בירור | תגובה: איך לעשות שCMD יכתוב בעברית
-
תגובה: איך לעשות שCMD יכתוב בעברית
@amit5470 כתב באיך לעשות שCMD יכתוב בעברית:
האם יש כזה קובץ שהופך טקסט בהתאם ל"כיווניות" שלו?
כלומר שרק החלק שבטקסט שהוא בעברית יתהפך אבל לא החלק שבאנגלית?
אחרת זה נראה ככה:3pm.)1(אודיו3pm.פרק 92- המבחן של המדינה\sdaolnwoD\resu\sresU\:C הקובץ@מתלמד-צעיר עשיתי תוכנה בHaskell, ונראה לי שזה עובד טוב ב"ה
hecho.exe
יש שתי אפשרויות:
- היפוך כל הסדר של הטקסט (עם הארגומנט
-a) - היפוך המילים בעברית בלבד (עם הארגומנט
-b)
דוגמאות לשימוש:
hecho -a "שלום, hi עולם!"
hecho -b "C:\Users\User\Downloads\מסמך טקסט חדש (2).txt"
זה הקוד: (עשיתי עם GPT ואני עדיין לא מבין הרבה חלקים בקוד)
import System.Environment (getArgs) import Control.Monad (when) import Data.Char (isAlpha, isAsciiLower, isAsciiUpper) import Data.Maybe (fromMaybe) -- הגדרות לסיווג תו לפי שפה isHebrew :: Char -> Bool isHebrew c = c >= 'א' && c <= 'ת' isEnglish :: Char -> Bool isEnglish c = isAsciiLower c || isAsciiUpper c -- מחזירה Just "Hebrew" או Just "English" עבור אות, או Nothing עבור סימן פיסוק/רווח charLang :: Char -> Maybe String charLang c | isHebrew c = Just "Hebrew" | isEnglish c = Just "English" | otherwise = Nothing ------------------------------------------------------------ -- טיפוסי טוקנים: טוקן אות – כולל מחרוזת ותווית שפה; -- טוקן פיסוק/רווח data Token = Letter { content :: String, lang :: String } | Punct { content :: String } deriving (Show) -- פונקציה שמפצלת מחרוזת לרשימת טוקנים: -- קבוצות רציפות של אותיות (אותן מסווגים לפי charLang) או קבוצות של סימני פיסוק/רווח tokenize :: String -> [Token] tokenize "" = [] tokenize s@(c:_) | isAlpha c = let (letters, rest) = span (\ch -> isAlpha ch && charLang ch == charLang c) s in Letter letters (fromMaybe "" (charLang c)) : tokenize rest | otherwise = let (punct, rest) = break isAlpha s in Punct punct : tokenize rest ------------------------------------------------------------ -- מצב סגמנטציה: בשיטה זו נבצע הקצאה מחדש של סימני פיסוק בגבולות בלוקים. -- במצב SegHebrew – target היא "Hebrew" -- במצב SegEnglish – target היא "English" data SegMode = SegHebrew | SegEnglish deriving (Eq, Show) -- עוזרת: האם שפה נתונה היא target בהתאם למצב הסגמנטציה isTarget :: SegMode -> String -> Bool isTarget SegHebrew l = l == "Hebrew" isTarget SegEnglish l = l == "English" -- נרצה לאסוף טוקנים לכדי בלוקים (מחרוזות) כך שהטוקנים המקוריים לא ישתנו, -- אך סימני הפיסוק שבגבולות יועברו בהתאם לכלל הבא: -- -- נניח שיש לנו גבול בין טוקן אות (T_prev) לטוקן אות (T_next) עם טוקני פיסוק ביניהם (PunctSeq). -- אז: -- • אם T_prev ו–T_next שונות בשייכות target, נחלק את PunctSeq לשניים: -- - במצב SegHebrew (target = Hebrew): אם T_prev הוא target (Hebrew) ו–T_next אינו, נרצה שהתוצאה תהיה: -- בלוק target: T_prev בלבד, -- בלוק non-target: (PunctSeq עם הסימן האחרון מופיע בסופו) <> T_next... -- - במצב SegEnglish (target = English): אם T_prev אינו target וה–T_next הוא target, אזי -- בלוק non-target: T_prev <> (PunctSeq עם הסימן הראשון בסופו), -- בלוק target: T_next... -- • במקרים בהם שני הטוקנים הם מאותה קטגוריה – פשוט מצרפים את הפיסוק לטוקן הקודם. -- -- בפועל, נממש פונקציה שמסכמת את רשימת הטוקנים ומעבירה את סימני הפיסוק בהתאם. reassemble :: SegMode -> [Token] -> [String] reassemble mode toks = mergeBlocks (assignPunct mode toks) where -- assignPunct מעבירה סימני פיסוק בגבולות לפי הכלל הפשוט הבא: assignPunct :: SegMode -> [Token] -> [Token] assignPunct _ [] = [] assignPunct _ [t] = [t] assignPunct m (t1 : Punct punc : t2 : rest) = case (t1, t2) of (Letter _ l1, Letter _ l2) | isTarget m l1 || isTarget m l2 -> -- במקרה של גבול target–non-target if isTarget m l1 && not (isTarget m l2) then -- במצב SegHebrew: אם הטוקן השמאלי הוא target, העבר את כל הפיסוק לבלוק הימני t1 : assignPunct m (Letter punc l2 : t2 : rest) else if not (isTarget m l1) && isTarget m l2 then -- במצב SegEnglish: אם הטוקן הימני הוא target, העבר את כל הפיסוק לבלוק השמאלי let newT1 = Letter (content t1 ++ punc) l1 in newT1 : assignPunct m (t2 : rest) else -- אם שני הצדדים target או שניהם non-target – צרף לפסיק ל-T_prev let newT1 = Letter (content t1 ++ punc) (lang t1) in newT1 : assignPunct m (t2 : rest) _ -> t1 : assignPunct m (Punct punc : t2 : rest) assignPunct m (t:rest) = t : assignPunct m rest -- mergeBlocks פשוט ממזג טוקנים עוקבים לשרשרת אחת (מבוסס על content) mergeBlocks :: [Token] -> [String] mergeBlocks [] = [] mergeBlocks (t:ts) = let (grp, rest) = span (sameType t) ts block = concatMap content (t:grp) in block : mergeBlocks rest where sameType :: Token -> Token -> Bool sameType (Letter _ l1) (Letter _ l2) = l1 == l2 sameType (Punct _) (Punct _) = True -- לא ממזג בין אות לפיסוק sameType _ _ = False ------------------------------------------------------------ -- פונקציות עיבוד טקסט: -- -- במצב all: -- 1. הופכים את כל הטקסט (reverse) -- 2. מפצלים לבלוקים בעזרת reassemble במצב SegEnglish -- 3. בתוך הרשימה, בלוקים ששייכים לאנגלית (target במצב SegEnglish) חוזרים הפיכה כדי לשחזר את הסדר המקורי. processAll :: String -> String processAll s = let revText = reverse s toks = tokenize revText blocks = reassemble SegEnglish toks fixed = map (\blk -> if any isEnglish blk then reverse blk else blk) blocks in concat fixed -- במצב blocks: -- מפצלים לבלוקים בעזרת reassemble במצב SegHebrew -- ואז הופכים רק את הבלוקים בהם מופיעות אותיות בעברית. processBlocks :: String -> String processBlocks s = let toks = tokenize s blocks = reassemble SegHebrew toks fixed = map (\blk -> if any isHebrew blk then reverse blk else blk) blocks in concat fixed -- Add helper function to remove invisible characters. removeInvisible :: String -> String removeInvisible = filter (\c -> c /= '\x200F' && c /= '\x202B') main :: IO () main = do args <- getArgs when (length args >= 2) $ do let (flag:rest) = args txt = removeInvisible $ unwords rest -- remove invisible characters from input case flag of "-a" -> putStrLn $ processAll txt "-b" -> putStrLn $ processBlocks txt _ -> return () - היפוך כל הסדר של הטקסט (עם הארגומנט
