היו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!
-
שאלתי את GPT והוא כנראה נעלב
הוא בקש שאעלה לו את הקובץ והוא יפענח
נראה לי שהוא לקח את זה קשה
@אמיר

בכל אופן התמחור של גוגל לחילוץ טקסט מתמונות:

צריך לבדוק כמה כאלו חבילות צריך בשביל פרויקט כזה.
למרות שהרעיון של הפרויקט החינמי בגיטהאב הרבה יותר טוב.
שוב, כל זה רק אם צריך רק קבצי טקסט.
אם לא כל הדיון מיותר.
חייבים מה ש @אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:1] בתוכנת ABBYY מכאן או באחד מהכלים האחרים שלהם [SDK /סרבר/עוד]
2] בתוכנת PDF-XChange מכאן {בכלי בשם טולס} [יש להגדיר שיהיה OCR משופר].
3] בתוכנה של רחמים זה מיועד רק למי שקנה את התוכנה מרחמים [ורק אם הרישיון שהוא נותן הוא ללא הגבלה]. -
@אמיר
בכל אופן התמחור של גוגל לחילוץ טקסט מתמונות:
צריך לבדוק כמה כאלו חבילות צריך בשביל פרויקט כזה.
למרות שהרעיון של הפרויקט החינמי בגיטהאב הרבה יותר טוב.
שוב, כל זה רק אם צריך רק קבצי טקסט.
אם לא כל הדיון מיותר.
חייבים מה ש @אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:1] בתוכנת ABBYY מכאן או באחד מהכלים האחרים שלהם [SDK /סרבר/עוד]
2] בתוכנת PDF-XChange מכאן {בכלי בשם טולס} [יש להגדיר שיהיה OCR משופר].
3] בתוכנה של רחמים זה מיועד רק למי שקנה את התוכנה מרחמים [ורק אם הרישיון שהוא נותן הוא ללא הגבלה]. -
קודם כל אכן צריך דווקא שיהיה שכבת טקסט מוסתרת מאחורי הצילום,
דבר שני מדובר על 11.7 מיליון עמודים!!לכן זה לא נראה ריאלי לע"ע.
@אלף-שין
הקובץ חייב להיות צילום עם שכבת טקסט?
זה מה ששאלתי.@יאנג-בוי כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
צריך לקבל את הספרים בצורתם המקורית עם אפשרות חיפוש?
או רק קובץ טקסט עם הטקסט שלהם?
אם רק קובץ טקסט, זו לדעתי תהיה האפשרות היעילה ביותר.ואם כן, כל הרעיון של גוגל לא רלוונטי בכלל.
@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
דבר שני מדובר על 11.7 מיליון עמודים!!
אין הבדל בין ABBYY לגוגל בהקשר הזה.
אבל שוב, לא רלוונטי. -
קודם כל אכן צריך דווקא שיהיה שכבת טקסט מוסתרת מאחורי הצילום,
דבר שני מדובר על 11.7 מיליון עמודים!!לכן זה לא נראה ריאלי לע"ע.
-
@אלף-שין
הקובץ חייב להיות צילום עם שכבת טקסט?
זה מה ששאלתי.@יאנג-בוי כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
צריך לקבל את הספרים בצורתם המקורית עם אפשרות חיפוש?
או רק קובץ טקסט עם הטקסט שלהם?
אם רק קובץ טקסט, זו לדעתי תהיה האפשרות היעילה ביותר.ואם כן, כל הרעיון של גוגל לא רלוונטי בכלל.
@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
דבר שני מדובר על 11.7 מיליון עמודים!!
אין הבדל בין ABBYY לגוגל בהקשר הזה.
אבל שוב, לא רלוונטי.@יאנג-בוי כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
הקובץ חייב להיות צילום עם שכבת טקסט?
זה מה ששאלתי.כן.
חייב.@יאנג-בוי כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
ואם כן, כל הרעיון של גוגל לא רלוונטי בכלל.
נכון.
-
@אמיר כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
איך נקרא תהליך ההטמעה של הטקסט לתוך תמונה שב- PDF ?
שאלה טובה אני לא יודע כרגע,
איך שלא יהיה צריך לדעת את הקורדאניטות
ולכן נראה לי האופציות שהצעתי הם הטובות ביותר. -
@aiib כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
מה בוחרים כאן?
את הראשון.
חשוב!! אח"כ תגדיר עברית בלבד.
ואל תתייחס לפירוט השגיאות שהבאת בהודעה הבאה.
