הצעת ייעול | קונספט חדש לפרוייקט השו״ת
-
חברה, אני ממש נפעם ממה שקורה פה - קבוצה של צעירים (ברובם, אני מניח), מרימים את הככפה וללא כל כוונת רווח הולכים לזכות את הרבים באחד הדברים הענקיים שהיו בעולם התורני בעשורים האחרונים, איזה אברך בעל מחשב לא חולם על מאגר נוח וקל לשימוש שיאגד בתוכו את כל הספרים שזמינים חינם מפה ומשם, זה פשוט מדהים מה שאתם עושים, חבל שאין לי את הכישורים לעזור, חילכם לאורייתא, עלו והצליחו!
אני רק מנסה להבין, האם מדובר במאגר שיכלול רק ספרי טקסט? רק ספרי PDF או גם וגם?
@א-א-א כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
איזה אברך בעל מחשב לא חולם על מאגר נוח וקל לשימוש שיאגד בתוכו את כל הספרים שזמינים חינם מפה ומשם
לא מדוייק הפרוייקט מתמקד בספרים של ספריא - שהם למעשה מפה ומשם....
-
@pcinfogmach @לא-מתייאש בהמשך לדיון על מסד הנתונים של ספריא, התחלתי לעבוד על המרה לSQLite, וזה באמת המון עבודה. גיליתי שיש שם כל כך הרבה דאטה, שזה פשוט לא לעניין לא להשתמש בזה, אבל מצד שני זה גם לא פשוט בכלל לחלץ כל כך הרבה מידע.
בינתיים חילצתי להדגמה רק כמה נתונים בסיסיים ממש:
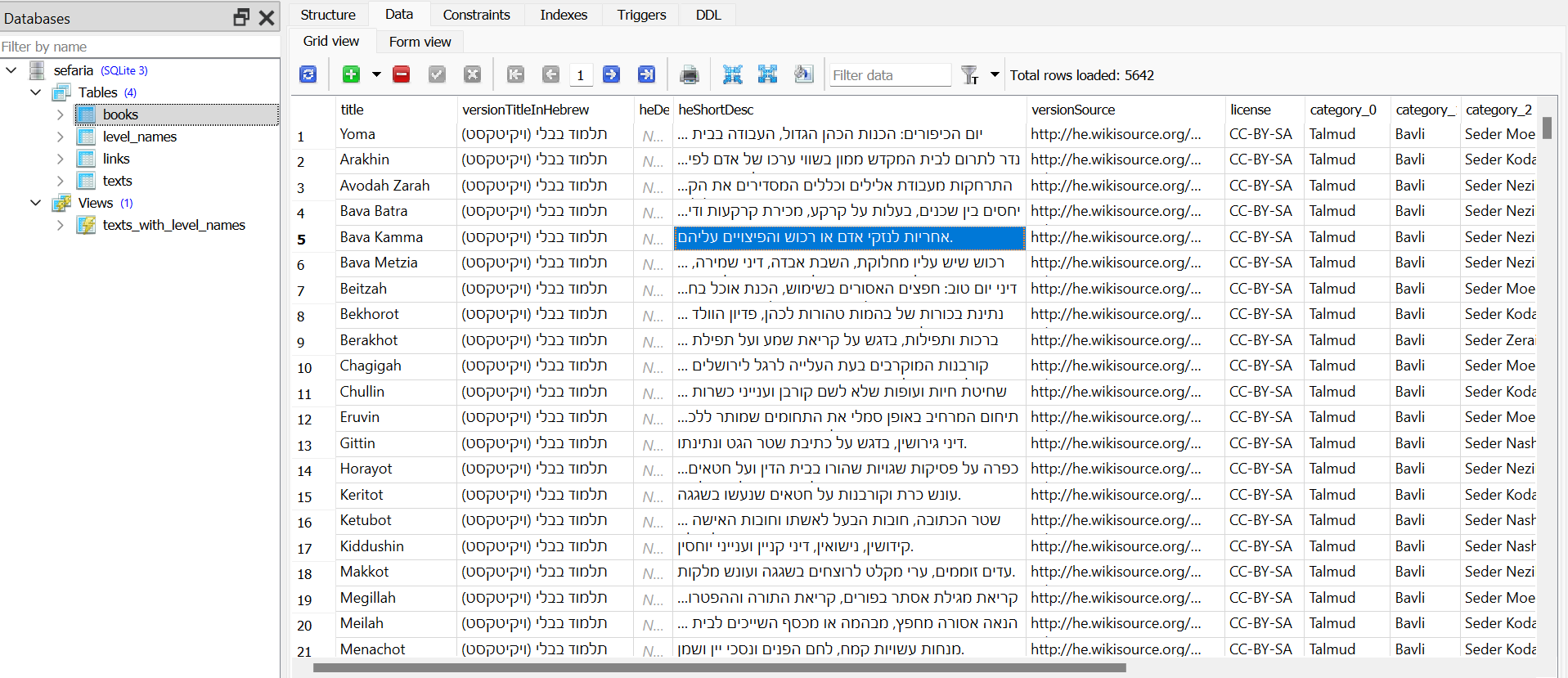
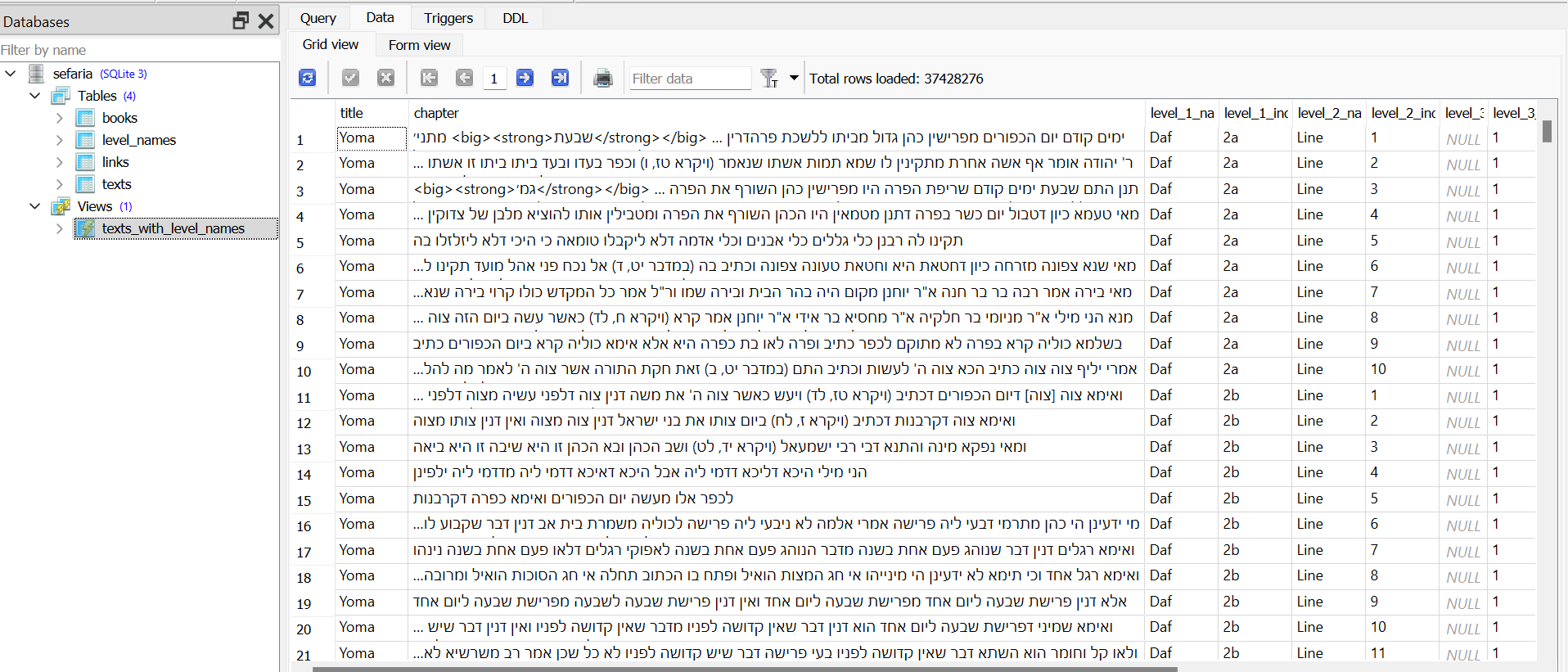
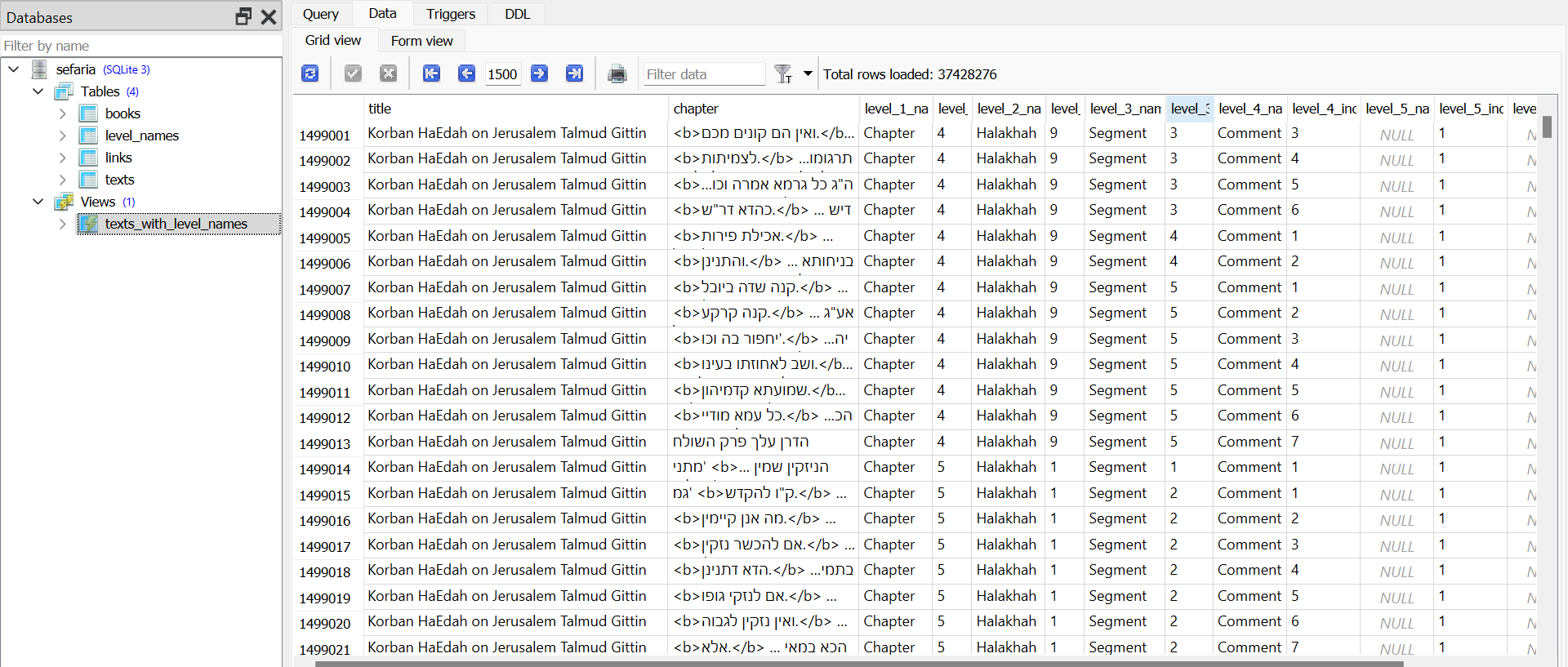
לצורך העבודה השתמשתי בעיקר בספריית pandas (הרי אני כיום מתיימר להיות מדען נתונים),וגם קצת בaggragation של MongoDB.
