היו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!
-
@אלף-שין
@י-פל
מנסיון אישי, בכתב מרובע הזיהוי תווים שבווינדוס 11 עוקף את כל התוכנות למיניהם, אולי אפשר למצוא את המנוע / תוכנה שאיתה הוא משתמש, ולהפיק מכך תוכנת OCR המדוייקת ביותר בשוק.אמנם זה לא יעזור לכתב רש"י, שעד כמה שידוע לי ABBYY עם הגדרה רק עברית, ועם גופן רש"י שהכי קרוב לקיים בספר, מזוהה בינתיים עם הכי פחות שגיאות.
-
@דאנציג כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
מנסיון אישי, בכתב מרובע הזיהוי תווים שבווינדוס 11 עוקף את כל התוכנות למיניהם,
קיים באופליין?
@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
@דאנציג כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
מנסיון אישי, בכתב מרובע הזיהוי תווים שבווינדוס 11 עוקף את כל התוכנות למיניהם,
קיים באופליין?
כן.
-
@י-פל כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
@aiib כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
@י-פל כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
@אלף-שין אם היה דרך איכשהו לשלב בין חילוץ טקסט לPDF עצמו, זה היה פשוט מושלם!
כלומר?
מישהו [אולי אתה?] הביא אפשרות לחילוץ טקסט ע"י גוגל-לנס, יש עוד כמה אפשרויות קלות ומהירות.
הבעיה, שכל עוד אין לנו דרך לדחוף את הטקסט מאחורי המסמך, זה לא שווה כלום.
ולכן כתבתי, שאם היה דרך, זה היה קל ומושלם.
וע"ז הבאתי את הצ'אט עם GPT, אך אין לי רגע פנוי לבדוק זאת, לילה טוב.התוכנות ש @אלף-שין הביא עושות את הפעולה, אתה חושב שגוגל לאנס וכדו' יעשו עבודה יותר טובה אחרי שנצליח לחבר את הטקסט מאחורה?
-
@aiib
@י-פל
תראה את הניסוי שהעלתי לעיל
https://mitmachim.top/topic/80826/היו-שותפים-בפרוייקט-זיהוי-תווים-גדול-וחשוב-מאד/12אתמול המרתי כך 32 דפים אחד אחד
נראה שיש 0 טעויות@אמיר כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
תראה את הניסוי שהעלתי לעיל
בדיוק בשביל זה הלכתי לבדוק אם אפשר לחלק את המשימה ל2 - זיהוי טקסט עם LENS, והוספתו לקובץ. בדיוק בגלל הפוסט שלך [והגיט שהביאו שם]!
האם תוכל לנסות את השיטה שהוא הביא לי?
אני ממש לחוץ בזמן. יש לי כמה דברים על הראש כעת, אחרת לא הייתי זורק זאת עליך...גאה להיות חלק:
otzaria.org -
@אמיר כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
תראה את הניסוי שהעלתי לעיל
בדיוק בשביל זה הלכתי לבדוק אם אפשר לחלק את המשימה ל2 - זיהוי טקסט עם LENS, והוספתו לקובץ. בדיוק בגלל הפוסט שלך [והגיט שהביאו שם]!
האם תוכל לנסות את השיטה שהוא הביא לי?
אני ממש לחוץ בזמן. יש לי כמה דברים על הראש כעת, אחרת לא הייתי זורק זאת עליך...@י-פל אני לא מבין בזה כלום, אבל כעת כשפתחתי את כרום הוא הציג לי
את זה chrome://whats-new/ (קישור כזה בכרום של מה חדש) אמור לעזור איכשהו? ייתכן גם שאני סתם מבלבל במוח... -
שלום רב,
כהמשך לרעיון שהעלו בשרשור שם
אני פותח פה את הפרוייקט המיוחד בצורה מסודרת וברורה.[פרוייקט שיתופי של OCR ל60,000 קבצים המכילים 11.7 מיליון עמודים!]