-
@מתלמד-צעיר עשיתי תוכנה בHaskell, ונראה לי שזה עובד טוב ב"ה
hecho.exe
יש שתי אפשרויות:
- היפוך כל הסדר של הטקסט (עם הארגומנט
-a) - היפוך המילים בעברית בלבד (עם הארגומנט
-b)
דוגמאות לשימוש:
hecho -a "שלום, hi עולם!"hecho -b "C:\Users\User\Downloads\מסמך טקסט חדש (2).txt"זה הקוד: (עשיתי עם GPT ואני עדיין לא מבין הרבה חלקים בקוד)
import System.Environment (getArgs) import Control.Monad (when) import Data.Char (isAlpha, isAsciiLower, isAsciiUpper) import Data.Maybe (fromMaybe) -- הגדרות לסיווג תו לפי שפה isHebrew :: Char -> Bool isHebrew c = c >= 'א' && c <= 'ת' isEnglish :: Char -> Bool isEnglish c = isAsciiLower c || isAsciiUpper c -- מחזירה Just "Hebrew" או Just "English" עבור אות, או Nothing עבור סימן פיסוק/רווח charLang :: Char -> Maybe String charLang c | isHebrew c = Just "Hebrew" | isEnglish c = Just "English" | otherwise = Nothing ------------------------------------------------------------ -- טיפוסי טוקנים: טוקן אות – כולל מחרוזת ותווית שפה; -- טוקן פיסוק/רווח data Token = Letter { content :: String, lang :: String } | Punct { content :: String } deriving (Show) -- פונקציה שמפצלת מחרוזת לרשימת טוקנים: -- קבוצות רציפות של אותיות (אותן מסווגים לפי charLang) או קבוצות של סימני פיסוק/רווח tokenize :: String -> [Token] tokenize "" = [] tokenize s@(c:_) | isAlpha c = let (letters, rest) = span (\ch -> isAlpha ch && charLang ch == charLang c) s in Letter letters (fromMaybe "" (charLang c)) : tokenize rest | otherwise = let (punct, rest) = break isAlpha s in Punct punct : tokenize rest ------------------------------------------------------------ -- מצב סגמנטציה: בשיטה זו נבצע הקצאה מחדש של סימני פיסוק בגבולות בלוקים. -- במצב SegHebrew – target היא "Hebrew" -- במצב SegEnglish – target היא "English" data SegMode = SegHebrew | SegEnglish deriving (Eq, Show) -- עוזרת: האם שפה נתונה היא target בהתאם למצב הסגמנטציה isTarget :: SegMode -> String -> Bool isTarget SegHebrew l = l == "Hebrew" isTarget SegEnglish l = l == "English" -- נרצה לאסוף טוקנים לכדי בלוקים (מחרוזות) כך שהטוקנים המקוריים לא ישתנו, -- אך סימני הפיסוק שבגבולות יועברו בהתאם לכלל הבא: -- -- נניח שיש לנו גבול בין טוקן אות (T_prev) לטוקן אות (T_next) עם טוקני פיסוק ביניהם (PunctSeq). -- אז: -- • אם T_prev ו–T_next שונות בשייכות target, נחלק את PunctSeq לשניים: -- - במצב SegHebrew (target = Hebrew): אם T_prev הוא target (Hebrew) ו–T_next אינו, נרצה שהתוצאה תהיה: -- בלוק target: T_prev בלבד, -- בלוק non-target: (PunctSeq עם הסימן האחרון מופיע בסופו) <> T_next... -- - במצב SegEnglish (target = English): אם T_prev אינו target וה–T_next הוא target, אזי -- בלוק non-target: T_prev <> (PunctSeq עם הסימן הראשון בסופו), -- בלוק target: T_next... -- • במקרים בהם שני הטוקנים הם מאותה קטגוריה – פשוט מצרפים