מכיון ש גימייל.קום בכל מקרה לא תפוס, אולי אתפוס אותו ואעשה שינתב למייל.קום...
עריכה: בוצע (הקנייה, ההפנייה עוד לא)
מכיון ש גימייל.קום בכל מקרה לא תפוס, אולי אתפוס אותו ואעשה שינתב למייל.קום...
עריכה: בוצע (הקנייה, ההפנייה עוד לא)
להשתמש במותג של ג'ימייל רק מזמין לי את עורכי הדין של גוגל
אני כן פתוח לרעיון של הוספת דומיינים נוספים, אם יהיה משהו מוצלח ויהיה בזה תועלת
@יודע-ומייבין אי אפשר
אני לא יכול לספק כתובת של gmail
@יוסף-דובער תצור קשר מעמוד צור קשר
תצרף את שם הכתובת שיצרת
וזה יופיע ככתובת מייל חדשה הכוונה רישומי שיחות וכו' רק מהמייל הזה כמו כתובת מייל חדשה לכל דבר?
אם הבנתי את כוונתך אז התשובה היא: לא (אבל אני לא בטוח שהבנתי...)
אתה כנראה הבנת שאאפשר את השליחה דרך הכתובת הזו ממשק ג'ימייל, ואתה שואל אם זה יופיע כחשבון ג'ימייל נפרד, ואם כך התשובה היא לא.
יש אופציה עתידה לקבל תיבת דואר נפרד לכל דבר, אבל זה לא יהיה דרך ממשק ג'ימייל אלא ממשק נפרד בדומיין מייל.קום
אחרת מה הענין שיוכלו לשלוח מהכתובת הזו דווקא?
שאלה זו צריך להפנות לאלה שביקשו את זה...
יש עכשיו אפשרות לכתובות מרובות פר משתמש בתשלום (4.9 שח לחודש במינוי שנתי, 6.9 במינוי חודשי)
אני מקווה לשווק בקרוב אפשרות לשליחת מייל מהכתובת (הבקשה הכי נפוצה)
אתה יכול לעשות בעצמך דרך פתיחת חשבון ג'ימייל חדש.
אי אפשר, ג'ימייל לא נותנים כתובות עם תווים בעברית
אני לא חושב שזה מצריך שליחת מייל מהכתובת החילופית, אלא להיפך, גוגל שולחים מייל אימות לכתובת ההיא. אבל לא בטוח שאני זוכר את כל התהליך
אתה צודק, אני הבנתי שאתה מדבר על משהו אחר (שאחרי בדיקה, גם לא עובד...). בכל מקרה בדקתי, וגוגל לא נותנים להוסיף מייל.קום ככתובת חילופית, הם נותנים רק כתובות ב-ascii
כמובן כל הקטע של פרוסמת לא הולך לקרות. אפשר להירגע
(חוץ מזה שיש בעיה טכנית בהוספת פרסומות למייל כי זה שובר את החתימה של DKIM וזה יגיע לספאם)
יהיו בעז"ה מסלולים בתשלום עם פיצ'רים שימושיים
תכניס עכשיו פרסומות באתר
תסלח לי אם לא אשמע לעצה זו... למרות שכוונתך לטובה
אפשר להוסיף את הכתובת בתור כתובת חילופית בחשבון
אכן, זה אמור לעבוד. אבל מכיון שאני לא מציע שליחה, רק קבלה, צריך להכניס את פרטי ה-SMTP של ג'ימייל כנ"ל
אשמח אם מישהו יאשר שזה באמת עובד להציג את תמונת המשתמש
אבל סתם, ניסיתי בג'ימייל שלי לחלק את הכתובת עם מקף והכתובת לא נמצאה. אז אולי זה רק אם כבר יש מקף או משהו.
דיברתי על מייל.קום. אין שום קשר בין מייל.קום לבין ג'ימייל
האם אתה מתכוון שאני יכול פעם לאיית את זה כא-ב-ג@מייל וכו' ופעם א.ב.ג וכו'?
