בירור | ניקוי קובץ טקסט מתווים מיותרים
-
@menajemmendel כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@מישהו12
תיקנתי תנסה עכשיועכשיו זה שומר את כל הגרשיים
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@menajemmendel כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@מישהו12
תיקנתי תנסה עכשיועכשיו זה שומר את כל הגרשיים
זה עדיין עובד, יש לך עניין דווקא בדרך החלפה. או בתוצאה?
https://mitmachim.top/post/757976 -
@menajemmendel תודה, זה עבד.
רק עם בעיה קטנה אחת.
איפה שהיה גרשיים בטקסט (בדרך כלל במילה הרמב"ם). זה מחק אותם ואת כל מה שאחריהם.
וזה מה שאמרתי, שגירשיים בתוך הטקסט אני רוצה לשמור.
הדרך להבדיל היא, שאחרי גרשיים מהסוג שאני רוצה לשמור תמיד יופיע עוד תו, ואחרי אלו שאני רוצה למחוק אותם ואת מה שאחריהם, יופיע אנטר או רווח ואחריו אנטר.@מישהו12 אני עדיין לא מבין את הרעיון המוזר לפרסר JSON באמצעות חיפוש והחלפה לסוגיו כאילו שזה טקסט רגיל
-
@מישהו12 אני עדיין לא מבין את הרעיון המוזר לפרסר JSON באמצעות חיפוש והחלפה לסוגיו כאילו שזה טקסט רגיל
-
@menajemmendel כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@מישהו12
תיקנתי תנסה עכשיועכשיו זה שומר את כל הגרשיים
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@menajemmendel כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@מישהו12
תיקנתי תנסה עכשיועכשיו זה שומר את כל הגרשיים
אז עכשיו אתה יכול לעשות החלפה של כל הרגשיים שיש לפניהם או אחריהם רווח -ברווח לבד, ואז כל הרגשיים שבתוך מילה ישארו
טכנאי מחשבים
-
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@menajemmendel כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@מישהו12
תיקנתי תנסה עכשיועכשיו זה שומר את כל הגרשיים
אז עכשיו אתה יכול לעשות החלפה של כל הרגשיים שיש לפניהם או אחריהם רווח -ברווח לבד, ואז כל הרגשיים שבתוך מילה ישארו
@ישראל-142 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
כל הרגשיים שיש לפניהם או אחריהם רווח -ברווח לבד
אם הייתי יודע איך לעשות החלפה של " שיש אחריהם אנטר, הנושא מתחילתו לא היה נפתח... זו בדיוק השאלה.
הבלוג שלי
https://aiv-dev.com/he-IL/ -
@ישראל-142 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
כל הרגשיים שיש לפניהם או אחריהם רווח -ברווח לבד
אם הייתי יודע איך לעשות החלפה של " שיש אחריהם אנטר, הנושא מתחילתו לא היה נפתח... זו בדיוק השאלה.
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
אם הייתי יודע איך לעשות החלפה של " שיש אחריהם אנטר, הנושא מתחילתו לא היה נפתח... זו בדיוק השאלה.
אתה יודע להשתמש בחפש והחלף?
CTRL +H
ותכתוב שם "^13
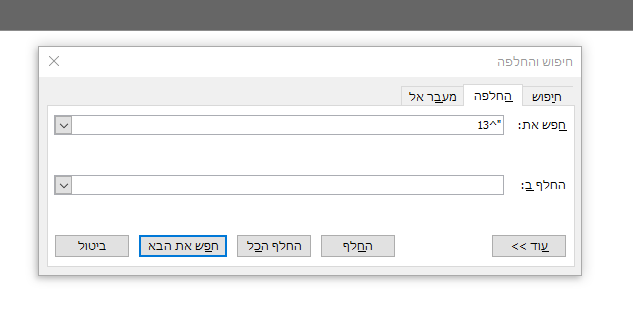
הסבר: ^13 הוא אנטר
-
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
אם הייתי יודע איך לעשות החלפה של " שיש אחריהם אנטר, הנושא מתחילתו לא היה נפתח... זו בדיוק השאלה.
אתה יודע להשתמש בחפש והחלף?