העליתי את הקוד של ההמרה לגיטהאב.
ואת המסד נתונים עצמו אני אעלה בהמשך להגי פייס.אבל יש עוד הרבה מאד עבודה עד שזה יהיה ראוי לשימוש אפילו מינימלי.
מה שחסר במיוחד כרגע, זה כל השמות בעברית. יש אותם כמובן במסד נתונים, אבל צריך לחלץ אותם מעומק העץ של MongoDB.@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
מה שחסר במיוחד כרגע, זה כל השמות בעברית. יש אותם כמובן במסד נתונים, אבל צריך לחלץ אותם מעומק העץ של MongoDB.
schema?.titles.find(t => t.lang === 'he' && t.primary).text -
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
מה שחסר במיוחד כרגע, זה כל השמות בעברית. יש אותם כמובן במסד נתונים, אבל צריך לחלץ אותם מעומק העץ של MongoDB.
schema?.titles.find(t => t.lang === 'he' && t.primary).text@meir-lamdan כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
מה שחסר במיוחד כרגע, זה כל השמות בעברית. יש אותם כמובן במסד נתונים, אבל צריך לחלץ אותם מעומק העץ של MongoDB.
schema?.titles.find(t => t.lang === 'he' && t.primary).textתודה רבה, יפה מאד! אני לא השתמשתי בשרת node אלא בפייתון עם pymongo וישר לpandas, אז הקוד שלי בסוף נראה כך:
def get_he_title(obj)->object: if 'titles' in obj: for title in obj['titles']: if title['lang'] == 'he' and 'primary' in title: return title['text'] return None books['he_title']=books['schema'].apply(get_he_title)אין ספק שהקוד בJS יותר אלגנטי (במקרה הזה), אבל הביצועים של pandas הם הרבה יותר מהירים, גם בגלל הספרייה החזקה, וגם בגלל שהכל בראם בלי שרת.
-
@meir-lamdan כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
מה שחסר במיוחד כרגע, זה כל השמות בעברית. יש אותם כמובן במסד נתונים, אבל צריך לחלץ אותם מעומק העץ של MongoDB.
schema?.titles.find(t => t.lang === 'he' && t.primary).textתודה רבה, יפה מאד! אני לא השתמשתי בשרת node אלא בפייתון עם pymongo וישר לpandas, אז הקוד שלי בסוף נראה כך:
def get_he_title(obj)->object: if 'titles' in obj: for title in obj['titles']: if title['lang'] == 'he' and 'primary' in title: return title['text'] return None books['he_title']=books['schema'].apply(get_he_title)אין ספק שהקוד בJS יותר אלגנטי (במקרה הזה), אבל הביצועים של pandas הם הרבה יותר מהירים, גם בגלל הספרייה החזקה, וגם בגלל שהכל בראם בלי שרת.
-
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
שרת Django
??
node מקומי יעשה א"ז לאט יותר מפייתון?@אפי-זינגר ל2 מיליון רשומות? נראה לי שכן. pandas כתובה בכלל בc++
-
@אפי-זינגר ל2 מיליון רשומות? נראה לי שכן. pandas כתובה בכלל בc++
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@אפי-זינגר ל2 מיליון רשומות? נראה לי שכן. pandas כתובה בכלל בc++
V8 מחשב בעפרון על האוזן?
גם C++ -
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@אפי-זינגר ל2 מיליון רשומות? נראה לי שכן. pandas כתובה בכלל בc++
V8 מחשב בעפרון על האוזן?
גם C++@אפי-זינגר הדרך היחידה להכריע היא לבדוק בפועל. האמת שמאד קשה להשוות בין טכנולוגיות כל כך שונות. pandas פועלת על הרשומות במקביל באלגוריתמים מעולם המטריצות וnumPy, ולכן יש לה יעילות מעוררת השתאות במסדי נתונים גדולים. בנוד יש אינספור I\O שרצים באופן א-סינכרוני. אז קשה מאד לדעת מה עדיף. אולי זה גם תלוי מה המטלה.