רק מה שנפק"מ זה רק מה שכתוב לך להגדיר את הרוזולוצי' ל 600 -
שלום רב,
כהמשך לרעיון שהעלו בשרשור שם
אני פותח פה את הפרוייקט המיוחד בצורה מסודרת וברורה.[פרוייקט שיתופי של OCR ל60,000 קבצים המכילים 11.7 מיליון עמודים!]
תחילה יש להתקין תוכנה של OCR
כל אחד יוכל לבחור באחד מבין 3 אפשרויות איך לבצע את הזיהוי אצלו,1] בתוכנת ABBYY מכאן או באחד מהכלים האחרים שלהם [SDK /סרבר/עוד]
2] בתוכנת PDF-XChange מכאן {בכלי בשם טולס} [יש להגדיר שיהיה OCR משופר].
3] בתוכנה של רחמים זה מיועד רק למי שקנה את התוכנה מרחמים [ורק אם הרישיון שהוא נותן הוא ללא הגבלה].
בשלושתם יהיה תוצאה טובה שמספיקה לעניינינו.בכל האפשרויות יש צורך גדול להגדיר ששפת הזיהוי היא עברית בלבד!
וזה כדי שלא יהיה פיענוחים שגויים בעשרות שפות אחרות, וגם זה יקצר את העבודה מאד!לאחר מכן כל אחד בוחר את כמות הקבצים שהוא מעונין להמיר,
ומעדכן כאן, או במייל 0556781863A@GMAIL.COM או באישי ואנו נשלח לו למייל קישור לדרייב המכיל תיקייה עם כמות הקבצים שהוא ציין,
בנוסף נשלח לו קישור לתיקייה נוספת בדרייב לשם הוא יעלה את הקבצים לאחר העיבוד,יצוין כי אם מתקינים דרייב לשולחן עבודה,
אפשר לבצע את כל ההמרה כולל ההעלאה לדרייב בלחיצת כפתור אחת!
פשוט כל לילה 'לפני השינה' לוחצים על כפתור אחד וכל הלילה המחשב מעבד עוד ועוד קבצים ומעלה אותם בעצמו לתיקייה הרצויה בדרייב!
מי שרוצה נוכל להדריכו כאן.אם מישהו מוכן לעבוד על כמות גדולה אבל לא מתאים לו להוריד מהדרייב,
ישלח לנו את מיקום מגוריו, ונראה אם שייך להעביר לו את הקבצים ידנית.בהצלחה לכולנו!!
ושיהיה בעז"ה ס"ד גדולה לטובת כולם!!
@אלישי @aiib @האדם-החושב @י-פל @יעקב-מ-פינס @יהודה-12 @אמיר @דאנציג @משה-מזרחי @A0533057932 @NH-LOCAL
לכל תגובה/רעיון לשדרוג נא להגיב רק כאן,
זה נושא מסודר וחדש!כל אחד יכול לעזור ולהוסיף!!
בלי שום התחייבות!
בסוף הכל מצטרף לחשבון גדול!!@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
1] בתוכנת ABBYY מכאן או באחד מהכלים האחרים שלהם [SDK /סרבר/עוד]