תחילה יש להתקין תוכנה של OCR
כל אחד יוכל לבחור באחד מבין 3 אפשרויות איך לבצע את הזיהוי אצלו,1] בתוכנת ABBYY מכאן או באחד מהכלים האחרים שלהם [SDK /סרבר/עוד]
2] בתוכנת PDF-XChange מכאן {בכלי בשם טולס} [יש להגדיר שיהיה OCR משופר].
3] בתוכנה של רחמים זה מיועד רק למי שקנה את התוכנה מרחמים [ורק אם הרישיון שהוא נותן הוא ללא הגבלה].
בשלושתם יהיה תוצאה טובה שמספיקה לעניינינו.בכל האפשרויות יש צורך גדול להגדיר ששפת הזיהוי היא עברית בלבד!
וזה כדי שלא יהיה פיענוחים שגויים בעשרות שפות אחרות, וגם זה יקצר את העבודה מאד!לאחר מכן כל אחד בוחר את כמות הקבצים שהוא מעונין להמיר,
ומעדכן כאן, או במייל 0556781863A@GMAIL.COM או באישי ואנו נשלח לו למייל קישור לדרייב המכיל תיקייה עם כמות הקבצים שהוא ציין,
בנוסף נשלח לו קישור לתיקייה נוספת בדרייב לשם הוא יעלה את הקבצים לאחר העיבוד,יצוין כי אם מתקינים דרייב לשולחן עבודה,
אפשר לבצע את כל ההמרה כולל ההעלאה לדרייב בלחיצת כפתור אחת!
פשוט כל לילה 'לפני השינה' לוחצים על כפתור אחד וכל הלילה המחשב מעבד עוד ועוד קבצים ומעלה אותם בעצמו לתיקייה הרצויה בדרייב!
מי שרוצה נוכל להדריכו כאן.אם מישהו מוכן לעבוד על כמות גדולה אבל לא מתאים לו להוריד מהדרייב,
ישלח לנו את מיקום מגוריו, ונראה אם שייך להעביר לו את הקבצים ידנית.בהצלחה לכולנו!!
ושיהיה בעז"ה ס"ד גדולה לטובת כולם!!
@אלישי @aiib @האדם-החושב @י-פל @יעקב-מ-פינס @יהודה-12 @אמיר @דאנציג @משה-מזרחי @A0533057932 @NH-LOCAL
לכל תגובה/רעיון לשדרוג נא להגיב רק כאן,
זה נושא מסודר וחדש!כל אחד יכול לעזור ולהוסיף!!
בלי שום התחייבות!
בסוף הכל מצטרף לחשבון גדול!!חיפשתי קצת אחר הכלי הזה OCRmyPDF ומצאתי את ה GUI הזה שאמור לבצע זיהוי והטמעה
הורדתי והרצתי והוא דורש התקנה של שני הכלים
עוד לא הצלחתי להבין איך (המתכנתים שכאן בטח יסתדרו יותר טוב)https://forum.xojo.com/t/open-source-ocrjob-an-ocrmypdf-gui-front-end/75654
https://github.com/ocrmypdf/OCRmyPDF
https://github.com/tesseract-ocr/tesseract
בהתקנה הזו צריך לסמן גם מערכת זיהוי עברית
https://yer.dl.sourceforge.net/project/tesseract-ocr.mirror/5.5.0/tesseract-ocr-w64-setup-5.5.0.20241111.exe?viasf=1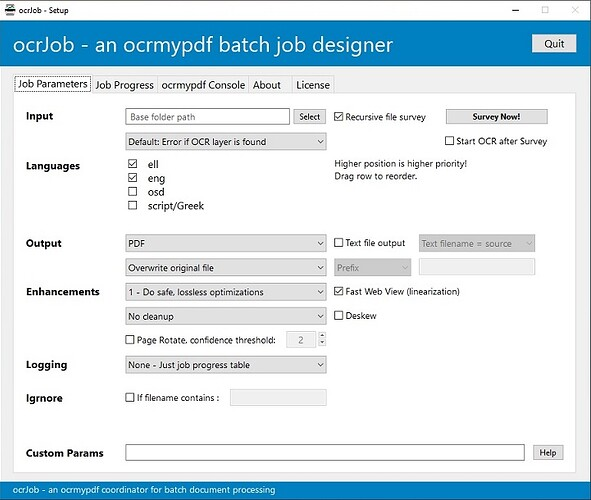
-
