מדריך | ביצוע OCR אופטימלי באמצעות PDF-X
-
שלום רב.
במדריך זה נלמד איך לבצע בצורה הכי טובה ואופטימלית OCR (זיהוי טקסט מתמונה) לקבצי PDF סרוקים (דהיינו שה-PDF לא מכיל כרגע טקסט ולא יוצא מתוכנה כמו אופיס שאז הוא טקסטואלי לחלוטין, אלא שזה מכיל רק תמונות של המסמכים הסרוקים).
ולבסוף להגיע לתוצאה של שמירת העיצוב והמבנה המדויק של ה-PDF המקורי, ורק יתווסף לנו שכבת טקסט בלתי נראית על גבי הדפים הסרוקים.הערה חשובה, לאחר כתיבת כל המדריך, ראיתי שזה יצא ממש ארוך בגלל פירוט כל הגדרה (למרות שהשתדלתי לא לפרט כל הגדרה מהי ומה כל האפשרויות הקיימות), ולכן אכתוב כאן מדריך קצר בלי להיכנס לכל ההגדרות, המדריך הקצר יכיל את השלבים האלו:
הורדת והתקנת התוכנה
פתיחת התוכנה וייבוא קובץ שבו יש כבר את כל ההגדרות החשובות
הסבר כיצד להפעיל את הכלי לאחר הייבוא.
אם תרצו להתעמק ולהבין מה השתנה בעת ייבוא ההגדרות, תראו את המדריך המפורט בהמשך.התקנה והגדרות ראשוניות
התקנה
נוריד ראשית כל את תוכנת PDF-X גירסת PRO מכאן.
הגדרת מנוע ושפת OCR
לאחר ההורדה וההתקנה נוכל לראות שהתווסף לנו תוכנה מבית PDF-X בשם PDF Tools

המכיל המון כלים לעבודה מול PDF.
אנחנו נפעיל את התוכנה ונלחץ על פרמטרים בשורת הפקודות למעלה, ואז על אפשרויות...: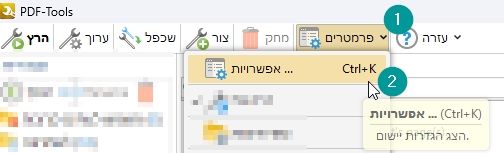
נבחר ב-OCR ואז נבחר במנוע משופר, ונלחץ על הוסף/עדכן שפות.
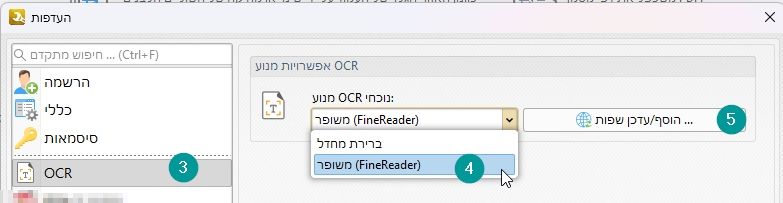
יפתח לנו חלון של שפות, נקליד עברית בחלון החיפוש, נלחץ על תיבת הסימון ליד השפה ונלחץ על המשך.
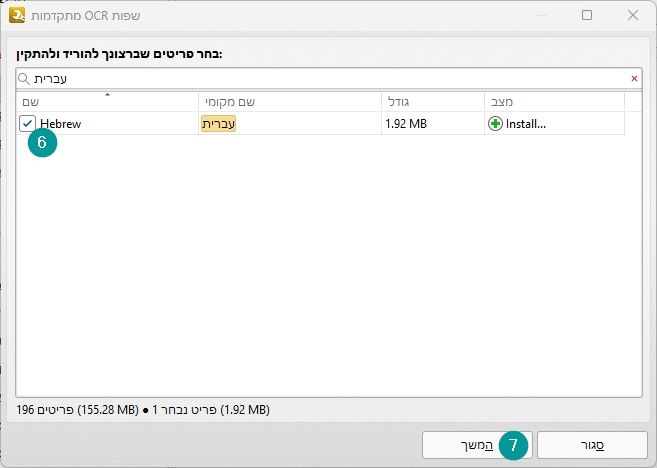
התוכנה תוריד את קבצי השפה בעברית ותתקין אותם, בסיום התהליך לחצו על אישור.