את הפיסוק לטוקן הקודם. -- -- בפועל, נממש פונקציה שמסכמת את רשימת הטוקנים ומעבירה את סימני הפיסוק בהתאם. reassemble :: SegMode -> [Token] -> [String] reassemble mode toks = mergeBlocks (assignPunct mode toks) where -- assignPunct מעבירה סימני פיסוק בגבולות לפי הכלל הפשוט הבא: assignPunct :: SegMode -> [Token] -> [Token] assignPunct _ [] = [] assignPunct _ [t] = [t] assignPunct m (t1 : Punct punc : t2 : rest) = case (t1, t2) of (Letter _ l1, Letter _ l2) | isTarget m l1 || isTarget m l2 -> -- במקרה של גבול target–non-target if isTarget m l1 && not (isTarget m l2) then -- במצב SegHebrew: אם הטוקן השמאלי הוא target, העבר את כל הפיסוק לבלוק הימני t1 : assignPunct m (Letter punc l2 : t2 : rest) else if not (isTarget m l1) && isTarget m l2 then -- במצב SegEnglish: אם הטוקן הימני הוא target, העבר את כל הפיסוק לבלוק השמאלי let newT1 = Letter (content t1 ++ punc) l1 in newT1 : assignPunct m (t2 : rest) else -- אם שני הצדדים target או שניהם non-target – צרף לפסיק ל-T_prev let newT1 = Letter (content t1 ++ punc) (lang t1) in newT1 : assignPunct m (t2 : rest) _ -> t1 : assignPunct m (Punct punc : t2 : rest) assignPunct m (t:rest) = t : assignPunct m rest -- mergeBlocks פשוט ממזג טוקנים עוקבים לשרשרת אחת (מבוסס על content) mergeBlocks :: [Token] -> [String] mergeBlocks [] = [] mergeBlocks (t:ts) = let (grp, rest) = span (sameType t) ts block = concatMap content (t:grp) in block : mergeBlocks rest where sameType :: Token -> Token -> Bool sameType (Letter _ l1) (Letter _ l2) = l1 == l2 sameType (Punct _) (Punct _) = True -- לא ממזג בין אות לפיסוק sameType _ _ = False ------------------------------------------------------------ -- פונקציות עיבוד טקסט: -- -- במצב all: -- 1. הופכים את כל הטקסט (reverse) -- 2. מפצלים לבלוקים בעזרת reassemble במצב SegEnglish -- 3. בתוך הרשימה, בלוקים ששייכים לאנגלית (target במצב SegEnglish) חוזרים הפיכה כדי לשחזר את הסדר המקורי. processAll :: String -> String processAll s = let revText = reverse s toks = tokenize revText blocks = reassemble SegEnglish toks fixed = map (\blk -> if any isEnglish blk then reverse blk else blk) blocks in concat fixed -- במצב blocks: -- מפצלים לבלוקים בעזרת reassemble במצב SegHebrew -- ואז הופכים רק את הבלוקים בהם מופיעות אותיות בעברית. processBlocks :: String -> String processBlocks s = let toks = tokenize s blocks = reassemble SegHebrew toks fixed = map (\blk -> if any isHebrew blk then reverse blk else blk) blocks in concat fixed -- Add helper function to remove invisible characters. removeInvisible :: String -> String removeInvisible = filter (\c -> c /= '\x200F' && c /= '\x202B') main :: IO () main = do args <- getArgs when (length args >= 2) $ do let (flag:rest) = args txt = removeInvisible $ unwords rest -- remove invisible characters from input case flag of "-a" -> putStrLn $ processAll txt "-b" -> putStrLn $ processBlocks txt _ -> return ()@נ-נח זה ממש ממש מוצלח!