ניתן פשוט להדגיש את כל הקבצים בתיקייה שמורידים > מקש ימני > אפשרויות נוספות > המר למסמך PDF הניתן לחיפוש
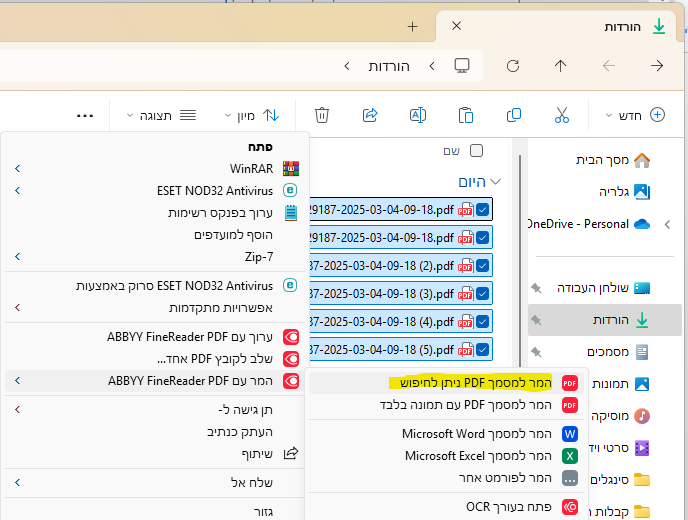
ואז בחלון שנפתח לבחור בשפות OCR עברית והמר אל PDF ולבחור תיקייה שלשם ישמור את המסמכים החדשים
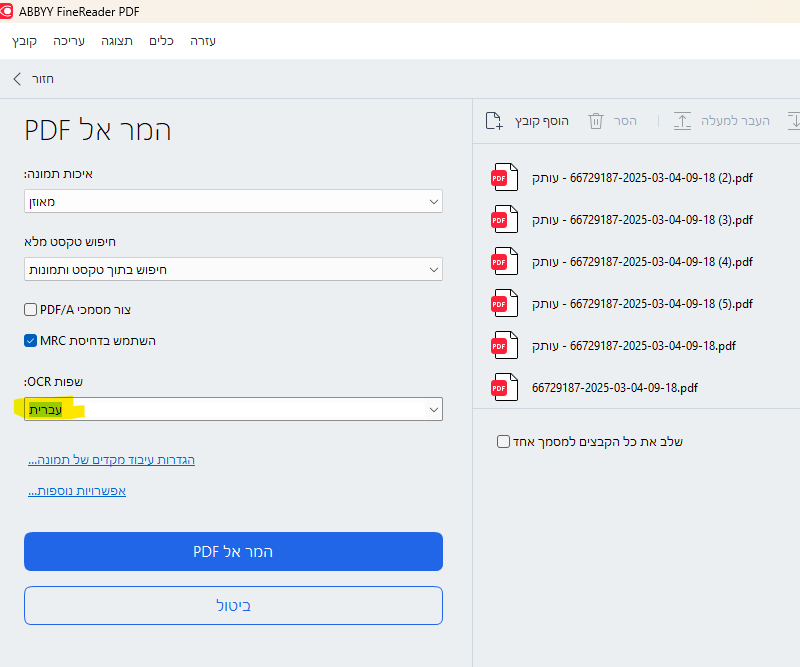
-
@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
1] בתוכנת ABBYY מכאן או באחד מהכלים האחרים שלהם [SDK /סרבר/עוד]
ניתן פשוט להדגיש את כל הקבצים בתיקייה שמורידים > מקש ימני > אפשרויות נוספות > המר למסמך PDF הניתן לחיפוש
ואז בחלון שנפתח לבחור בשפות OCR עברית והמר אל PDF ולבחור תיקייה שלשם ישמור את המסמכים החדשים
@מיכאלוש יפה מאוד!
אבל למה לא לבחור ב'איכות תמונה' ב'איכות הטובה ביתר'? -
@aiib כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
מה בוחרים כאן?
את הראשון.
חשוב!! אח"כ תגדיר עברית בלבד.
ואל תתייחס לפירוט השגיאות שהבאת בהודעה הבאה.
רק מה שנפק"מ זה רק מה שכתוב לך להגדיר את הרוזולוצי' ל 600@יום-חדש-מתחיל כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
ואל תתייחס לפירוט השגיאות שהבאת בהודעה הבאה.
למה לא להתייחס? זה לא אומר שזה לא פוענח?
רק מה שנפק"מ זה רק מה שכתוב לך להגדיר את הרוזולוצי' ל 600
איך עושים את זה?
בנוסף, בחרתי את כל הקבצים והוא שמר לי אותם כקובץ אחד, איך אפשר להגדיר שכל קובץ יישמר בנפרד?
-
@יום-חדש-מתחיל כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
ואל תתייחס לפירוט השגיאות שהבאת בהודעה הבאה.
למה לא להתייחס? זה לא אומר שזה לא פוענח?
רק מה שנפק"מ זה רק מה שכתוב לך להגדיר את הרוזולוצי' ל 600
איך עושים את זה?
בנוסף, בחרתי את כל הקבצים והוא שמר לי אותם כקובץ אחד, איך אפשר להגדיר שכל קובץ יישמר בנפרד?
@aiib כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
למה לא להתייחס?
כי בכל עמוד מספר סרוק שתנסה לפענח הוא יכתוב לך כאלה שגיאות. בדוק ומנוסה.
איך עושים את זה?