הכנת סביבת העבודה (התיקיות שאיתם נעבוד)
כעת נכין לנו סביבת עבודה במחשב שלנו ששם יהיו כל הקבצים שנרצה לסרוק (הקבצים המקוריים) וכן הקבצים הסרוקים (הקבצים שעובדו ועברו OCR וכעת מכילים שכבת טקסט).
נוריד את הקובץ הזה, ונריץ אותו, הוא יצור לנו 4 תיקיות בכונן C לפירוט על התיקיות הללו ויעודם ראו בספויילר.
שימו לב! שבתוך התיקיות הללו אתם הולכים להכניס את כל הקבצים שתרצו לסרוק ואילו שנסרקו כבר, ולכן אם אין לכם מקום בכונן C, תעבירו את התיקייה OCR שנוצרה בכונן C ותעבירו אותו לכונן אחר שם יש לכם מקום פנוי, ובמקביל תצטרכו לעדכן את התוכנה PDF Tools שהמיקום של קבצי היעד והמקור נמצאים במיקום אחר.
מה שהסקריפט עושה:
הוא יוצר תיקייה בכונןCבשםOCR, בתוכו הוא יוצר 2 תיקיות, לביצוע ובוצע.
בתיקיית לביצוע יהיו רק קבצי מקור שלא עברו עדיין OCR ע"י התוכנה, היכן נשמור את הקבצים המקוריים שכבר נסרקו? לצורך כך נוסיף בתיקייה זו עוד 2 תיקיות מקורי ונכשל כך שהתוכנה בסיום ה-OCR תעביר את הקבצים המקוריים שנסרקו כבר ואתם לא מעוניינים שיסרקו שוב, לתיקיות הללו וכמו שתראו בהמשך.
את הקבצים שנוסף בהם שכבת טקסט מוסתרת התוכנה תעביר לתיקיית בוצע, כך שתדעו תמיד שכל מה שנמצא בבוצע, עבר OCR וכל מה שנמצא בלביצוע ובתתי התיקיות שלו אילו קבצים שאין להם שכבת טקסט או OCR.במידה והתוכנה לא תזהה או לא תצליח לשמור את הקבצים בתיקיות אילו (וכדאי אכן לבדוק זאת על-ידי נסיון סריקת קובץ בודד, ובדיקה האם הוא אכן שומר את הקובץ הסרוק וקובץ המקור ומעביר את זה לתיקיות הנכונות, במידה וזה מצליח, תוכלו להשאיר את השמות בעברית), יש מצב שהגדרות המיקום והשפה במחשב לא נכונות ומפריעים לשמירת הקבצים הסרוקים.
לצורך כך ניתן לשנות את הגדרות המיקום כך שהם יהיו בעברית/ישראל וכו', או ליצור את התיקיות באנגלית ולעדכן בתוכנת PDF Tools על המיקומים החדשים, אם תעדיפו לעשות את התיקיות באנגלית, עשו זאת כך:
צרו תיקייה בכונןCבשםOCR, בתוכו צרו 2 תיקיות,todo(בתרגום חופשי לביצוע דהיינו הקבצים המקוריים אותם נרצה לסרוק) ו-done(בתרגום חופשי בוצע שם נאחסן את הקבצים המעובדים).
בתיקייתtodoיהיו רק קבצי מקור שלא עברו עדיין OCR ע"י התוכנה, היכן נשמור את הקבצים המקוריים שכבר נסרקו? לצורך כך נוסיף בתיקייה זו עוד 2 תיקיותoriginalו-failedכך שהתוכנה בסיום ה-OCR תעביר את הקבצים המקוריים שנסרקו כבר ואתם לא מעוניינים שיסרקו שוב, לתיקיות הללו וכמו שתראו בהמשך.