-
@meir-lamdan כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
מה שחסר במיוחד כרגע, זה כל השמות בעברית. יש אותם כמובן במסד נתונים, אבל צריך לחלץ אותם מעומק העץ של MongoDB.
schema?.titles.find(t => t.lang === 'he' && t.primary).textתודה רבה, יפה מאד! אני לא השתמשתי בשרת node אלא בפייתון עם pymongo וישר לpandas, אז הקוד שלי בסוף נראה כך:
def get_he_title(obj)->object: if 'titles' in obj: for title in obj['titles']: if title['lang'] == 'he' and 'primary' in title: return title['text'] return None books['he_title']=books['schema'].apply(get_he_title)אין ספק שהקוד בJS יותר אלגנטי (במקרה הזה), אבל הביצועים של pandas הם הרבה יותר מהירים, גם בגלל הספרייה החזקה, וגם בגלל שהכל בראם בלי שרת.
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
אני לא השתמשתי בשרת Django
Django זה פריימוורק פייתון, נראה שהתבלבלת במילה
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
אין ספק שהקוד בJS יותר אלגנטי (במקרה הזה), אבל הביצועים של pandas הם הרבה יותר מהירים, גם בגלל הספרייה החזקה, וגם בגלל שהכל בראם בלי שרת.
מה זה "שרת"? לפייתון יש "שרת" בדיוק כמו שלnode יש, ואם אתה טוען את המידע לזכרון אז הוא בראם גם בנוד וגם בפייתון, רק שאתה משתמש בספריה כדי לעבד את המידע אח"כ
אני אגב מעריך שמה שיהיה הכי יעיל זה שאילתה מתאימה ישירות למונגו ולא לטעון הכל לזיכרון ואז לולאות או ספריות
תכלס ברגע שמדובר על חילוץ מידע חד פעמי זה לא משנה כל כך הביצועים -
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@אפי-זינגר ל2 מיליון רשומות? נראה לי שכן. pandas כתובה בכלל בc++
V8 מחשב בעפרון על האוזן?
גם C++ -
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
אני לא השתמשתי בשרת Django
Django זה פריימוורק פייתון, נראה שהתבלבלת במילה
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
אין ספק שהקוד בJS יותר אלגנטי (במקרה הזה), אבל הביצועים של pandas הם הרבה יותר מהירים, גם בגלל הספרייה החזקה, וגם בגלל שהכל בראם בלי שרת.
מה זה "שרת"? לפייתון יש "שרת" בדיוק כמו שלnode יש, ואם אתה טוען את המידע לזכרון אז הוא בראם גם בנוד וגם בפייתון, רק שאתה משתמש בספריה כדי לעבד את המידע אח"כ
אני אגב מעריך שמה שיהיה הכי יעיל זה שאילתה מתאימה ישירות למונגו ולא לטעון הכל לזיכרון ואז לולאות או ספריות
תכלס ברגע שמדובר על חילוץ מידע חד פעמי זה לא משנה כל כך הביצועים@צדיק-תמים כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת
אני אגב מעריך שמה שיהיה הכי יעיל זה שאילתה מתאימה ישירות למונגו ולא לטעון הכל לזיכרון ואז לולאות או ספריות
דווקא לא, כי שרת mongo הוא מאד איטי, בוודאי ביחס לpandas או node. וכאן הטענה שלי ודאי תקפה.
תכלס ברגע שמדובר על חילוץ מידע חד פעמי זה לא משנה כל כך הביצועים
יש הרבה ניסוי וטעייה והרצתי את הקוד כמה וכמה פעמים, ומדובר על 3.5m רשומות.
החילוץ הוא בהתחלה להעביר הכל לpandad או לdjango.אכן טעיתי כשקראתי לקוד בnode בשם הלא קשור בכלל Django. כוונתי היתה לשרת node. ונדמה לי שהמימוש של mongo בnode הוא באמת לא טוען את הכל לראם אלא רק מתווך את שרת המונגו, מה שמאשש את הטענה שמדובר בהרבה מאד I/o
-
@צדיק-תמים כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת
אני אגב מעריך שמה שיהיה הכי יעיל זה שאילתה מתאימה ישירות למונגו ולא לטעון הכל לזיכרון ואז לולאות או ספריות
דווקא לא, כי שרת mongo הוא מאד איטי, בוודאי ביחס לpandas או node. וכאן הטענה שלי ודאי תקפה.
תכלס ברגע שמדובר על חילוץ מידע חד פעמי זה לא משנה כל כך הביצועים
יש הרבה ניסוי וטעייה והרצתי את הקוד כמה וכמה פעמים, ומדובר על 3.5m רשומות.