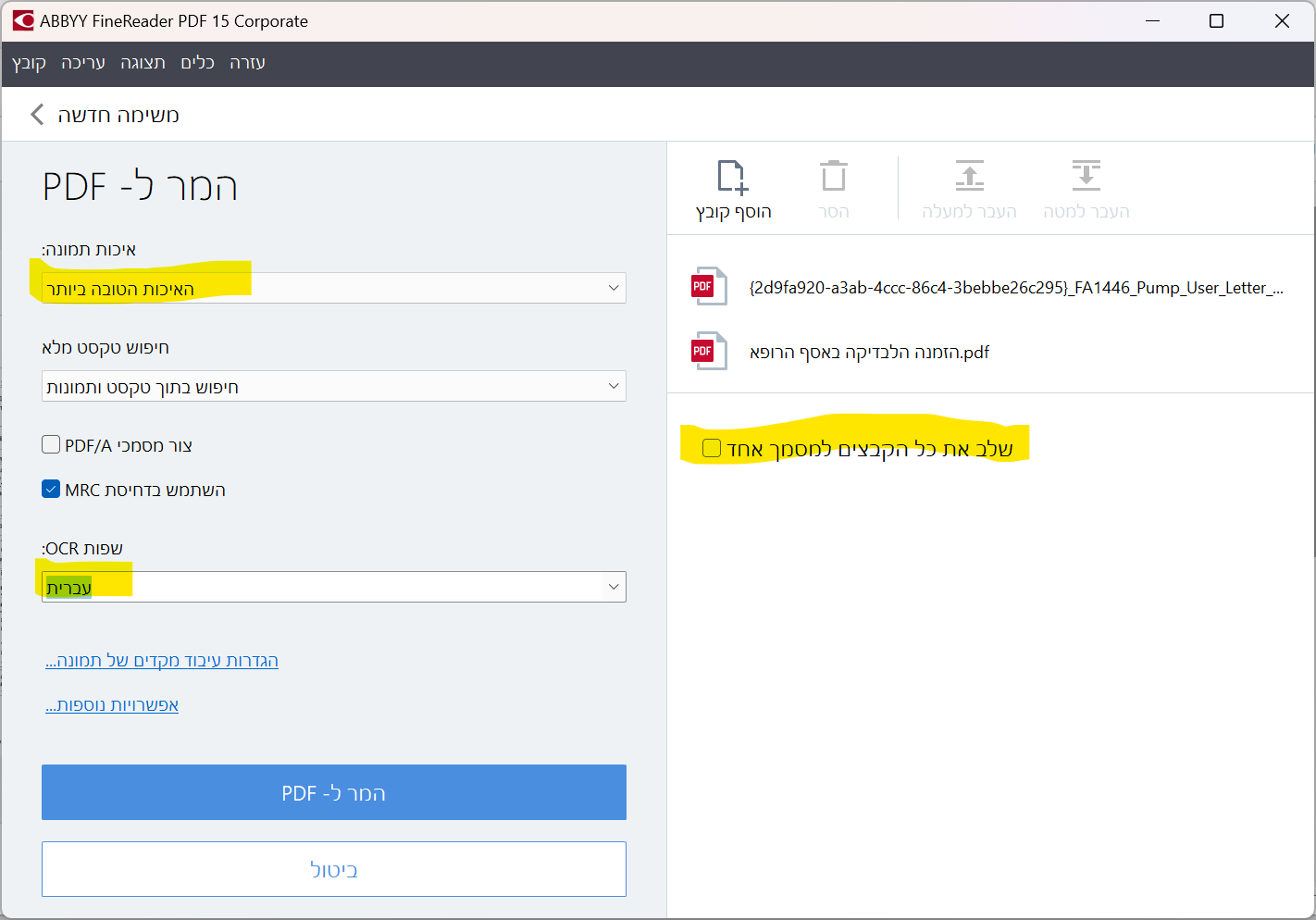
האמת שלא מצאתי איך עושים את זה, רק בפתיחת ABBYY FineReader 15 OCR Editor ושם אחרי לחיצה על אפשרויות ניתן להגדיר
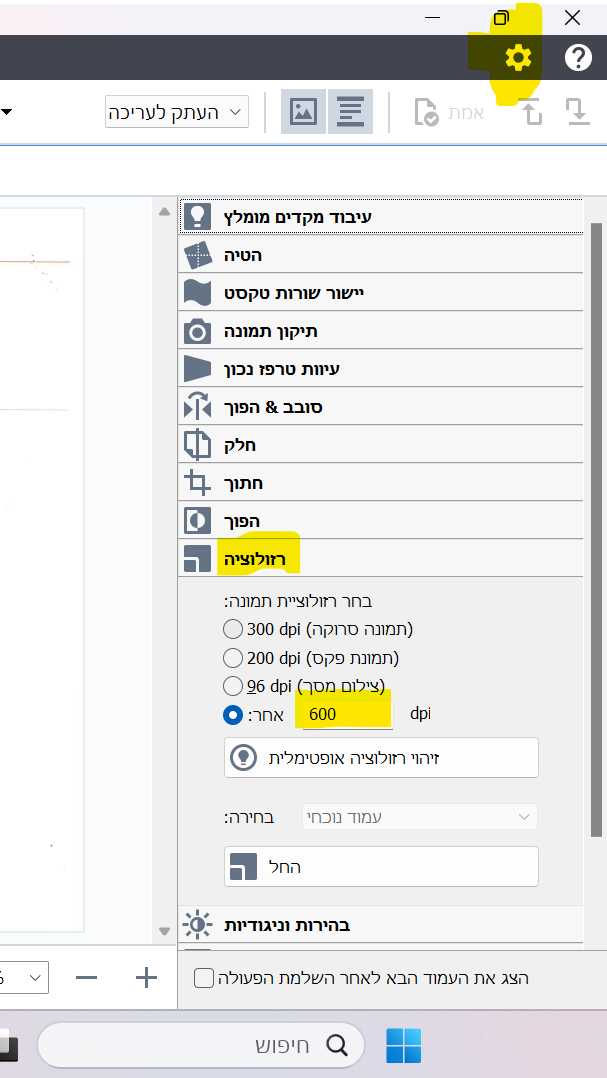
איך אפשר להגדיר שכל קובץ יישמר בנפרד?
פשוט מאוד. לא ללחוץ על 'שלב את כל הקבצים למסמך אחד'.
-
@aiib כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
למה לא להתייחס?
כי בכל עמוד מספר סרוק שתנסה לפענח הוא יכתוב לך כאלה שגיאות. בדוק ומנוסה.
איך עושים את זה?
האמת שלא מצאתי איך עושים את זה, רק בפתיחת ABBYY FineReader 15 OCR Editor ושם אחרי לחיצה על אפשרויות ניתן להגדיר
איך אפשר להגדיר שכל קובץ יישמר בנפרד?
פשוט מאוד. לא ללחוץ על 'שלב את כל הקבצים למסמך אחד'.
@יום-חדש-מתחיל כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
פשוט מאוד. לא ללחוץ על 'שלב את כל הקבצים למסמך אחד'.
אין לי את הגירסה הזו..
בנוסף אשמח לדעת איך אני מגדיר מראש את המיקום של השמירה?
אגב, עשיתי בשעתיים וחצי יותר מ5000 דפים, בקצב כזה אפשר לעשות כל לילה כשהולכים לישון 10,000 דפים שזה אומר שעוד 35 אנשים כמוני עושים זאת במשך חודש גומרים סיפור.