את הקבצים שנוסף בהם שכבת טקסט מוסתרת התוכנה תעביר לתיקייתdone, כך שתדעו תמיד שכל מה שנמצא ב-done, עבר OCR וכל מה שנמצא ב-todoאילו קבצים שאין להם שכבת טקסט או OCR.הגדרת סריקה
כעת נוכל להכין את כלי הסריקה ע"מ שהוא יבצע את הסריקה בצורה הטובה ביותר:
נוריד את הכלי הזה:
PDF-Tools Exchange.pdtexונייבא אותו כך:
נלחץ על פרמטרים בשורת הפקודות למעלה ואז על ייבוא כלי, ונבחר את הכליPDF-Tools Exchange.pdtexשזה עתה הורדנו, נלחץ על אישור, ובכך נייבא את כל ההגדרות הרצויות לסריקה הכי טובה.כעת ננווט לתפריט צד השמאלי לדפים, ואז נבחר בזיהוי דפים אופטי:
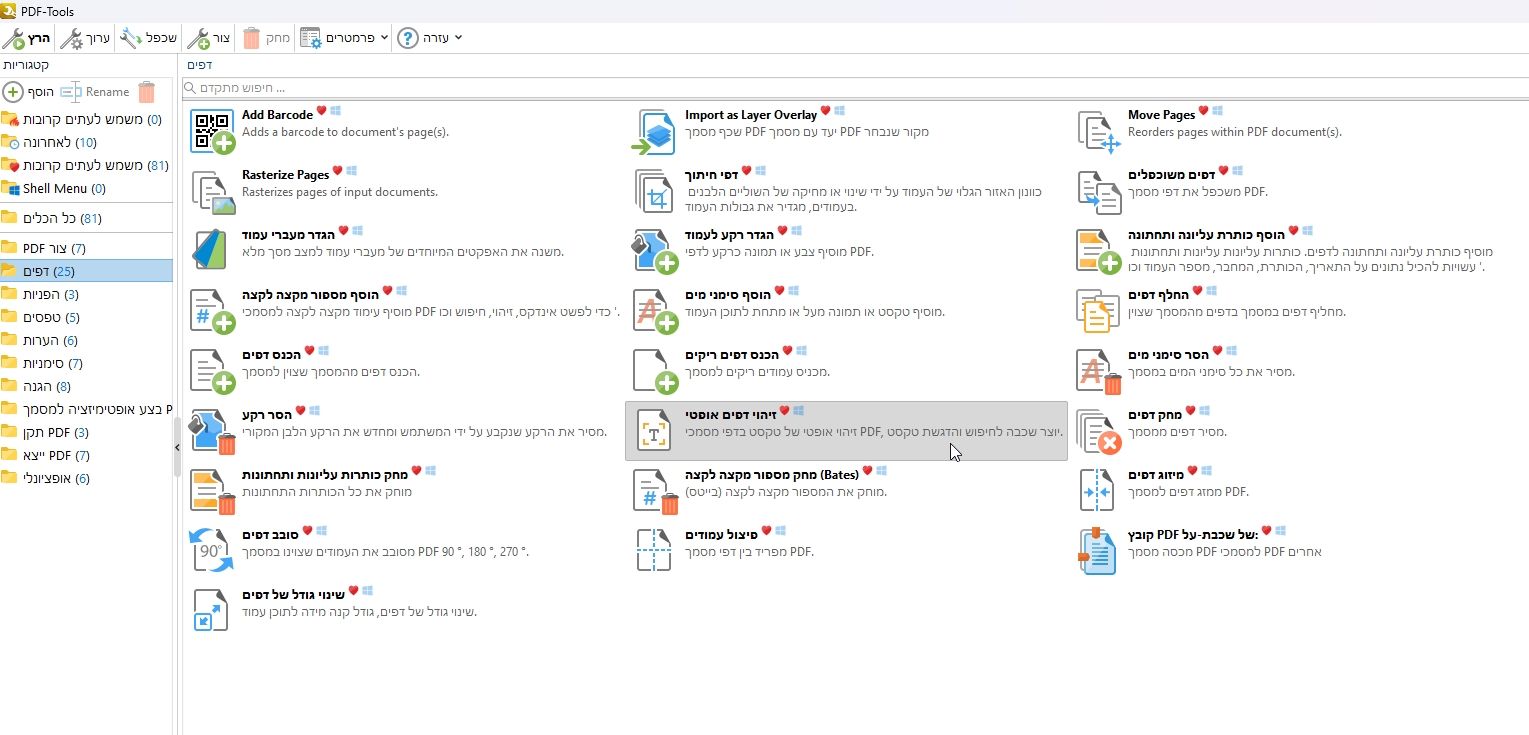
בלחיצת הקליק הימני של העכבר נוכל להגדיר שכלי זה ישמר במועדפים, כך שתוכלו בהמשך למצוא בקלות את הכלי.
בנוסף תוכלו לבחור בצור קיצור דרך לשולחן העבודה נבחר באופציה הראשונה של בקש קבצי קלט בכל פעם, ואז ייווצר לכם בשולחן עבודה קיצור לכלי זה כך שתוכלו בכל עת ללחוץ על הקיצור הזה, וללא פתיחת PDF Tools, הכלי של ה-OCR יידלק ויעבוד כמצופה.