חיפשתי קצת אחר הכלי הזה OCRmyPDF ומצאתי את ה GUI הזה שאמור לבצע זיהוי והטמעה
הורדתי והרצתי והוא דורש התקנה של שני הכלים
עוד לא הצלחתי להבין איך (המתכנתים שכאן בטח יסתדרו יותר טוב)https://forum.xojo.com/t/open-source-ocrjob-an-ocrmypdf-gui-front-end/75654
https://github.com/ocrmypdf/OCRmyPDF
https://github.com/tesseract-ocr/tesseract
בהתקנה הזו צריך לסמן גם מערכת זיהוי עברית
https://yer.dl.sourceforge.net/project/tesseract-ocr.mirror/5.5.0/tesseract-ocr-w64-setup-5.5.0.20241111.exe?viasf=1@אמיר כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
חיפשתי קצת אחר הכלי הזה OCRmyPDF ומצאתי את ה GUI הזה שאמור לבצע זיהוי והטמעה
אבל מה האיכות שלו?
יותר מאבי?גאה להיות חלק:
otzaria.org -
@אמיר כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
חיפשתי קצת אחר הכלי הזה OCRmyPDF ומצאתי את ה GUI הזה שאמור לבצע זיהוי והטמעה
אבל מה האיכות שלו?
יותר מאבי? -
@י-פל
בגלל ש CLI לא נוח חיפשתי ממשק גרפי GUI
אבל עדיין לא הבנתי איפה לספק לו את שני הכלים הנוספים
עדיין כותב לי שהם לא מותקנים במחשב -
שלום רב,
כהמשך לרעיון שהעלו בשרשור שם
אני פותח פה את הפרוייקט המיוחד בצורה מסודרת וברורה.[פרוייקט שיתופי של OCR ל60,000 קבצים המכילים 11.7 מיליון עמודים!]
תחילה יש להתקין תוכנה של OCR
כל אחד יוכל לבחור באחד מבין 3 אפשרויות איך לבצע את הזיהוי אצלו,1] בתוכנת ABBYY מכאן או באחד מהכלים האחרים שלהם [SDK /סרבר/עוד]
2] בתוכנת PDF-XChange מכאן {בכלי בשם טולס} [יש להגדיר שיהיה OCR משופר].
3] בתוכנה של רחמים זה מיועד רק למי שקנה את התוכנה מרחמים [ורק אם הרישיון שהוא נותן הוא ללא הגבלה].
בשלושתם יהיה תוצאה טובה שמספיקה לעניינינו.בכל האפשרויות יש צורך גדול להגדיר ששפת הזיהוי היא עברית בלבד!
וזה כדי שלא יהיה פיענוחים שגויים בעשרות שפות אחרות, וגם זה יקצר את העבודה מאד!לאחר מכן כל אחד בוחר את כמות הקבצים שהוא מעונין להמיר,
ומעדכן כאן, או במייל 0556781863A@GMAIL.COM או באישי ואנו נשלח לו למייל קישור לדרייב המכיל תיקייה עם כמות הקבצים שהוא ציין,
בנוסף נשלח לו קישור לתיקייה נוספת בדרייב לשם הוא יעלה את הקבצים לאחר העיבוד,יצוין כי אם מתקינים דרייב לשולחן עבודה,
אפשר לבצע את כל ההמרה כולל ההעלאה לדרייב בלחיצת כפתור אחת!