אם 70 אנשים תוך שבועיים... -
@יום-חדש-מתחיל כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
פשוט מאוד. לא ללחוץ על 'שלב את כל הקבצים למסמך אחד'.
אין לי את הגירסה הזו..
בנוסף אשמח לדעת איך אני מגדיר מראש את המיקום של השמירה?
אגב, עשיתי בשעתיים וחצי יותר מ5000 דפים, בקצב כזה אפשר לעשות כל לילה כשהולכים לישון 10,000 דפים שזה אומר שעוד 35 אנשים כמוני עושים זאת במשך חודש גומרים סיפור.
אם 70 אנשים תוך שבועיים...@aiib יפה מאוד!! אין עליך! זכות הרבים שילמדו בספרים תיזקף לזכותך.
אז יוצא שבכל 3 דקות אתה עושה 100 עמודים.ובקשר לשאלתך, הנה עוד סיבה לעדכן לגירסא ש @אלף-שין הביא למעלה. [או לגירסא 15 ש @י-פל תרגם לעברית]. גם עברית, גם עוד פונקציות. גם אפשרות לבחור מיקום לשמירה. [אצלי זה אוטומטי אחרי לחיצה על הכפתור הכחול "המר ל- PDF"]
ד.א. אתה ישן רק 5 שעות ביום? ככה יוצא לפי החשבון שכתבת ל 10000 דפים ללילה. -
לא לגמרי הבנתי, התוכנה מורידה לבד מהדרייב ומעלה לבד?
-
לא לגמרי הבנתי, התוכנה מורידה לבד מהדרייב ומעלה לבד?