CTRL +H
ותכתוב שם "^13
הסבר: ^13 הוא אנטר
הבלוג שלי
https://aiv-dev.com/he-IL/ -
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
יש לי קובץ טקסט שנראה ככה

אני מעוניין שישארו רק המשפטים בעברית, בלי כל הסימנים, הכיתוב באנגלית וכדו'.
חפש והחלף לא עוזר לי כי אפשר לחפש\למחוק שם ירידות שורה (אנטרים).תודה!
למה לא להריץ איזה סקריפט פייתון קצר,
סוג של כזה דבראפשרי להריץ אונליין גם למשל באתר הבא https://www.programiz.com/python-programming/online-compiler/
data = [ { "timestamp":[3249, 2455], "text" : "המחשבה בדבר" }, { "timestamp":[3269, 1455], "text" : "המחשבה האמיתית" }, { "timestamp":[234, 24423342555], "text" : "היא מחתימה את הכל " }, { "timestamp":[3249, 2455], "text" : "עבור מישהו12 " } ]ואז
alltext = "" for i in data: alltext += i["text"] + " " print(alltext)בשביל לחבר בין משפט למשפט ברווח
או
alltext = "" for i in data: alltext += i["text"] + "\n" print(alltext)כדי לחבר בינהם בשורה חדשה
כמובן שלא חייבים להדפיס את התוצאה, אפשרי גם לכתוב אתה לקובץ (זה לא ניתן באתר הנ״ל לכאורה)
open("text.txt", "w").write(alltext) -
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@MGM-IVR אפשר את זה כסקריפט אחד שירוץ על קובץ בשם file.txt?
import json file = open('file.txt', 'r').read() data = json.loads(file) alltext = "" for i in data: alltext += i["text"] + "\n" open("output.txt", "w").write(alltext)הקובץ צריך להיות במבנה json כמובן
למשל[ { "timestamp":[3249, 2455], "text" : "המחשבה בדבר" }, { "timestamp":[3269, 1455], "text" : "המחשבה האמיתית" }, { "timestamp":[234, 24423342555], "text" : "היא מחתימה את הכל " }, { "timestamp":[3249, 2455], "text" : "עבור מישהו12 " } ] -
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@MGM-IVR אפשר את זה כסקריפט אחד שירוץ על קובץ בשם file.txt?
import json file = open('file.txt', 'r').read() data = json.loads(file) alltext = "" for i in data: alltext += i["text"] + "\n" open("output.txt", "w").write(alltext)הקובץ צריך להיות במבנה json כמובן
