שיתוף | סקריפט קבלת פודקאסט למייל
-
פוסט זה נמחק!
-
@מוגן בדקתי באתר של "משפחה" ומצאתי שבנוסף לרשימה שלמעלה יש גם את הפודקאסטים הבאים:
- סוף זמן
- לב אל הנשמה
- שניים בוחרים
- משפחה בצמיחה
- עוצרות לקפה
- הפסקת אש
- לא תשכח
- אחד בדור
- סיפור חוזר
- טיפוס גבוה
- מדע בכיף
- יומן מלחמה
- אוחילה
- שיעור חופשי
- מסע מוזיקלי
- דברי שיר
- מגלות מגילות
- בואי נדבר
- כאן בונים חוסן
- לב של אמא
- אוכל נפש
- סודה של אגודה
אני יכול לכתוב סקריפט עבור כולם אבל זה מיותר מכיון שחלק מהם כבר הסתיימו ולא מועלים בהם פרקים חדשים (לדוג' אליטוב פינת בלום)
תוכל אתה או מישהו אחר שמכיר לפרט איזה מהם עדיין פעילים?
-
@מתלמד-צעיר ההגבלה עד 50 מ"ב ניתנת לשינוי או לא, כי אם אפשר גם יותר אולי (אם זה לא מסובך), לעשות שבפעם הראשונה שמפעילים זה ישלח כמה מהפרקים האחרונים ולא רק את האחרון ממש.
-
@שני-אנשים כתב בשיתוף | סקריפט קבלת פודקאסט למייל:
@מתלמד-צעיר ההגבלה עד 50 מ"ב ניתנת לשינוי או לא
לא
-
@שני-אנשים גוגל
-
@מתלמד-צעיר ויש אפשרות שישלח גם את החלק השני בנפרד?
-
@שני-אנשים לא
עריכה: כן
-
@שני-אנשים וכל מי שמתעניין בסקריפט הזה, שני שאלות:
א. האם רצוי שהסקריפט יעלה כל פודקאסט לתיקיה אחרת?
ב. האם כדאי שלמייל יצורף המשפט וחצי שמופיע כרקע על הפרק הנוכחי של הפודקאסט -
אני לא מבין בזה בכלל, אבל רציתי לשאול האם ניתן לעשות סקריפט שיהיה ניתן להוסיף לו כתובת rss של כל פודקאסט שרוצים, או שלכל פודקאסט צריך התאמה מיוחדת של הסקריפט?
-
@האדם-החושב לכל פודקאסט התאמה מיוחדת
-
@מתלמד-צעיר
א. כן.
ב. זה יעזור, אבל לא חושב שמדי דחוף. תודה.
[עוד שאלה, אם יש אפשות לעשות שישלח את הפודקאסט אחד לפני האחרון?] -
@מתלמד-צעיר כתב בשיתוף | סקריפט קבלת פודקאסט למייל:
@האדם-החושב לכל פודקאסט התאמה מיוחדת
למה? לRSS יש מבנה קבוע...
-
@שני-אנשים כתב בשיתוף | סקריפט קבלת פודקאסט למייל:
[עוד שאלה, אם יש אפשות לעשות שישלח את הפודקאסט אחד לפני האחרון?]
כל פעם שיוצא פרק חדש אתה רוצה גם את הפרק שלפניו?
-
@מישהו12 כתב בשיתוף | סקריפט קבלת פודקאסט למייל:
למה? לRSS יש מבנה קבוע...
הסקריפט הזה לא עובד עם RSS
-
@מתלמד-צעיר כתב בשיתוף | סקריפט קבלת פודקאסט למייל:
כל פעם שיוצא פרק חדש אתה רוצה גם את הפרק שלפניו?
רק בפעם הראשונה, אבל מסתמא זה לא יעבוד במייל אחד כי זה יהיה מעל 50 מ"ב, אז אולי רק תסביר איך לשנות בסקריפט שיבחר פרק אחר.