פשוט כל לילה 'לפני השינה' לוחצים על כפתור אחד וכל הלילה המחשב מעבד עוד ועוד קבצים ומעלה אותם בעצמו לתיקייה הרצויה בדרייב!
מי שרוצה נוכל להדריכו כאן.אם מישהו מוכן לעבוד על כמות גדולה אבל לא מתאים לו להוריד מהדרייב,
ישלח לנו את מיקום מגוריו, ונראה אם שייך להעביר לו את הקבצים ידנית.בהצלחה לכולנו!!
ושיהיה בעז"ה ס"ד גדולה לטובת כולם!!
@אלישי @aiib @האדם-החושב @י-פל @יעקב-מ-פינס @יהודה-12 @אמיר @דאנציג @משה-מזרחי @A0533057932 @NH-LOCAL
לכל תגובה/רעיון לשדרוג נא להגיב רק כאן,
זה נושא מסודר וחדש!כל אחד יכול לעזור ולהוסיף!!
בלי שום התחייבות!
בסוף הכל מצטרף לחשבון גדול!! -
@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
2] בתוכנת PDF-XChange מכאן {בכלי בשם טולס} [יש להגדיר שיהיה OCR משופר].
האם ישנה דרך להמיר כמות קבצים בבת אחת?
-
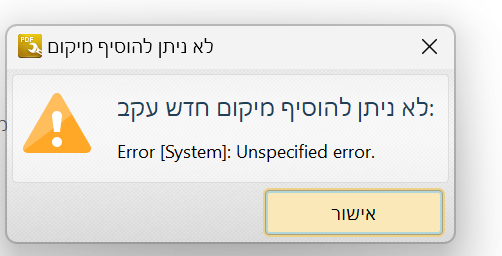
@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
@aiib
כן
בטולס.
זה מותקן על שולחן העבודה.מקבל שגיאה:
-
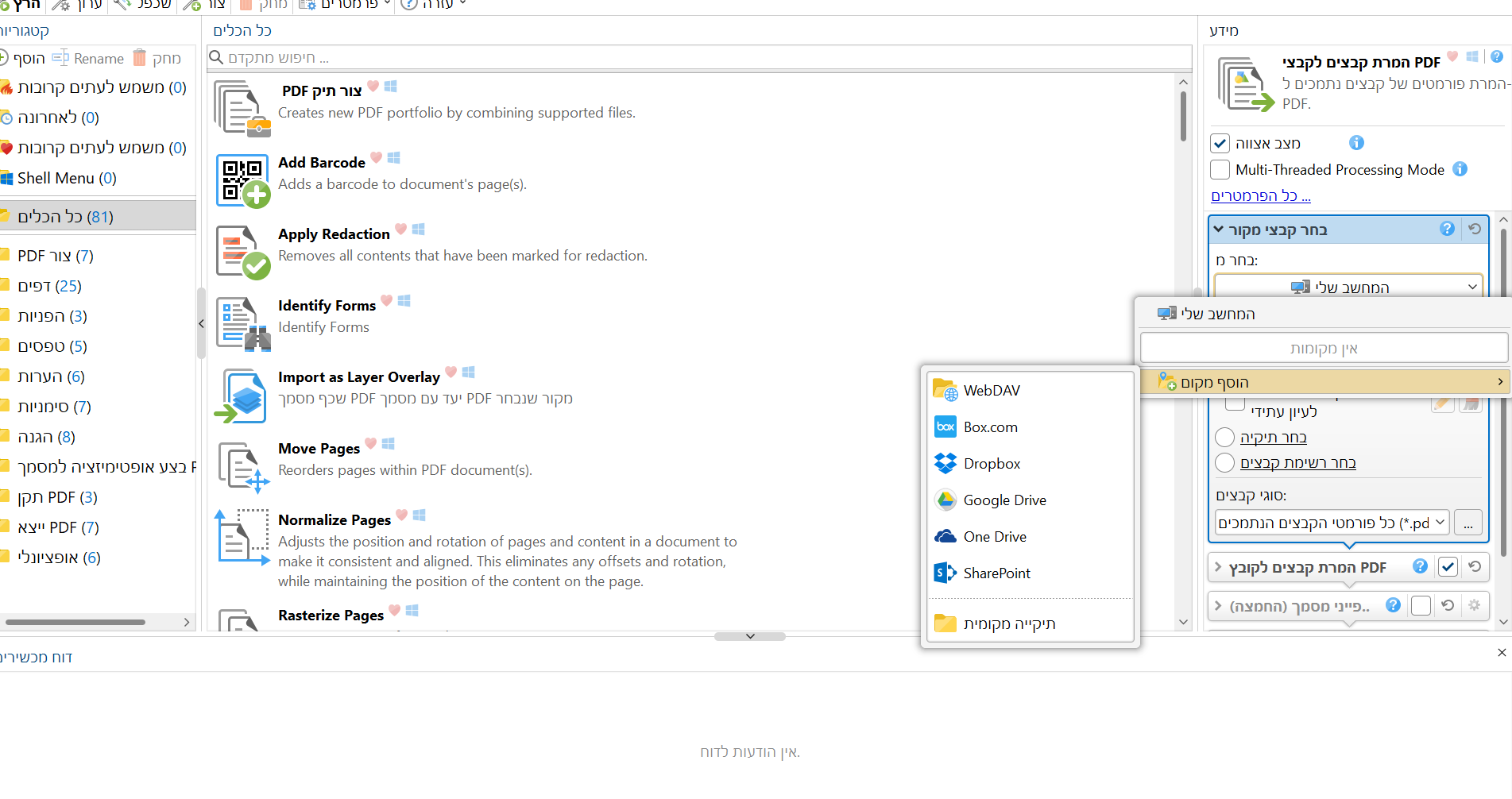
@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
@aiib
אפשר צילום מסך משלב קודם?בחרתי גוגל דרייב
-