רק הצעה חשובה לשיפור
את ה-rev היה אפשר להכניס אחרי שורת פעולה לביצוע וכך תוצאת השורה היתה מודפסת כראויmove "123.txt" "פנימי" |rev move "456.txt" "פנימי" |hecho -bייתן את התוצאה
C:\Users\user\Downloads>move "123.txt" "פנימי" | rev .devom )s(elif 1 C:\Users\user\Downloads>move "456.txt" "פנימי" | hecho -b - היפוך כל הסדר של הטקסט (עם הארגומנט
-
@נ-נח זה ממש ממש מוצלח!
רק הצעה חשובה לשיפור
את ה-rev היה אפשר להכניס אחרי שורת פעולה לביצוע וכך תוצאת השורה היתה מודפסת כראויmove "123.txt" "פנימי" |rev move "456.txt" "פנימי" |hecho -bייתן את התוצאה
C:\Users\user\Downloads>move "123.txt" "פנימי" | rev .devom )s(elif 1 C:\Users\user\Downloads>move "456.txt" "פנימי" | hecho -b -
-
@מתלמד-צעיר כתב בבירור | תגובה: איך לעשות שCMD יכתוב בעברית:
@נ-נח גוגל החל לזהות את זה כתוכנה חשודה
אצלי לא. אולי זה קשור לאנטיוירוס שלך (לי יש רק defender)
בכל אופן, תיקנתי את התוכנה, ועכשיו זה עובד טוב גם על כמה שורות
אפשר לדוגמא לקרוא מקובץ עם כמה שורותtype file.txt | hecho -ahecho.rar סיסמא: 123
אתה יכול כמובן לשנות את השם של התוכנה לrev אם אתה מעדיףהקוד
import System.Environment (getArgs) import Control.Monad (when) import Data.Char (isAlpha, isAsciiLower, isAsciiUpper, isSpace, isPrint) import Data.Maybe (fromMaybe) -- הגדרות לסיווג תו לפי שפה isHebrew :: Char -> Bool isHebrew c = c >= 'א' && c <= 'ת' isEnglish :: Char -> Bool isEnglish c = isAsciiLower c || isAsciiUpper c -- מחזירה Just "Hebrew" או Just "English" עבור אות, או Nothing עבור סימן פיסוק/רווח charLang :: Char -> Maybe String charLang c | isHebrew c = Just "Hebrew" | isEnglish c = Just "English" | otherwise = Nothing ------------------------------------------------------------ -- טיפוסי טוקנים: טוקן אות – כולל מחרוזת ותווית שפה; -- טוקן פיסוק/רווח data Token = Letter { content :: String, lang :: String } | Punct { content :: String } deriving (Show) -- פונקציה שמפצלת מחרוזת לרשימת טוקנים: -- קבוצות רציפות של אותיות (אותן מסווגים לפי charLang) או קבוצות של סימני פיסוק/רווח tokenize :: String -> [Token] tokenize "" = [] tokenize s@(c:_) | isAlpha c = let (letters, rest) = span (\ch -> isAlpha ch && charLang ch == charLang c) s in Letter letters (fromMaybe "" (charLang c)) : tokenize rest | otherwise = let (punct, rest) = break isAlpha s in Punct punct : tokenize rest ------------------------------------------------------------ -- מצב סגמנטציה: בשיטה זו נבצע הקצאה מחדש של סימני פיסוק בגבולות בלוקים. -- במצב SegHebrew – target היא "Hebrew" -- במצב SegEnglish – target היא "English" data SegMode = SegHebrew | SegEnglish deriving (Eq, Show) -- עוזרת: האם שפה נתונה היא target בהתאם למצב הסגמנטציה isTarget :: SegMode -> String -> Bool isTarget SegHebrew l = l == "Hebrew" isTarget SegEnglish l = l == "English" -- נרצה לאסוף טוקנים לכדי בלוקים (מחרוזות) כך שהטוקנים המקוריים לא ישתנו, -- אך סימני הפיסוק שבגבולות יועברו בהתאם לכלל הבא: -- -- נניח