בקשת מידע | DeepSeek המודל הסיני
-
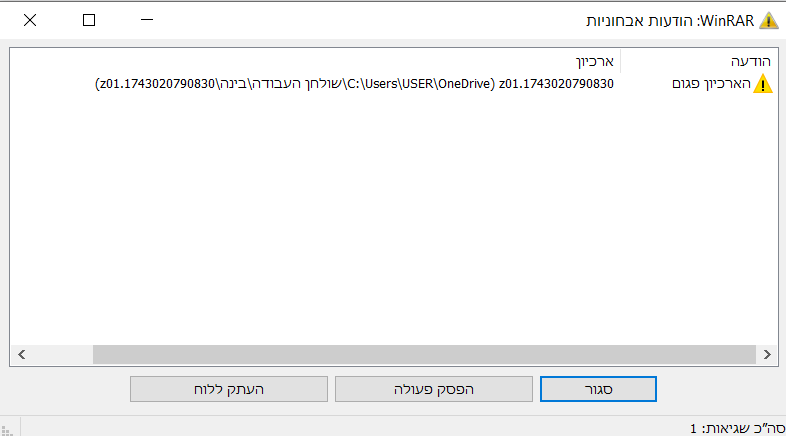
@מייבין-במקצת אני בווינדוס 10 ושמחלצים זה כותב שגיאה
-
@החפץ-בעילום-שם-0 כתב בבקשת מידע | DeepSeek המודל הסיני:
ושמחלצים
את מה? חלק אחד? או את כולם?
כל החלקים נמצאים על הנגן שלי והוא לא לידי עכשיו ככה שאין לי איך לבדוק -
@מייבין-במקצת גם אם אני מחלץ אחד וגם את כולם...
-
@החפץ-בעילום-שם-0 כתב בבקשת מידע | DeepSeek המודל הסיני:
גם אם אני מחלץ אחד וגם את כולם...
מוזר לי זכור שזה כן עבד
@אביגדור-ברמן לך זה עבד?
הנגן עדיין לא אצלי אז אני לא יכול לבדוק -
@מייבין-במקצת מה צריך לבדוק?
-
@kasnik כתב בבקשת מידע | DeepSeek המודל הסיני:
מה צריך לבדוק?
נתתי כאן הסבר איך לחלץ את הקבצים הדחוסים של המודל לקובץ אחד שהוא בעצם המודל
אבל ל @החפץ-בעילום-שם-0 זה לא עובד ואין לי את הקבצים כדי לבדוק למהולהוריד את כולם אין לי אפשרות כרגע -
@מייבין-במקצת איך אני אמור להוריד הכל?
-
@kasnik כתב בבקשת מידע | DeepSeek המודל הסיני:
איך אני אמור להוריד הכל?
אחד אחד
ניסיתי לעשות סקריפט שיוריד את כולם אבל כמו שאני מכיר את עצמי
מעכשיו עד מתי שזה יקרה יש מרחק של כמה שנות אור
-
@מייבין-במקצת כתב בבקשת מידע | DeepSeek המודל הסיני:
ניסיתי לעשות סקריפט שיוריד את כולם אבל כמו שאני מכיר את עצמי
מעכשיו עד מתי שזה יקרה יש מרחק של כמה שנות אורהאם זה טוב? קיבלתי מGPT, לא מבין בזה ולא רוצה לתקוע אתכם:
וז"ל: הנה סקריפט Python שמשתמש ב־BeautifulSoup וב־requests כדי למשוך את כל הקישורים עם הסיומות שהזכרת מהעמוד הנתון ולהוריד אותם:
import requests
from bs4 import BeautifulSoup
import osכתובת העמוד
url = "https://mitmachim.top/topic/79617/בקשת-מידע-deepseek-המודל-הסיני/200?page=10"
שליפת תוכן העמוד
response = requests.get(url)
response.raise_for_status()ניתוח ה-HTML
soup = BeautifulSoup(response.text, "html.parser")
רשימת סיומות הקבצים
extensions = [f".z{i}" for i in range(1, 45)]
איתור כל הקישורים בעמוד
links = [a['href'] for a in soup.find_all("a", href=True) if any(a['href'].endswith(ext) for ext in extensions)]
תיקייה לשמירת הקבצים
os.makedirs("downloads", exist_ok=True)
הורדת הקבצים
for link in links:
file_name = os.path.join("downloads", os.path.basename(link))
print(f"מוריד: {link}")
try:
file_response = requests.get(link, stream=True)
file_response.raise_for_status()
with open(file_name, "wb") as file:
for chunk in file_response.iter_content(chunk_size=8192):
file.write(chunk)
print(f"הורדה הסתיימה: {file_name}")
except requests.RequestException as e:
print(f"שגיאה בהורדת {link}: {e}")print("ההורדה הסתיימה!")