החילוץ הוא בהתחלה להעביר הכל לpandad או לdjango.אכן טעיתי כשקראתי לקוד בnode בשם הלא קשור בכלל Django. כוונתי היתה לשרת node. ונדמה לי שהמימוש של mongo בnode הוא באמת לא טוען את הכל לראם אלא רק מתווך את שרת המונגו, מה שמאשש את הטענה שמדובר בהרבה מאד I/o
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@צדיק-תמים כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת
אני אגב מעריך שמה שיהיה הכי יעיל זה שאילתה מתאימה ישירות למונגו ולא לטעון הכל לזיכרון ואז לולאות או ספריות
דווקא לא, כי שרת mongo הוא מאד איטי, בוודאי ביחס לpandas או node
בשליפה נתונים עם שאילתה מדויקת שזה מהות תפקידו של מסד נתונים ועל אחת כמה וכמה מסד מונגו (NoSql שכל הרעיון שהוא נולד זה עלויות אחסון - ומהירות), ברור לי שאתה טועה ביחס לנוד, את pandas אני לא מכיר
-
@sivan22 כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@צדיק-תמים כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת
אני אגב מעריך שמה שיהיה הכי יעיל זה שאילתה מתאימה ישירות למונגו ולא לטעון הכל לזיכרון ואז לולאות או ספריות
דווקא לא, כי שרת mongo הוא מאד איטי, בוודאי ביחס לpandas או node
בשליפה נתונים עם שאילתה מדויקת שזה מהות תפקידו של מסד נתונים ועל אחת כמה וכמה מסד מונגו (NoSql שכל הרעיון שהוא נולד זה עלויות אחסון - ומהירות), ברור לי שאתה טועה ביחס לנוד, את pandas אני לא מכיר
@צדיק-תמים נראה לי שדיברתי הרבה שטויות והראיתי את הבורות שלי.
לסיכום, בשביל להעביר נתונים מmongoDB לsqlite, הקושי המרכזי הוא לא במימוש אלא בתכנון, זאת אומרת להעביר מעץ עמוק מאד, למספר טבלאות דו מימדית, זה דורש הכרעות לגבי הייצוג שהוא בהכרח יהיה שונה.
אופן המימוש יכול להיות באמצעות שאילתה של מונגו:
[ { '$set': { 'he_title': { '$filter': { 'input': '$schema.titles', 'as': 'he_titles', 'cond': { '$eq': [ '$$he_titles.primary', True ] }, 'limit': 2 } } } }, { '$set': { 'he_title': { '$filter': { 'input': '$he_title', 'as': 'he_titles', 'cond': { '$eq': [ '$$he_titles.lang', 'he' ] }, 'limit': 2 } } } }, { '$set': { 'he_title': { '$arrayElemAt': [ '$he_title.text', 0 ] } } } ]או באמצעות קליטת הנתונים בנוד, ואז שימוש ביכולות ההתמודדות הטובות של JS עם dictionaries.:
myColl.find(); schema?.titles.find(t => t.lang === 'he' && t.primary).textאו בפייתון, לשבור את השיניים עם חוסר תמיכה נוח בdictionaries:
def get_he_title(obj)->object: if 'titles' in obj: for title in obj['titles']: if title['lang'] == 'he' and 'primary' in title: return title['text'] return None books['he_title']=books['schema'].apply(get_he_title)ואפשר בכלל להשתמש בJAVA עם קובץ JSON שיצא כפלט מהמסד נתונים:
protected static int addText(Connection c, JSONObject enJSON, JSONObject heJSON, JSONObject schemaFile) throws JSONException{ if(enJSON == null && heJSON == null){ System.err.print("Both JSONs are null in Node.addText()"); return -1; } int enLang =0,heLang=0; String title =""; JSONObject node = null; if(enJSON != null){ enLang = returnLangNums(enJSON.getString("language")); title = enJSON.getString("title"); node = (JSONObject) enJSON.get("schema"); } if(heJSON != null){ heLang = returnLangNums(heJSON.getString("language")); title = heJSON.getString("title"); node = (JSONObject) heJSON.get("schema"); } int lang = enLang + heLang; /** * check for errors */ if((enLang != SQLite.LANG_EN && enLang != 0)|| (heLang != SQLite.LANG_HE && heLang != 0)){ System.err.println("Error in Node.addText(): not right lang numbers. enLang:" + enLang + " heLang:" + heLang); return -1; } if(title.equals("")){ System.err.println("no Title"); return -1; } if(enJSON != null && heJSON != null){ if(!heJSON.get("schema").toString().equals(enJSON.get("schema").toString())){ System.err.println("en and he JSONs schemas don't match\n"); System.out.println(heJSON.get("schema")); System.out.println(enJSON.get("schema")); return -1; } if(!enJSON.getString("title").equals(heJSON.getString("title"))){ System.err.println("en and he JSONs title don't