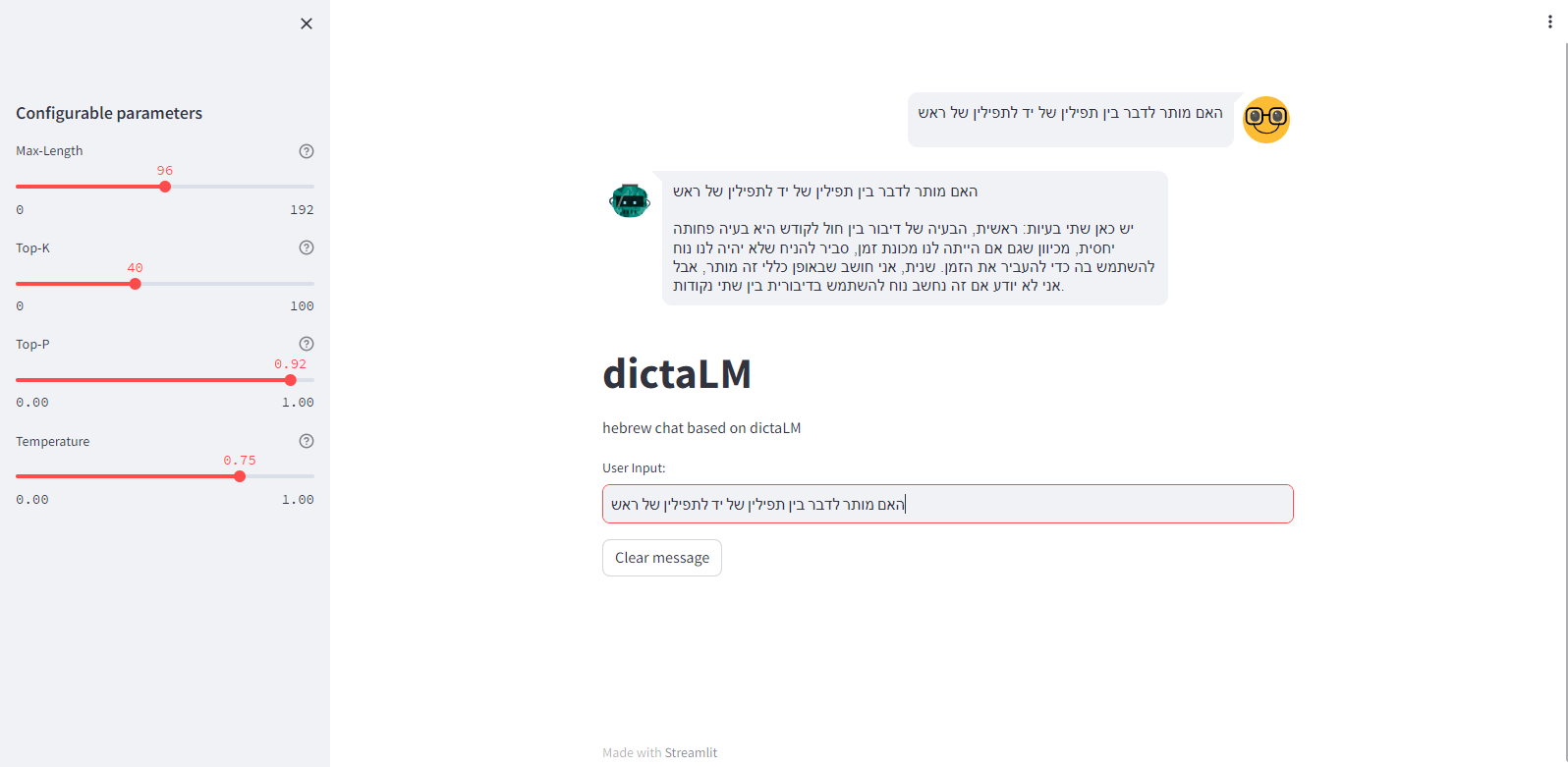
אז כן, מדובר על מודל בשלב מאד ראשוני בינתיים. גם 7 מיליארד פרמטרים זה לא הרבה.
-
@jelly כתב בשיתוף | מודל שפה חדש בעברית מבית דיקטה:
@sivan22
יש דרך לאמן אותו על דטאבייס משלי?אני מנסה זאת כעת. אעדכן בהמשך בעזרת ה'.
@jelly הנה קוד בסיסי לאימון באמצעות שיטה שנקראת LoRA ( בגדול הרעיון הוא לא לאמן את כל המודל אלא רק שכבות מסוימות) שצורכת מעט זיכרון יחסית אבל התוצאות קצת פחות טובות. לידיעתך באימון המקורי השתמשו ב8 GPU כפול 80 ג'יגה כל אחד למשך כמה ימים. כאן מספיק 16 גיגה.