כעת תכניסו את כל הקבצים שתרצו לסרוק בתיקייה לביצוע > 0-תור והתוכנה תסרוק את כל קבצי ה-PDF משם, בסוף התהליך, כל הקבצים שנסרקו ועובדו וקיבלו שכבת טקסט ייווצרו בתיקיית בוצע, והקבצים המקוריים שנסרקו יהיו בתיקיית לביצוע > מקורי.
אם תרצו לשמור על סדר, תוכלו לאחר כל מקבץ של קבצים לסריקה לאחר הביצוע, להעביר אותם לתתי תיקיות בשמות דומים, דהיינו שבתיקיית בוצע, תיצרו תת תיקייה בשם 1 ובתיקייה לביצוע > מקורי גם תיצרו תת תיקייה בשם 1, ולאחר כל סיום סריקה, תעבירו את כל הקבצים שנסרקו עכשיו לתיקיות החדשים, ובשלב הבא בסריקה הבאה, תעבירו את הקבצים החדשים לתת תיקייה בשם 2, וכן הלאה, כך תוכלו להשוות בין שני התיקיות של המקור והיעד, האם כל שמות הקבצים דומים אחד לשני, (גודל הקבצים לא אמורים להיות דומים, קבצי היעד אמורים להיות גדולים יותר).
מדריך למתקדמים שרוצים לדעת אילו הגדרות שונו בקובץ הייבוא PDF-Tools Exchange.pdtex
כעת נוכל לראות בתפריט בצד ימין שורה של הגדרות, נעבור עליהם אחד אחד כדי למקסם את יכולות הכלי, וכדי לבצע שיטות עבודה יעילות ומסודרות, ומבלי לשנות את צורת ה-PDF המקורי.
תחת הכותרת מידע, יש מידע על הכלי זיהוי דפים אופטי, כהערת אגב תוכלו לראות סמלילים ליד המילים הללו, בלחיצה על סמליל העזרה (סימן השאלה), תוכלו לעבור לדף האינטרנט של הכלי הזה ולראות את כל ההגדרות של הכלי, בכל עת תוכלו להיכנס שם במידה שאתם מסתקרנים מה המשמעות של תכונה כלשהיא, כמו כן בכל חלונית של קבוצת הגדרות גם יהיה סמליל עזרה שתנווט אתכם לדף שמדבר על התכונות בחלונית זה, בשלב זה נדלג על הכניסה לשם ונתקדם להגדרות.בחלונית צד ימין כנסו לכל הפרמטרים הנמצא מעל החלונית של בחר קבצי מקור:
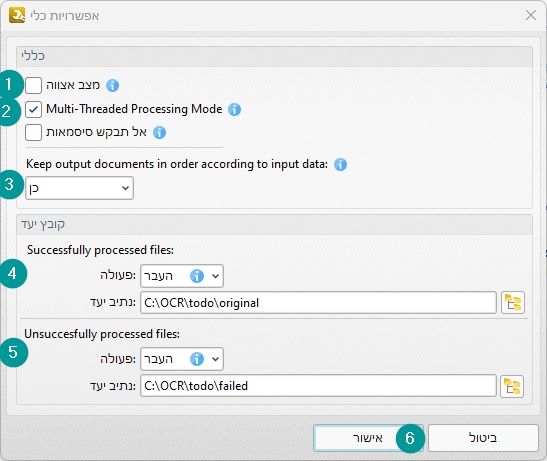
- השביתו מצב אצווה.
- הפעילו מצב Multi-Threaded Processing Mode, אם אתם לא חושבים לעבוד על המחשב במקביל לעבודת ה-OCR, במידה ואתם כן תרצו לעבוד ולהשתמש במחשב במקביל, תשביתו תכונה זו, אבל שימו לב שהתהליך יקח לכם הרבה יותר זמן, מכיון שהוא לא ישתמש בכל המשאבים של המחשב לצורך ביצוע ה-OCR.
- בהגדרה של Keep output documents in order according to input data: תבחרו בלא, במידה ויש לכם זיכרון RAM מוגבל, אם יש לכם זיכרון RAM סביר (16 ג'יגה), תבחרו בכן.