match" + enJSON.getString("title") + " - " + heJSON.getString("title")); return -1; } } if(!booksInDB.containsKey(title)){ System.err.println("Don't have book in DB and trying to add text"); return -1; } int bid = booksInDBbid.get(title); JSONObject enText = null, heText = null; if(enJSON != null){ enText = (JSONObject) enJSON.get("text"); } if(heJSON != null){ heText = (JSONObject) heJSON.get("text"); } JSONObject schema = null; try{ schema = schemaFile.getJSONObject("schema"); }catch(JSONException e){ e.printStackTrace(); } insertNode(c, schema, enText,heText, 0,0,bid,0,lang); return 1; //it worked } -
כמה הערות:
א' בכל ספר יש את גירסת ה"mergd" וגירסאות אחרות, הקובץ הרצוי לכאו' הוא קובץ הmergd ,הוא מכיל טקסט ממוזג מכמה גירסאות [גם במקרה שיש רק גירסא אחת יש קובץ mergd שזהה לקובץ השני]
שאר הקבצים לדעתי מיותרים וסתם יתפסו מקום במחשב
ב' יהיה שימושי מאוד לדעתי לעשות גם את שאר הפיצ'רים של ספריא [פרשנים, קישורים לספרים אחרים וכו'] וכמובן לאפשר ניווט לפי כותרות
ג' אולי גם להוסיף אפשרות לחיפוש ספרים מהיברו בוקס ואוצר החכמה ולאפשר פתיחה באתר [וגם בתוכנה, לאוצר החכמה] יש לי כאן קובץ לאוצר החכמה שכולל לינקים לאתר ולתוכנה, וכאן יש לי קובץ להיברו בוקס שמאפשר הורדה, צפייה בדפדפן והדף הראשי של הספר
ד' שכל הספרים שיסננו יהיו ברשימה שחורה, כך שיהיה אפשר לעדכן את התוכנה מעת לעת [אולי אפי' לאפשר עדכון מתוך התוכנה בעצמה]
ה' להוסיף תמיכה גם בקבצי טקסט בקידוד ansi ולאפשר טעינת קבצים מתיקיות נוספות ועל ידי כך ניתן יהיה לגשת לכל הספרים של תורת אמת מתוך התוכנה ולייתר מעבר בין תוכנות [אני מאמין שיש ל @pcinfogmach קובץ שכולל בתוכו את כל שמות הספרים מתורת אמת בעברית]
יש"כ עצום על היוזמה הנפלאה. -
כמה הערות:
א' בכל ספר יש את גירסת ה"mergd" וגירסאות אחרות, הקובץ הרצוי לכאו' הוא קובץ הmergd ,הוא מכיל טקסט ממוזג מכמה גירסאות [גם במקרה שיש רק גירסא אחת יש קובץ mergd שזהה לקובץ השני]
שאר הקבצים לדעתי מיותרים וסתם יתפסו מקום במחשב
ב' יהיה שימושי מאוד לדעתי לעשות גם את שאר הפיצ'רים של ספריא [פרשנים, קישורים לספרים אחרים וכו'] וכמובן לאפשר ניווט לפי כותרות
ג' אולי גם להוסיף אפשרות לחיפוש ספרים מהיברו בוקס ואוצר החכמה ולאפשר פתיחה באתר [וגם בתוכנה, לאוצר החכמה] יש לי כאן קובץ לאוצר החכמה שכולל לינקים לאתר ולתוכנה, וכאן יש לי קובץ להיברו בוקס שמאפשר הורדה, צפייה בדפדפן והדף הראשי של הספר
ד' שכל הספרים שיסננו יהיו ברשימה שחורה, כך שיהיה אפשר לעדכן את התוכנה מעת לעת [אולי אפי' לאפשר עדכון מתוך התוכנה בעצמה]
ה' להוסיף תמיכה גם בקבצי טקסט בקידוד ansi ולאפשר טעינת קבצים מתיקיות נוספות ועל ידי כך ניתן יהיה לגשת לכל הספרים של תורת אמת מתוך התוכנה ולייתר מעבר בין תוכנות [אני מאמין שיש ל @pcinfogmach קובץ שכולל בתוכו את כל שמות הספרים מתורת אמת בעברית]
יש"כ עצום על היוזמה הנפלאה. -
כמה הערות:
א' בכל ספר יש את גירסת ה"mergd" וגירסאות אחרות, הקובץ הרצוי לכאו' הוא קובץ הmergd ,הוא מכיל טקסט ממוזג מכמה גירסאות [גם במקרה שיש רק גירסא אחת יש קובץ mergd שזהה לקובץ השני]
שאר הקבצים לדעתי מיותרים וסתם יתפסו מקום במחשב
ב' יהיה שימושי מאוד לדעתי לעשות גם את שאר הפיצ'רים של ספריא [פרשנים, קישורים לספרים אחרים וכו'] וכמובן לאפשר ניווט לפי כותרות
ג' אולי גם להוסיף אפשרות לחיפוש ספרים מהיברו בוקס ואוצר החכמה ולאפשר פתיחה באתר [וגם בתוכנה, לאוצר החכמה] יש לי כאן קובץ לאוצר החכמה שכולל לינקים לאתר ולתוכנה, וכאן יש לי קובץ להיברו בוקס שמאפשר הורדה, צפייה בדפדפן והדף הראשי של הספר
ד' שכל הספרים שיסננו יהיו ברשימה שחורה, כך שיהיה אפשר לעדכן את התוכנה מעת לעת [אולי אפי' לאפשר עדכון מתוך התוכנה בעצמה]
ה' להוסיף תמיכה גם בקבצי טקסט בקידוד ansi ולאפשר טעינת קבצים מתיקיות נוספות ועל ידי כך ניתן יהיה לגשת לכל הספרים של תורת אמת מתוך התוכנה ולייתר מעבר בין תוכנות [אני מאמין שיש ל @pcinfogmach קובץ שכולל בתוכו את כל שמות הספרים מתורת אמת בעברית]
יש"כ עצום על היוזמה הנפלאה.@האדם-החושב כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
הקובץ הרצוי לכאו' הוא קובץ הmergd ,הוא מכיל טקסט ממוזג מכמה גירסאות [גם במקרה שיש רק גירסא אחת יש קובץ mergd שזהה לקובץ השני]
יש קבצים שלא הספיקו לעשות להם merged עיין מאירי על הש"ס (חלק מהם) לדוגמא.