@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
@aiib
אפשר צילום מסך משלב קודם?בחרתי גוגל דרייב
-
@אלף-שין כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
@aiib
אפשר צילום מסך משלב קודם?בחרתי גוגל דרייב
@aiib בנטפרי? כנראה נושא של תעודת אבטחה.
אבל אם יש לך דרייב לשולחן עבודה, אתה פשט בוחר את התיקיי' בצורה רגילה כמו כל תיקיי'. -
@אלף-שין
@י-פל
מנסיון אישי, בכתב מרובע הזיהוי תווים שבווינדוס 11 עוקף את כל התוכנות למיניהם, אולי אפשר למצוא את המנוע / תוכנה שאיתה הוא משתמש, ולהפיק מכך תוכנת OCR המדוייקת ביותר בשוק.אמנם זה לא יעזור לכתב רש"י, שעד כמה שידוע לי ABBYY עם הגדרה רק עברית, ועם גופן רש"י שהכי קרוב לקיים בספר, מזוהה בינתיים עם הכי פחות שגיאות.
@דאנציג כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
אולי אפשר למצוא את המנוע / תוכנה שאיתה הוא משתמש, ולהפיק מכך תוכנת OCR המדוייקת ביותר בשוק.
ראה כאן:
https://github.com/microsoft/PowerToys/issues/30159#issuecomment-1886341385 -
@דאנציג כתב בהיו שותפים בפרוייקט זיהוי תווים גדול וחשוב מאד!:
אולי אפשר למצוא את המנוע / תוכנה שאיתה הוא משתמש, ולהפיק מכך תוכנת OCR המדוייקת ביותר בשוק.