למשל[ { "timestamp":[3249, 2455], "text" : "המחשבה בדבר" }, { "timestamp":[3269, 1455], "text" : "המחשבה האמיתית" }, { "timestamp":[234, 24423342555], "text" : "היא מחתימה את הכל " }, { "timestamp":[3249, 2455], "text" : "עבור מישהו12 " } ]python script.py Traceback (most recent call last): File "C:\Users\*****\Desktop\מסמכים אישיים\*******\New folder\script.py", line 3, in <module> file = open('file.txt', 'r').read() ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\*****\AppData\Local\Programs\Python\Python311\Lib\encodings\cp1255.py", line 23, in decode return codecs.charmap_decode(input,self.errors,decoding_table)[0] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ UnicodeDecodeError: 'charmap' codec can't decode byte 0x9e in position 59: character maps to <undefined> -
ChatGPT סיפק את התשובה אחרי הרבה ניסיונות
def clean_text(input_text): hebrew_sentences = [] # קרא את הקובץ ונקה את המשפטים העבריים with open("input_file.txt", "r", encoding="utf-8") as file: for line in file: if '"text": "' in line: sentence = line.split('"text": "')[1].rstrip('\n').rstrip('"') hebrew_sentences.append(sentence) # החזר כל משפט בשורה נפרדת cleaned_text = "\n".join(hebrew_sentences) return cleaned_text # קרא את קובץ הטקסט וקרא את המשפטים cleaned_text = clean_text("input_file.txt") print(cleaned_text) # אם ברצונך לשמור את הטקסט הנקי בקובץ חדש with open("output_file.txt", "w", encoding="utf-8") as file: file.write(cleaned_text)https://chat.openai.com/share/3bc11429-df51-4046-b937-a98fc225c1b7
-
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@menajemmendel כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
^13
לא עובד
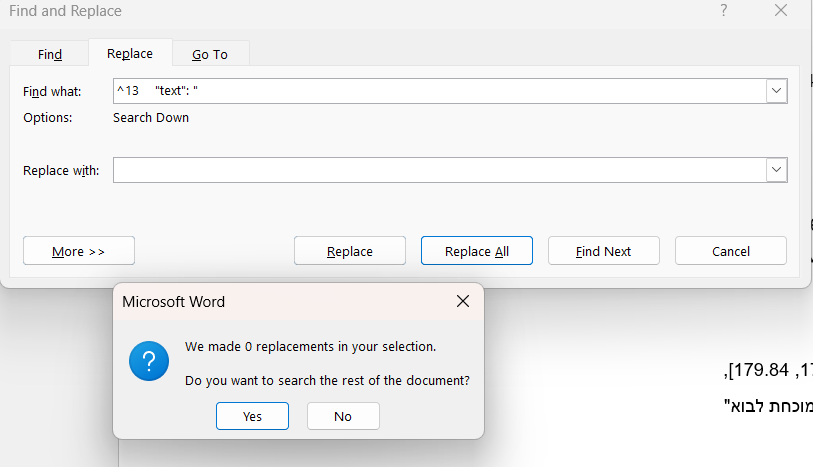
מעניין לי דוקא כן עובד, אולי כתבת מידי הרבה רווחים
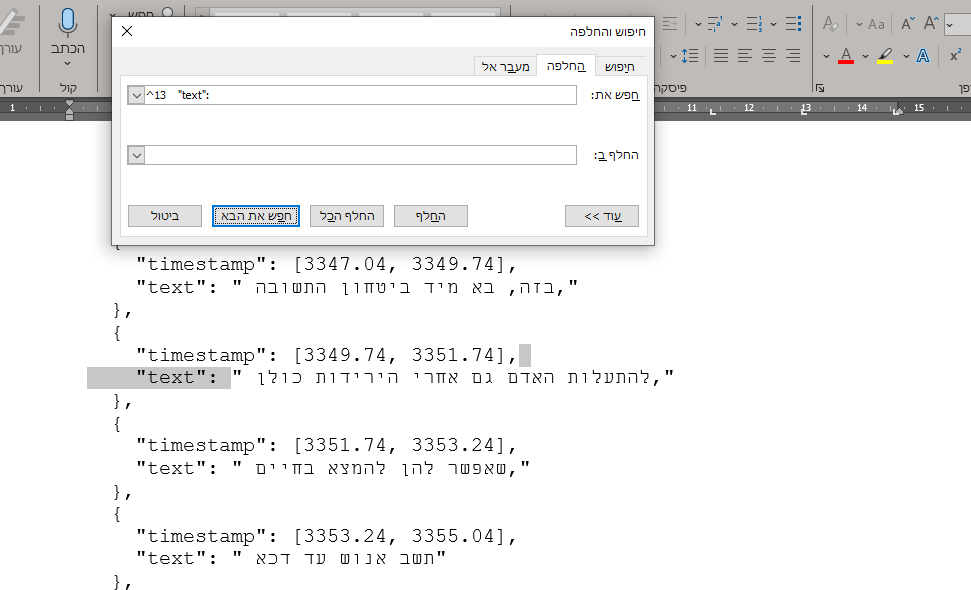
-
-
@מישהו12 כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
@menajemmendel כתב בבירור | ניקוי קובץ טקסט מתווים מיותרים:
^13
לא עובד
מעניין לי דוקא כן עובד, אולי כתבת מידי הרבה רווחים
@menajemmendel מוזר, עשיתי העתק הדבק. בטוח שבלי יותר מידי רווחים.
\בכל מקרה תודה לכולם, הסתדרתי עם
https://mitmachim.top/post/759544 -
 מ מישהו12 סימן נושא זה כשאלה ב
מ מישהו12 סימן נושא זה כשאלה ב
-
מ מישהו12 סימן נושא זה כנפתר ב
 { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}