תחת קובץ יעד:
4. במקטע Successfully processed files: תבחרו בפעולה: העבר, ובנתיב יעד את התיקייה שיצרנו למעלה: C:\OCR\todo\original
5. במקטע Unsuccessfully processed files: תבחרו בפעולה: העבר, ובנתיב יעד: C:\OCR\todo\failedבסוף כל הפעולות, מה שנקבל זה התוצאה הבאה, לחצו על אישור:
כעת בבחר קובץ מקור
בחר מ:
לחצו על הוסף מקום > תיקייה מקומית ובחרו ב-C:\OCR\todo שם בעצם יהיו הקבצים שמחכים לסריקה.
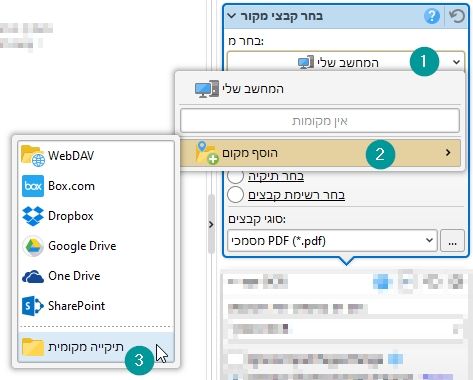
אל תפעילו חיפוש בתיקיות משנה.
סוגי קבצים ישאר על PDF.
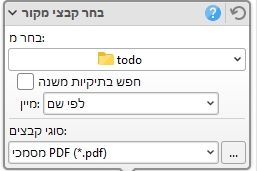
בחלונית דפי OCR אמור להיות ההגדרות ככה:
שימו לב להסיר את הסימון של הצג שיח הגדרות במהלך העבודה.

לחצו על המיליה בנוסף...
וכאן שימו לב טוב להגדרות הבאות:- הסירו את הסימון מ-3 השורות:
התעלם מ...
תחת המקטע אפשרויות פלט: - סוג: בחרו בתמונה ניתנת לחיפוש - חובה, זה גורם שה-PDF הסופי יהיה עם שכבת טקסט.
- הסירו את הסימון מ-תקן תפירת תוכן... - חובה, אם לא תעשו זאת, התוכנה תחליט בשבילכם האם לשנות את עיצוב הדפי המקור, וזה יכול להוביל לתוצאה ממש לא טובה.
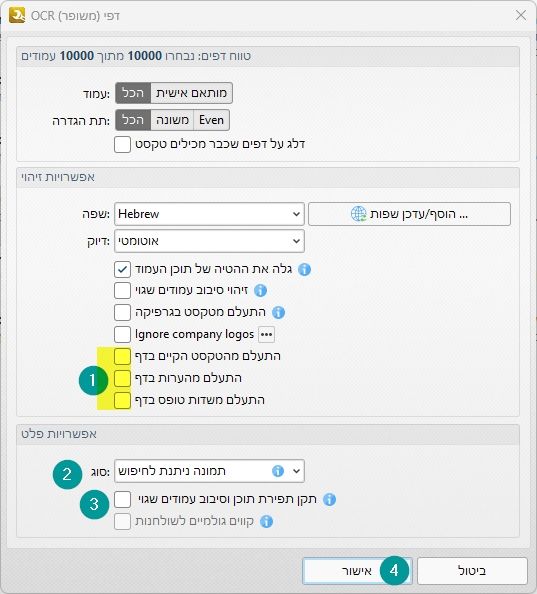
1.בחלונית שמור מסמכים תבחרו את התיקייה C:\OCR\done
2.בשם קובץ, מחקו את סיומת הקובץ שהם מוסיפים, והשאירו רק%[FileName]
3. אם הקובץ כבר קיים בחרו באופציה האחרונה - קובץ חדש עם שם ייחודי אחר.החלונית האחרונה של הצג קבצים, השביתו אותו, ע"י לחיצה על התיבת הסימון בכותרת החלונית.
בסיום כל ההגדרות, תפריט צד ימין אמור להיראות ככה:
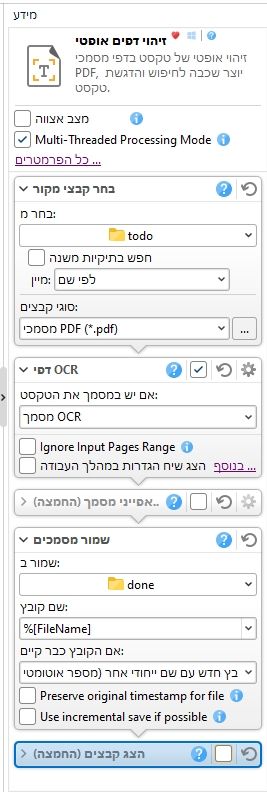
כעת תוכלו להעביר לתיקייה C:\OCR\todo את כל הקבצים שתרצו לסרוק, בסיום הסריקה, כל הקבצים החדשים שקיבלו שכבת טקסט יהיו בתיקייה C:\OCR\done, וכל הקבצים המקוריים יהיו בתיקיית C:\OCR\todo\original, במידה ויהיו קבצים שנכשלו באמצע העבודה הם יועברו ל-C:\OCR\todo\failed.