-
@שני-אנשים זה מסובך
-
@מתלמד-צעיר
מצאתי את זה
עובד לפי rss עם גוגל שיטס ושומר לדרייב כל פודקאסט בתיקייה נפרדת
לא למדתי js כך שאני לא יודע אם הסקריפט בטוח
ניסיתי את הסקריפט על חשבון אחר, הוספתי את עושים טכנולוגיה וקיבלתי את השגיאה הבאה:
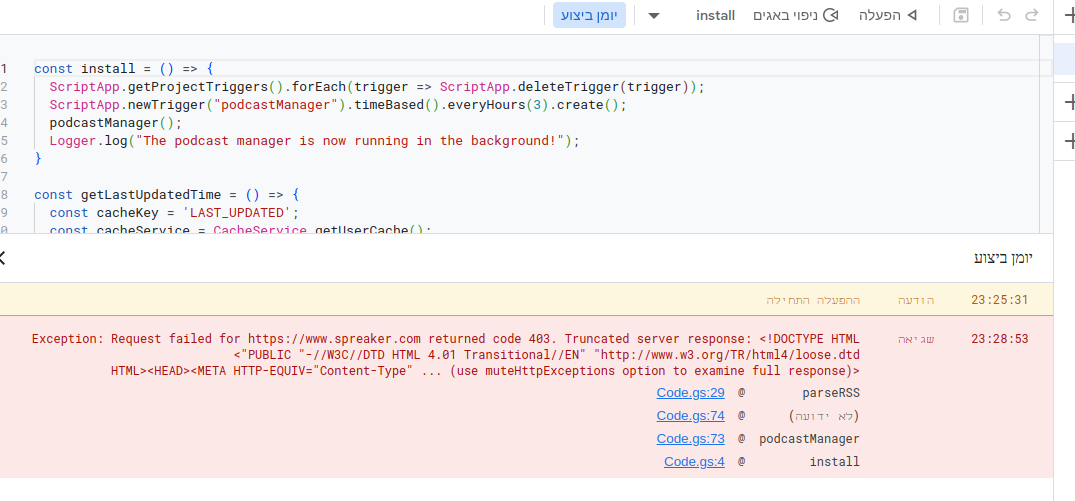
כך שכנראה זה לא עובד לכל הפודקאסטים, אבל אולי אפשר להתבסס על הקוד שם
ניסיתי את זה על עוד כמה פודקאסטים ללא הצלחה [אבל על הפודקאסטים שיש שם זה עובד]
@אביי @מנצפכ אולי תוכלו לעזור בעניין?
עריכה: gpt עזר לי קצתconst PHASES = { INSTALL: 'install', DOWNLOAD: 'download', }; const resumeFrom = PropertiesService.getUserProperties().getProperty('resumeFrom'); const install = () => { if (!resumeFrom || resumeFrom === PHASES.INSTALL) { // Phase 1: Remove existing triggers and create a new trigger ScriptApp.getProjectTriggers().forEach(trigger => ScriptApp.deleteTrigger(trigger)); ScriptApp.newTrigger("podcastManager").timeBased().everyHours(1).create(); // Run once an hour PropertiesService.getUserProperties().setProperty('resumeFrom', PHASES.DOWNLOAD); } if (!resumeFrom || resumeFrom === PHASES.DOWNLOAD) { // Phase 2: Start downloading podcasts podcastManager(); Logger.log("The podcast manager is now running in the background!"); PropertiesService.getUserProperties().deleteProperty('resumeFrom'); // Reset the phase } }; const getLastUpdatedTime = () => { const cacheKey = 'LAST_UPDATED'; const cacheService = CacheService.getUserCache(); const lastUpdatedTime = cacheService.get(cacheKey); cacheService.put(cacheKey, String(Date.now()), 21600); if (lastUpdatedTime) { return new Date(lastUpdatedTime); } const date = new Date(); date.setDate(date.getDate() - 2); return date; }; const getPodcastFolder = (folderName, containerFolder) => { const parentFolder = containerFolder || DriveApp.getRootFolder(); const folders = parentFolder.getFoldersByName(folderName); if (folders.hasNext()) return folders.next(); return parentFolder.createFolder(folderName); }; const parseRSS = (xmlUrl, lastUpdatedTime, includeAll, chapterLimit) => { try { const options = { headers: { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', }, }; const response = UrlFetchApp.fetch(xmlUrl, options); if (response.getResponseCode() === 200) { const feed = response.getContentText(); const doc = XmlService.parse(feed); const root = doc.getRootElement(); const channel = root.getChild('channel'); let episodes = channel .getChildren('item') .map((item) => { const date = new Date(item.getChildText('pubDate')); const title = item.getChildText('title').replace(/"/g, "'"); const enclosure = item.getChild('enclosure')?.getAttribute("url")?.getValue(); return { date, title, enclosure }; }) .filter(({ enclosure }) => enclosure); if (!includeAll) { // Limit the number of episodes based on the chapterLimit episodes = episodes.slice(0, chapterLimit); } return { title: channel.getChildText('title'), episodes }; } else { console.warn("HTTP error while fetching RSS:", response.getResponseCode()); return { title: "", episodes: [] }; // Return empty data for this feed } } catch (error) { console.error("Error while parsing RSS:", error); return { title: "", episodes: [] }; // Return empty data for this feed } }; const downloadPodcast = (episode, folder, episodeSheet) => { try { if (!episode || !episode.date || !episode.enclosure || !episode.title) { console.warn("Skipping invalid episode:", episode); return; } const { date, enclosure, title } = episode; const cacheKey = `downloaded_${title}`; // Check if the episode has already been downloaded if (CacheService.getUserCache().get(cacheKey)) { console.log("Episode already downloaded:", title); return; } const response = UrlFetchApp.fetch(enclosure); if (response.getResponseCode() === 200) { const blob = response.getBlob(); // Specify the desired file name (use episode title) const fileName = `${title}.mp3`; // You can adjust the file extension if needed const file = folder.createFile(blob.setName(fileName)); // Set the file name episodeSheet.appendRow([new Date(), date, `=HYPERLINK("${enclosure}";"${title}")`, `https://drive.google.com/file/d/${file.getId()}/view`]); // Mark the episode as downloaded in cache CacheService.getUserCache().put(cacheKey, 'downloaded', 21600); // Cache for 6 hours } else { console.warn("Skipping episode due to HTTP error:", response.getResponseCode()); } } catch (error) { console.error("Error while downloading podcast:", error); } }; const getSubscriptions = () => { const ss = SpreadsheetApp.getActiveSpreadsheet(); const sheet = ss.getSheetByName('Subscriptions'); const episodeSheet = ss.getSheetByName('Episodes'); const [header, ...podcasts] = sheet .getDataRange() .getValues() .map(([rss]) => rss) .filter(Boolean); const lastUpdatedTime = getLastUpdatedTime(); const parentFolder = getPodcastFolder('Podcasts'); return { episodeSheet, parentFolder, podcasts, lastUpdatedTime }; }; const podcastManager = () => { const { episodeSheet, parentFolder, podcasts, lastUpdatedTime } = getSubscriptions(); const delayBetweenPodcasts = 1000; // 1 second in milliseconds podcasts.forEach((xmlUrl) => { const includeAll = shouldIncludeAll(xmlUrl); // Determine if "all" should be included based on the XML URL const chapterLimit = getChapterLimit(xmlUrl); // Get the chapter limit from column C based on the XML URL const { title, episodes } = parseRSS(xmlUrl, lastUpdatedTime, includeAll, chapterLimit); if (episodes.length > 0) { const folder = getPodcastFolder(title, parentFolder); episodes.slice(0, chapterLimit).forEach((episode) => { downloadPodcast(episode, folder, episodeSheet); Utilities.sleep(delayBetweenPodcasts); // Add a 1-second delay between podcasts }); } }); }; const shouldIncludeAll = (xmlUrl) => { // You may need to adjust this logic based on the structure of your spreadsheet const sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('Subscriptions'); const rows = sheet.getDataRange().getValues(); for (const row of rows) { if (row[0] === xmlUrl) { if (row[2] === 'all') { return true; } else if (!isNaN(row[2])) { return false; } } } return false; // Default to false if not found }; const getChapterLimit = (xmlUrl) => { // You