כן
אם תשלח מייל ל"דג-מלוח@מייל.קום" ול-"דג.מלוח@מייל.קום" ול-"ד.ג_מ.ל-וח@מייל.קום"
כולם יגיעו לאותה כתובת
כללו של דבר: המערכת מתעלמת לגמרי מתווים .-_
אין סיבה לקבע משהו לכולם כברירת מחדל
כיום אם אתה מכניס רווח בתיבת הבדיקה בדף הנחיתה זה הופך את הרווח למקף, מה לדעתך אמור להיות ההתנהגות? (רווח בכל מקרה לא חוקי)
מה הפירוש של זה:
באמת שאלה מצויינת ") כנראה שאני צריך לשפר את הניסוח, הכוונה שהשם לא מייצג אותך ספציפית, זה מייצג כל דניאל בעולם (אין הכוונה שיש עוד אנשים עם אותו שם במערכת שלי, אין אפשרות לשניים לתפוס אותו שם)
כנראה שאני צריך לשפר את הניסוח, הכוונה שהשם לא מייצג אותך ספציפית, זה מייצג כל דניאל בעולם (אין הכוונה שיש עוד אנשים עם אותו שם במערכת שלי, אין אפשרות לשניים לתפוס אותו שם)
שאלה שניה האם יהיה ניתן להחליף מייל לאותו כתובת?
לא ברור לי הכוונה, אתה מתכוון לזה?
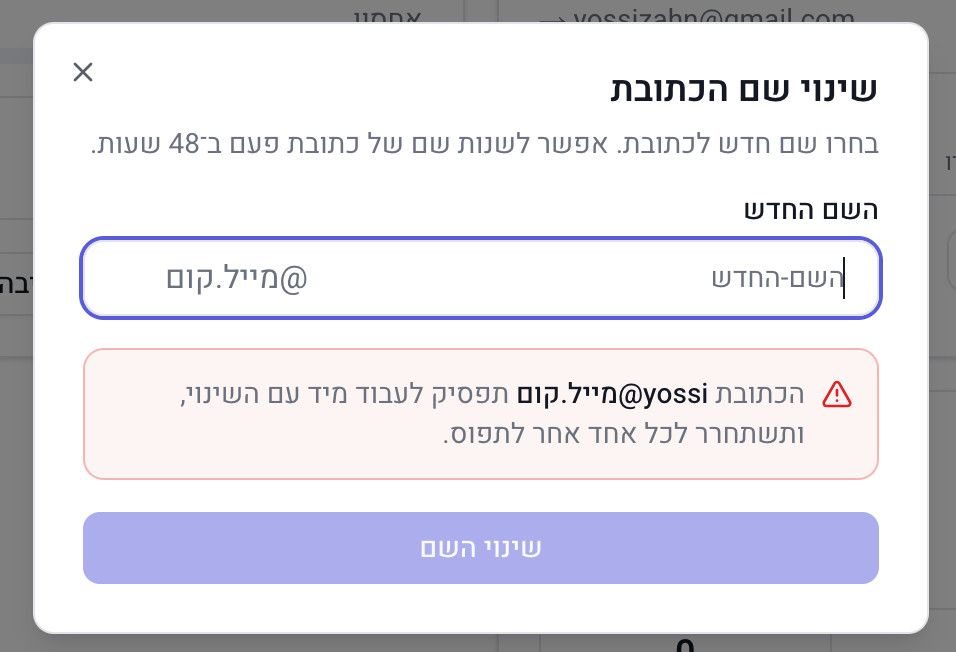
אם כן, תלחץ על "שינוי שם" בלוח הבקרה
@תלת-פאזי תודה
לגבי 1. ו2. אני מודע לבעיה ומחכה לרעיונות
לגבי ג. האם אתה חושב שכדאי לשנות את הברירת מחדל בתיבת בחירת שם שרווח יתהפך לנקודה במקום מקף? (כבר היום נקודה מקף וקו תחתי כולם נחשבים אותו כתובת, זה רק ענין של הצגה)
שוב, שיהיה ברור לגמרי:
גם אם אתה מתחבר עם חשבון גוגל, אין לי שום גישה לחשבון הג'ימייל שלך, רק מה שנשלח לכתובת העברית שלך (אתה@מייל.קום) עובר דרך השרת שלי, וגם את זה אני לא קורא וזה נמחק מיד וכו' וכו'
 { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}