כך שבסיום התהליך לא אמורים להיות כלל קבצים בתיקיית C:\OCR\todo, ואם תרצו לסרוק קבצים נוספים, העבירו אותם לתיקייה זו.המלצה שלי, לאחר כל סיום סריקה, תעבירו את תוכן הקבצים החדשים לתיקייה חדשה, כך שתוכלו לעקוב לאחר כל סריקה, האם כל הקבצים אכן טופלו.
יש בעיה אחת עם PDF TOOLS, שהוא לא מעביר ל-C:\OCR\todo\original את הקבצים במהלך העבודה, אלא בסיום כל הקבצים, כך שאם יש הפסקת חשמל באמצע וכדו', תוכלו לדעת על פי הקבצים שכבר נמצאים ב-C:\OCR\done, אילו קבצים כבר עובדו, ולפי זה להעביר את הקבצים המקוריים שלהם לתיקייה אחרת כך שהם לא יעברו סריקה מיותרת פעם נוספת.למתקדמים
בפרמטרים בשורת הפעולות למעלה יש אפשרות של צופי תיקיות כך שתוכלו לתזמן פעולה כל X זמן שתבדוק האם יש קבצים בתיקיית המקור ותסרוק אותם אוטומטית ללא צורך בהתערבות מצידכם (כמו תיקייה חמה hot folder של abbyy).
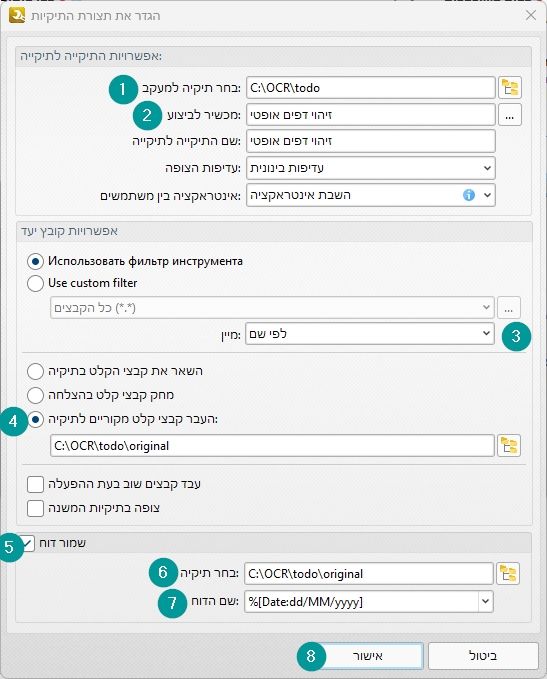
תלחצו על צור
ואז הגדירו:- בחר תיקייה למעקב: C:\OCR\todo
- מכשיר לביצוע: זיהוי דפים אופטי
- מיון לפי שם
- העברת קבצים שבוצעו ל-C:\OCR\todo\original
- שמירת דוח.
בסוף זה יראה ככה:
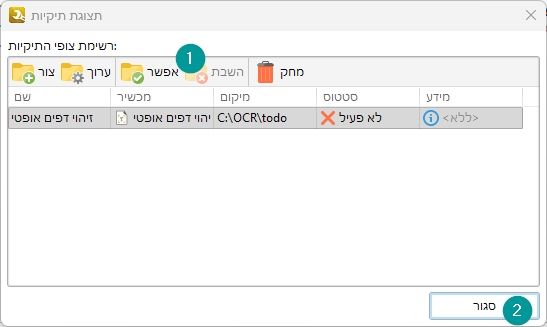
ואז תוכלו ללחוץ על הפריט החדש ברשימה שיצרנו זה עתה ולהפעיל אותו.
-
 פ פלמנמוני התייחס לנושא זה ב
פ פלמנמוני התייחס לנושא זה ב
-
 ח חברים פיצל נושא זה ב
ח חברים פיצל נושא זה ב
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}