may need to adjust this logic based on the structure of your spreadsheet const sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('Subscriptions'); const rows = sheet.getDataRange().getValues(); for (const row of rows) { if (row[0] === xmlUrl) { if (row[2] === 'all') { return Number.MAX_SAFE_INTEGER; // Download all episodes } else if (!isNaN(row[2])) { return Math.max(1, parseInt(row[2], 10)); // Ensure it's at least 1 } } } return 5; // Default to 5 if not found }; const openPodcast = () => { const cell = SpreadsheetApp.getActiveSheet().getActiveCell().getValue(); if (!/drive.google.com/.test(cell)) { SpreadsheetApp.getActiveSpreadsheet().toast("Please select any podcast drive link in Column D"); return; } const html = `<iframe src="${cell.replace('view', 'preview')}" width="480" height="170" frameborder="0" scrolling="no"></iframe>` const dialog = HtmlService.createHtmlOutput(html).setTitle("Play").setWidth(500).setHeight(200); SpreadsheetApp.getUi().showModelessDialog(dialog, "Play Podcast") } // Run the install function install();והנה עוד פונקציה שתעבד קובץ opml לשמות וכתובות rss:
function importOPMLFile() { var sheet = SpreadsheetApp.getActiveSheet(); // Prompt the user to upload an OPML file var file = DriveApp.getFileById('YOUR_OPML_FILE_ID_HERE'); // Read the contents of the OPML file var opmlContent = file.getBlob().getDataAsString(); // Parse the OPML content var xmlDoc = XmlService.parse(opmlContent); var opmlRoot = xmlDoc.getRootElement(); // Get all the outline elements (podcast entries) within the OPML file var outlines = opmlRoot.getChildren('body')[0].getChildren('outline'); // Initialize arrays to store RSS addresses and podcast names var rssAddresses = []; var podcastNames = []; // Loop through each outline element for (var i = 0; i < outlines.length; i++) { var outline = outlines[i]; var rssUrl = outline.getAttribute('xmlUrl').getValue(); var podcastName = outline.getAttribute('title').getValue(); // Add the RSS address and podcast name to their respective arrays rssAddresses.push([rssUrl]); podcastNames.push([podcastName]); } // Write the RSS addresses and podcast names to the first two columns of the sheet sheet.getRange(1, 1, rssAddresses.length, 1).setValues(rssAddresses); sheet.getRange(1, 2, podcastNames.length, 1).setValues(podcastNames); }[צריך להכניס id לקובץ opml שקיים בדרייב]
לא הצלחתי לפצל קבצים מעל 50 מגה
במקרה ומריצים את זה על הרבה פודקאסטים מקבלים אחרי זמן מה את השגיאה הבאה:
Exceeded maximum execution time
[חריגת זמן ריצה מירבי]
ניסיתי לתקן ולא עלתה בידי
יש עוד שגיאות שריצה אחת קיימות ובריצה אחרת לא, כך שמקסימום אם יש שגיאה ניתן להריץ שוב
בברירת מחדל הוא מוריד את ה5 פודקאסטים האחרונים, ניתן לחילופין להכניס בעמודה c מספר אחר, או לכתוב "all"
מי שרוצה לשפץ/לתקן וכו' תע"ב
[ניתן גם להכניס כתובות rss לקול הלשון] -
@האדם-החושב איך אני מוצא RSS של פודקאסט?
{if(result!=null&&result!=''){var a=document.createElement('a');a.href='https://www.google.co.il/search?q=site:mitmachim.top '+encodeURIComponent(result.trim());a.target='_blank';a.click();}}})();};){kind=link}