!pip install -q accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7 import os, torch, logging from datasets import load_dataset from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, HfArgumentParser, TrainingArguments, pipeline from peft import LoraConfig, PeftModel from trl import SFTTrainer # Dataset data_name = "Norod78/hewiki-20220901-articles-dataset" training_data = load_dataset(data_name, split='train[0:1000]') # Model and tokenizer names base_model_name = "dicta-il/dictalm-7b" refined_model = "dictalm-7b-finetuned" # Tokenizer tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True) # Quantization Config quant_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True ) # Model base_model = AutoModelForCausalLM.from_pretrained( base_model_name, quantization_config=quant_config, device_map={"": 0}, trust_remote_code=True ) base_model.config.use_cache = False base_model.config.pretraining_tp = 1 # LoRA Config peft_parameters = LoraConfig( lora_alpha=16, lora_dropout=0.1, r=8, bias="none", task_type="CAUSAL_LM", target_modules=[r"megatron_gpt.layers.[0-31].self_attention.dense",r"megatron_gpt.layers.[0-31].mlp.dense_h_to_4h", r"megatron_gpt.layers.[0-31].mlp.dense_4h_to_h",r"megatron_gpt.layers.[0-31].self_attention.query_key_value"] ) from peft import get_peft_model peft_model = get_peft_model(base_model, peft_parameters) peft_model.print_trainable_parameters() # Training Params train_params = TrainingArguments( output_dir="./results_modified", num_train_epochs=1, per_device_train_batch_size=4, gradient_accumulation_steps=1, optim="paged_adamw_32bit", save_steps=25, logging_steps=25, learning_rate=2e-4, weight_decay=0.001, fp16=False, bf16=False, max_grad_norm=0.3, max_steps=-1, warmup_ratio=0.03, group_by_length=True, lr_scheduler_type="constant" ) # Trainer fine_tuning = SFTTrainer( model=base_model, train_dataset=training_data, peft_config=peft_parameters, dataset_text_field="text", tokenizer=tokenizer, args=train_params ) # Training fine_tuning.train() # Save Model fine_tuning.model.save_pretrained(refined_model)לאחר מכן נבחן את המודל החדש :
# Generate Text query = "הספרייה הבריטית" text_gen = pipeline(task="text-generation", model=fine_tuning.model, tokenizer=tokenizer, max_length=200) output = text_gen(query) print(output[0]['generated_text'])אבל צריך לשחק הרבה עם הפרמטרים כמובן.
-
דיקטה שחררו מודל שפה בעברית בעל 7B פרמטרים, בינתיים בגרסה ראשונית. שמו של המודל: dictaLM. המודל שוחרר כקוד פתוח תחת רישיון cc 4.0.
מדובר במודל ג'נרטיבי ראשון שמשוחרר בקוד פתוח.הנה קישור לנייר הלבן בarxiv.
והנה כרטיס המודל בhuggingface.הוא שוחרר בשני גרסאות, בסיסית ומונחית פקודות, האחרונה יכולה לנהל שיח בסגנון צ'אט.
בנוסף שוחרר מודל ג'נרטיבי תורני בשם dictaLM-rab. המודל אומן על 50% עברית מודרנית ו50% עברית תורנית ממקורות שונים. למודל זה לא קיימת גרסת צ'אט.כרגע לא קיים ממשק נוח לשימוש במודל זה, וניתן לבחון אותו רק באמצעות כתיבת קוד כפי הדוגמאות בכרטיס המודל בhuggingface.
עדכון: ניתן להריץ דוגמא כאן.
ובהקשר זה נציין שאין כרגע גירסה מוקטנת (כגון GPTQ או 4bit) כך שזה לא יהיה אפשרי להריץ אותו על המחשב הביתי, לפחות בינתיים. אם יהיו לי עדכונים, אעדכן.הכירו את Dicta-LM 2.0 – מודל שפה גדול, חינמי ופתוח בעברית

יאן לנגרמן | 03.05.2024, 10:03
עמותת דיקטה, בשיתוף מפא”ת, האיגוד הישראלי לטכנולוגיות שפת אנוש וצוות חוקרי אינטל הכולל את פטר איזאק, דניאל פליישר, משה ברציאנסקי ומשה וסרבלט הציגו את Dicta-LM 2.0, מודל שפה גדול גנרטיבי (LLM) פתוח לשימוש מסחרי ומחקרי, שהותאם לשימוש במיוחד בשפה העברית לשימושים מגוונים כצ’אטבוט, כלי תרגום ועוד.