@האדם-החושב כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
לכל הספרים של תורת אמת מתוך התוכנה ולייתר מעבר בין תוכנות
אני בעד
@האדם-החושב כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
[אני מאמין שיש ל @pcinfogmach קובץ שכולל בתוכו את כל שמות הספרים מתורת אמת בעברית]
כן
למרות שהנושא בספרים הללו הוא לא רק הקידוד אלא גם כל הקודים האישיים שהמחבר הכניס. אני באמצע לחבר תוכנה שתעזור עם ההמרה אבל מישהו יצטרך להרים את הכפפה ולעשות את העבודת כפיים. -
@צדיק-תמים נראה לי שדיברתי הרבה שטויות והראיתי את הבורות שלי.
לסיכום, בשביל להעביר נתונים מmongoDB לsqlite, הקושי המרכזי הוא לא במימוש אלא בתכנון, זאת אומרת להעביר מעץ עמוק מאד, למספר טבלאות דו מימדית, זה דורש הכרעות לגבי הייצוג שהוא בהכרח יהיה שונה.
אופן המימוש יכול להיות באמצעות שאילתה של מונגו:
[ { '$set': { 'he_title': { '$filter': { 'input': '$schema.titles', 'as': 'he_titles', 'cond': { '$eq': [ '$$he_titles.primary', True ] }, 'limit': 2 } } } }, { '$set': { 'he_title': { '$filter': { 'input': '$he_title', 'as': 'he_titles', 'cond': { '$eq': [ '$$he_titles.lang', 'he' ] }, 'limit': 2 } } } }, { '$set': { 'he_title': { '$arrayElemAt': [ '$he_title.text', 0 ] } } } ]או באמצעות קליטת הנתונים בנוד, ואז שימוש ביכולות ההתמודדות הטובות של JS עם dictionaries.:
myColl.find(); schema?.titles.find(t => t.lang === 'he' && t.primary).textאו בפייתון, לשבור את השיניים עם חוסר תמיכה נוח בdictionaries:
def get_he_title(obj)->object: if 'titles' in obj: for title in obj['titles']: if title['lang'] == 'he' and 'primary' in title: return title['text'] return None books['he_title']=books['schema'].apply(get_he_title)ואפשר בכלל להשתמש בJAVA עם קובץ JSON שיצא כפלט מהמסד נתונים:
protected static int addText(Connection c, JSONObject enJSON, JSONObject heJSON, JSONObject schemaFile) throws JSONException{ if(enJSON == null && heJSON == null){ System.err.print("Both JSONs are null in Node.addText()"); return -1; } int enLang =0,heLang=0; String title =""; JSONObject node = null; if(enJSON != null){ enLang = returnLangNums(enJSON.getString("language")); title = enJSON.getString("title"); node = (JSONObject) enJSON.get("schema"); } if(heJSON != null){ heLang = returnLangNums(heJSON.getString("language")); title = heJSON.getString("title"); node = (JSONObject) heJSON.get("schema"); } int lang = enLang + heLang; /** * check for errors */ if((enLang != SQLite.LANG_EN && enLang != 0)|| (heLang != SQLite.LANG_HE && heLang != 0)){ System.err.println("Error in Node.addText(): not right lang numbers. enLang:" + enLang + " heLang:" + heLang); return -1; } if(title.equals("")){ System.err.println("no Title"); return -1; } if(enJSON != null && heJSON != null){ if(!heJSON.get("schema").toString().equals(enJSON.get("schema").toString())){ System.err.println("en and he JSONs schemas don't match\n"); System.out.println(heJSON.get("schema")); System.out.println(enJSON.get("schema")); return -1; } if(!enJSON.getString("title").equals(heJSON.getString("title"))){ System.err.println("en and he JSONs title don't match" + enJSON.getString("title") + " - " + heJSON.getString("title")); return -1; } } if(!booksInDB.containsKey(title)){ System.err.println("Don't have book in DB and trying to add text"); return -1; } int bid = booksInDBbid.get(title); JSONObject enText = null, heText = null; if(enJSON != null){ enText = (JSONObject) enJSON.get("text"); } if(heJSON != null){ heText = (JSONObject) heJSON.get("text"); } JSONObject schema = null; try{ schema = schemaFile.getJSONObject("schema"); }catch(JSONException e){ e.printStackTrace(); } insertNode(c, schema, enText,heText, 0,0,bid,0,lang); return 1; //it worked } -
@צדיק-תמים כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@sivan22 השאילתה שהבאת היא אפילו לא pseudo code
")
למה אתה אומר ככה, השתמשתי בה בפועל, רק חסר שתי שורות בהתחלה.