@צבי-דורש-ציון לא, אתה מגדיר לה לשמור את הקבצים בתיקייה שמסתנכרת אוטומטית עם דרייב
ואז כשקובץ נשמר הוא עולה לדרייב בלי התערבות נוספת מצידך -
@צבי-דורש-ציון לא, אתה מגדיר לה לשמור את הקבצים בתיקייה שמסתנכרת אוטומטית עם דרייב
ואז כשקובץ נשמר הוא עולה לדרייב בלי התערבות נוספת מצידך@קינג-קומפיוטר כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
@צבי-דורש-ציון לא, אתה מגדיר לה לשמור את הקבצים בתיקייה שמסתנכרת אוטומטית עם דרייב
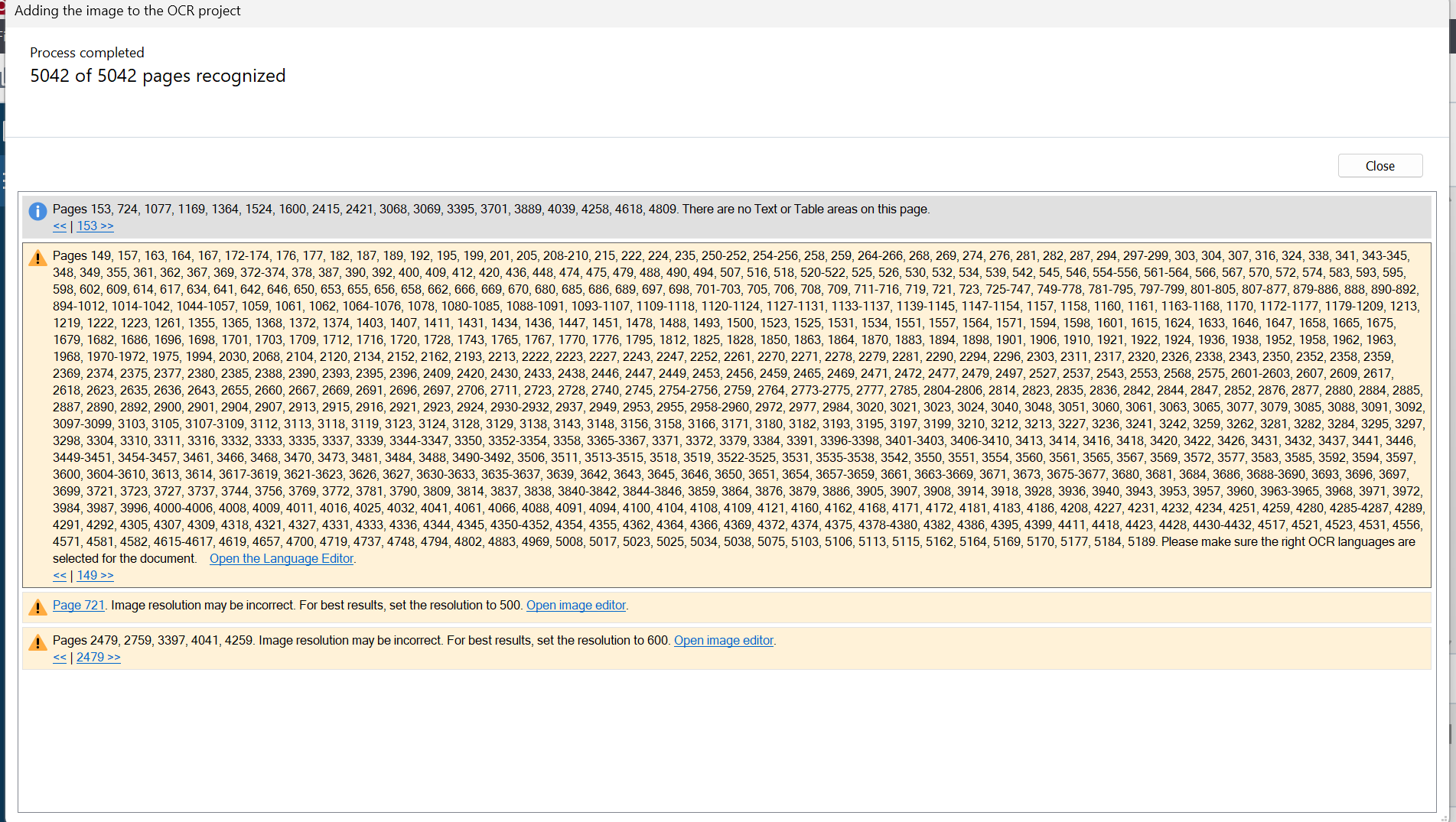
ואז כשקובץ נשמר הוא עולה לדרייב בלי התערבות נוספת מצידךאיפה מגדירים את זה?
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}