מירוץ החימוש הגדול בתחום הבינה המלאכותית הוליד בתקופה האחרונה לא מעט מודלי AI חדשים, דוגמת Gemini של גוגל, Llama 3 של מטא ו-GPT-4 המפעיל את צ’אטבוט ה-ChatGPT של OpenAI. אך בעוד שמודלי ה-AI השונים תמכו ברמה כזו או אחרת בעברית, אף אחד מהם לא נוצר מראש לשימוש בעברית.
את זה נועד לתקן Dicta-LM 2.0, מודל בינה מלאכותית המתבסס על מודל Mistral-7B-v0.1 (של Mistral AI), עם אוסף שיפורים לתאימות גבוהה יותר לשפה העברית על הדקויות והמורכבויות שלה.
המודל עבר אימון על מיליארדי מילים בעברית להבנה טובה יותר של השפה ואימון של כ~190 מיליארד טוקנים (50% עברית ו-50% אנגלית) שבוצע על מאיצי Gaudi 2 של אינטל.
מלבד העובדה כי מודל ה-Dicta-LM 2.0 החדש מותאם לשימוש בעברית, בניגוד למודלי AI מתחרים רבים, הוא זמין להורדה ושימוש חופשיים תחת רישיון ה-Apache 2.0.
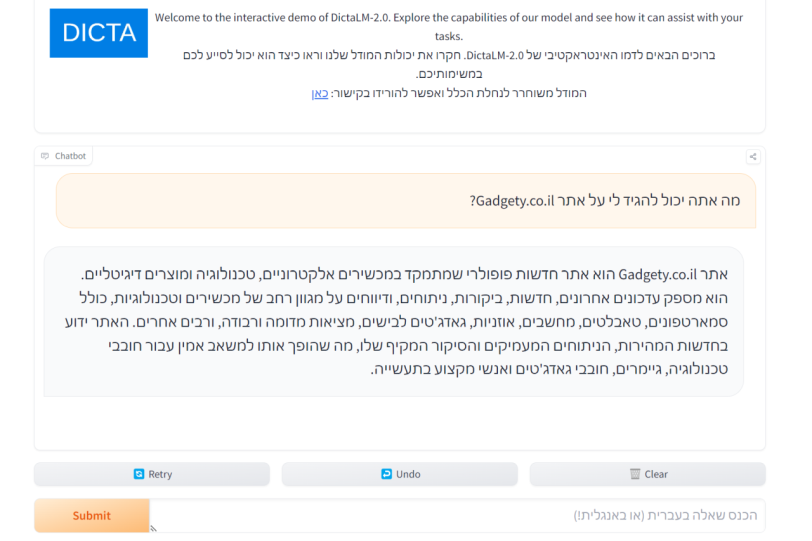
דמו מודל ה-DictaLM-2.0 (מקור huggingface)תרגום דיקטה
לצד השימוש ב-Dicta-LM 2.0 כמודל שפה גדול שיכול לשמש להפעלת צ’אטבוטים ועוד, המודל מתאים גם לשימוש ככלי תרגום מאנגלית לעברית ולהפך, עם תוצאות תרגום גבוהות יותר ממתחרים אחרים, בהם מודלים כמו Gemma , Llama ו-Mistral.
לפי הפרסום, העמותה לקחה 1000 משפטים באנגלית ותרגמה אותם לעברית באמצעות המודל החדש וכלי התרגום המוכר של גוגל. בלשן שבדק את התרגומים העדיף את התרגום של Dicta LM-2.0 מאנגלית ב-74.2% מהמקרים (742 לטובת Dicta LM-2 ו-222 לטובת גוגל עם 36 ללא הבדל בתרגום).
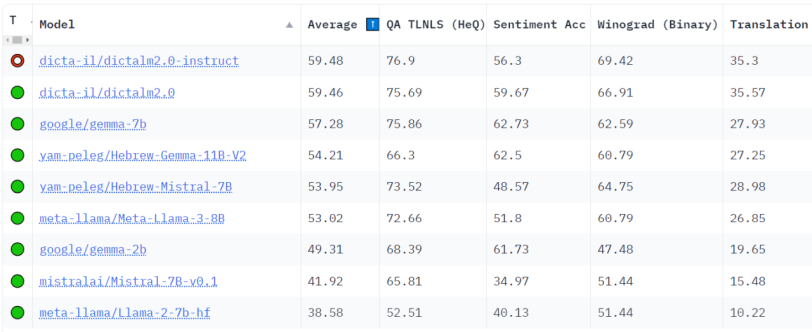
תרגום באמצעות Dicta-LM 2.0 (מקור דיקטה)מודל ה-DictaLM 2.0 זמין להורדה מאתר huggingface בו הוא גם זמין כצ’אטבוט דמו או בפיצ’ר התרגום מאנגלית לעברית באתר Dicta.
-
S sivan22 התייחס לנושא זה ב
-
ב בעל שם טוב התייחס לנושא זה ב
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}