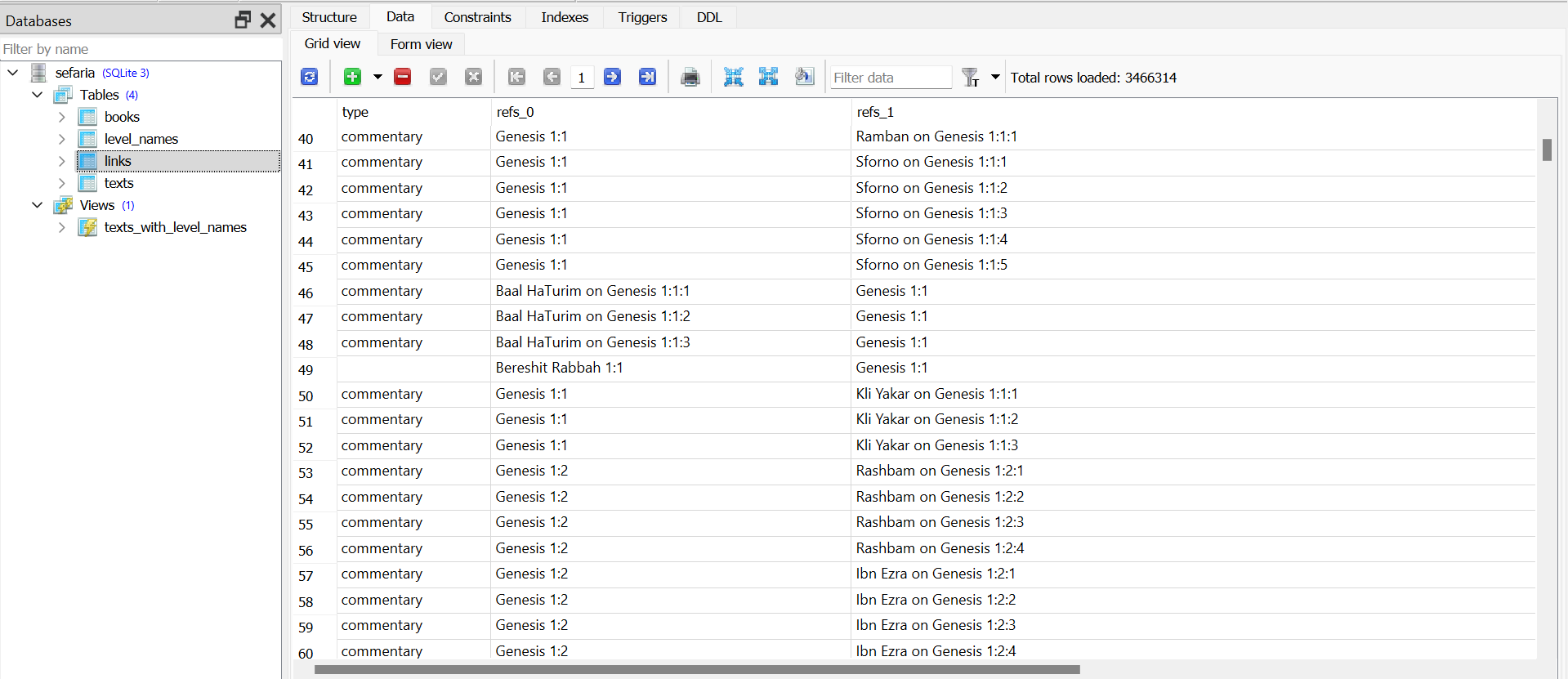
from pymongo import MongoClient # Requires the PyMongo package. # https://api.mongodb.com/python/current client = MongoClient('mongodb://localhost:27017/') result = client['sefaria']['links'].aggregate([ { '$set': { 'refs_0': { '$arrayElemAt': [ '$refs', 0 ] }, 'refs_1': { '$arrayElemAt': [ '$refs', 1 ] } } }, { '$unset': [ '_id', 'expandedRefs0', 'expandedRefs1', 'availableLangs', 'refs' ] } ]) -
דבר ראשון כל הכבוד לכל התורמים מזמנם למען הרחבת נוחות ואיכות הלימוד של לומדי התורה שליט"א!
יה"ר שתשרה הברכה במעשה ידיכם!
כמה הערות:
א. להיברו בוקס יש כל מיני תוכניות לעתיד. נכון ללפני כמה חודשים לא משהו מוגדר. מהסיבה הזאת הוא לא מתיר כרגע ליצור מהמאגר שלו משהו אחר. אפשר להתכתב איתם במייל. יש עם מי לדבר. (כמובן שאני אומר ממה ששמעתי ואני לא קשור אליהם בצורה כלשהיא)
ב. יש גמח של מאה גיגה+ ספרים תורניים בPDF. יתכן שהוא יושיט יד כדי לקדם את זה. שלחתי את הכתובת מייל שלו לsivan22.
ג. לדעתי מאוד חשוב להקפיד על עניין המהירות והנגישות של הפונקציות של התוכנה. מי שמשתמש בזה הוא הרי מישהו שבאמצע ללמוד וחבל על כל שניה...
הרבה הצלחה בכל! -
@צדיק-תמים כתב בהצעת ייעול | קונספט חדש לפרוייקט השו״ת:
@sivan22 השאילתה שהבאת היא אפילו לא pseudo code
למה אתה אומר ככה, השתמשתי בה בפועל, רק חסר שתי שורות בהתחלה.
from pymongo import MongoClient # Requires the PyMongo package. # https://api.mongodb.com/python/current client = MongoClient('mongodb://localhost:27017/') result = client['sefaria']['links'].aggregate([ { '$set': { 'refs_0': { '$arrayElemAt': [ '$refs', 0 ] }, 'refs_1': { '$arrayElemAt': [ '$refs', 1 ] } } }, { '$unset': [ '_id', 'expandedRefs0', 'expandedRefs1', 'availableLangs', 'refs' ] } ]) -
@צדיק-תמים נכון זה היה דוגמא מערך אחר. אבל עכשיו באמת החלפתי שם לעיל את הקוד לשאילתה שבודקת מה ששני הקודים האחרים בדקו.
 { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}