ראה כאן:
https://github.com/microsoft/PowerToys/issues/30159#issuecomment-1886341385 -
שלום רב,
כהמשך לרעיון שהעלו בשרשור שם
אני פותח פה את הפרוייקט המיוחד בצורה מסודרת וברורה.[פרוייקט שיתופי של OCR ל60,000 קבצים המכילים 11.7 מיליון עמודים!]
תחילה יש להתקין תוכנה של OCR
כל אחד יוכל לבחור באחד מבין 3 אפשרויות איך לבצע את הזיהוי אצלו,1] בתוכנת ABBYY מכאן או באחד מהכלים האחרים שלהם [SDK /סרבר/עוד]
2] בתוכנת PDF-XChange מכאן {בכלי בשם טולס} [יש להגדיר שיהיה OCR משופר].
3] בתוכנה של רחמים זה מיועד רק למי שקנה את התוכנה מרחמים [ורק אם הרישיון שהוא נותן הוא ללא הגבלה].
בשלושתם יהיה תוצאה טובה שמספיקה לעניינינו.בכל האפשרויות יש צורך גדול להגדיר ששפת הזיהוי היא עברית בלבד!
וזה כדי שלא יהיה פיענוחים שגויים בעשרות שפות אחרות, וגם זה יקצר את העבודה מאד!לאחר מכן כל אחד בוחר את כמות הקבצים שהוא מעונין להמיר,
ומעדכן כאן, או במייל 0556781863A@GMAIL.COM או באישי ואנו נשלח לו למייל קישור לדרייב המכיל תיקייה עם כמות הקבצים שהוא ציין,
בנוסף נשלח לו קישור לתיקייה נוספת בדרייב לשם הוא יעלה את הקבצים לאחר העיבוד,יצוין כי אם מתקינים דרייב לשולחן עבודה,
אפשר לבצע את כל ההמרה כולל ההעלאה לדרייב בלחיצת כפתור אחת!
פשוט כל לילה 'לפני השינה' לוחצים על כפתור אחד וכל הלילה המחשב מעבד עוד ועוד קבצים ומעלה אותם בעצמו לתיקייה הרצויה בדרייב!
מי שרוצה נוכל להדריכו כאן.אם מישהו מוכן לעבוד על כמות גדולה אבל לא מתאים לו להוריד מהדרייב,
ישלח לנו את מיקום מגוריו, ונראה אם שייך להעביר לו את הקבצים ידנית.בהצלחה לכולנו!!
ושיהיה בעז"ה ס"ד גדולה לטובת כולם!!
@אלישי @aiib @האדם-החושב @י-פל @יעקב-מ-פינס @יהודה-12 @אמיר @דאנציג @משה-מזרחי @A0533057932 @NH-LOCAL
לכל תגובה/רעיון לשדרוג נא להגיב רק כאן,
זה נושא מסודר וחדש!כל אחד יכול לעזור ולהוסיף!!
בלי שום התחייבות!
בסוף הכל מצטרף לחשבון גדול!! -
@אלף-שין שימו לב למדריך החדש והמפורט של @אלישי לזיהוי התווים!
https://mitmachim.top/post/929469@פלמנמוני אכן זוהי בינתיים התוכנה היחידה בווינדוס שיודעת בשעת הפיענוח לסובב את העמודים ואת ההטייה כדי לפענח בצורה טובה, ואז בשעת השמירה להשאיר את התמונה המקורית, לצערי abbyy לא יודע לעשות זאת (הם כותבים שזה ידוע להם וזה בפיתוח), ולכן כרגע, זה התוכנה היחידה שמתאימה לפרויקט הזה.
יש חיסרון בתוכנה זו, שהוא לא מנהל את התור של הקבצים בצורה טובה, אלא רק בסיום כל הסריקה הוא מעביר את הקבצים, אני בונה עכשיו סקריפט מותאם לפרויקט הזה שינהל את זה בצורה טובה ויעילה.
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}