Answer in chat instead
הסקריפט הזה:טוען את תוכן העמוד.
משתמש ב-BeautifulSoup כדי לאתר קישורים.
מסנן קישורים שמסתיימים באחת מהסיומות שציינת.
מוריד את הקבצים ושומר אותם בתיקיית downloads.
כדי להפעיל את הקוד, ודא שיש לך את הספריות requests ו-beautifulsoup4 (אם אין לך, התקן אותן באמצעות pip install requests beautifulsoup4).
# הסקריפט למעשה:
import requests
from bs4 import BeautifulSoup
import osכתובת העמוד
url = "https://mitmachim.top/topic/79617/בקשת-מידע-deepseek-המודל-הסיני/200?page=10"
שליפת תוכן העמוד
response = requests.get(url)
response.raise_for_status()ניתוח ה-HTML
soup = BeautifulSoup(response.text, "html.parser")
רשימת סיומות הקבצים
extensions = [f".z{i}" for i in range(1, 45)]
איתור כל הקישורים בעמוד
links = [a['href'] for a in soup.find_all("a", href=True) if any(a['href'].endswith(ext) for ext in extensions)]
תיקייה לשמירת הקבצים
os.makedirs("downloads", exist_ok=True)
הורדת הקבצים
for link in links:
file_name = os.path.join("downloads", os.path.basename(link))
print(f"מוריד: {link}")
try:
file_response = requests.get(link, stream=True)
file_response.raise_for_status()
with open(file_name, "wb") as file:
for chunk in file_response.iter_content(chunk_size=8192):
file.write(chunk)
print(f"הורדה הסתיימה: {file_name}")
except requests.RequestException as e:
print(f"שגיאה בהורדת {link}: {e}")print("ההורדה הסתיימה!")
-
א אהרן התייחס לנושא זה
-
תכלס
חילצתי את הקבצים
והמודל לא עובד לי בנגן -
-
@אביגדור-ברמן כתב בבקשת מידע | DeepSeek המודל הסיני:
תכלס
חילצתי את הקבצים
והמודל לא עובד לי בנגןכמה RAM יש לך בו?
-
@אביגדור-ברמן כתב בבקשת מידע | DeepSeek המודל הסיני:
@א-מ-ד 15 RAM
אני מהמר שזה ג'לי סטאר
אני צודק?
א''כ זה לא באמת 15, זה 8 ועוד 7,
שממש לא מומלץ להשתמש בהרחבה
וכדאיתא -
@kasnik זה לא גלי סטאר
ונכון יש הרחבה
אבל זה לא הנקודה
מודלים הרבה יותר חזקים רצים על המכשיר
והמודל הזה
זה לא שהוא לא רץ
האפליקציה לא מוכנה לקרוא אותו
היא טוענת שמודל לא תקין! -
@אביגדור-ברמן כתב בבקשת מידע | DeepSeek המודל הסיני:
אבל זה לא הנקודה
סבבה
אבל אל תחשבו את הרחבה כראם

{if(result!=null&&result!=''){var a=document.createElement('a');a.href='https://www.google.co.il/search?q=site:mitmachim.top '+encodeURIComponent(result.trim());a.target='_blank';a.click();}}})();};){kind=link}