שיש לנו גבול בין טוקן אות (T_prev) לטוקן אות (T_next) עם טוקני פיסוק ביניהם (PunctSeq). -- אז: -- • אם T_prev ו–T_next שונות בשייכות target, נחלק את PunctSeq לשניים: -- - במצב SegHebrew (target = Hebrew): אם T_prev הוא target (Hebrew) ו–T_next אינו, נרצה שהתוצאה תהיה: -- בלוק target: T_prev בלבד, -- בלוק non-target: (PunctSeq עם הסימן האחרון מופיע בסופו) <> T_next... -- - במצב SegEnglish (target = English): אם T_prev אינו target וה–T_next הוא target, אזי -- בלוק non-target: T_prev <> (PunctSeq עם הסימן הראשון בסופו), -- בלוק target: T_next... -- • במקרים בהם שני הטוקנים הם מאותה קטגוריה – פשוט מצרפים את הפיסוק לטוקן הקודם. -- -- בפועל, נממש פונקציה שמסכמת את רשימת הטוקנים ומעבירה את סימני הפיסוק בהתאם. reassemble :: SegMode -> [Token] -> [String] reassemble mode toks = mergeBlocks (assignPunct mode toks) where -- assignPunct מעבירה סימני פיסוק בגבולות לפי הכלל הפשוט הבא: assignPunct :: SegMode -> [Token] -> [Token] assignPunct _ [] = [] assignPunct _ [t] = [t] assignPunct m (t1 : Punct punc : t2 : rest) = case (t1, t2) of (Letter _ l1, Letter _ l2) | isTarget m l1 || isTarget m l2 -> -- במקרה של גבול target–non-target if isTarget m l1 && not (isTarget m l2) then -- במצב SegHebrew: אם הטוקן השמאלי הוא target, העבר את כל הפיסוק לבלוק הימני t1 : assignPunct m (Letter punc l2 : t2 : rest) else if not (isTarget m l1) && isTarget m l2 then -- במצב SegEnglish: אם הטוקן הימני הוא target, העבר את כל הפיסוק לבלוק השמאלי let newT1 = Letter (content t1 ++ punc) l1 in newT1 : assignPunct m (t2 : rest) else -- אם שני הצדדים target או שניהם non-target – צרף לפסיק ל-T_prev let newT1 = Letter (content t1 ++ punc) (lang t1) in newT1 : assignPunct m (t2 : rest) _ -> t1 : assignPunct m (Punct punc : t2 : rest) assignPunct m (t:rest) = t : assignPunct m rest -- mergeBlocks פשוט ממזג טוקנים עוקבים לשרשרת אחת (מבוסס על content) mergeBlocks :: [Token] -> [String] mergeBlocks [] = [] mergeBlocks (t:ts) = let (grp, rest) = span (sameType t) ts block = concatMap content (t:grp) in block : mergeBlocks rest where sameType :: Token -> Token -> Bool sameType (Letter _ l1) (Letter _ l2) = l1 == l2 sameType (Punct _) (Punct _) = True -- לא ממזג בין אות לפיסוק sameType _ _ = False ------------------------------------------------------------ -- פונקציות עיבוד טקסט: -- -- במצב all: -- 1. הופכים את כל הטקסט (reverse) -- 2. מפצלים לבלוקים בעזרת reassemble במצב SegEnglish -- 3. בתוך הרשימה, בלוקים ששייכים לאנגלית (target במצב SegEnglish) חוזרים הפיכה כדי לשחזר את הסדר המקורי. processAll :: String -> String processAll s = let revText = reverse s toks = tokenize revText blocks = reassemble SegEnglish toks fixed = map (\blk -> if any isEnglish blk then reverse blk else blk) blocks in concat fixed -- במצב blocks: -- מפצלים לבלוקים בעזרת reassemble במצב SegHebrew -- ואז הופכים רק את הבלוקים בהם מופיעות אותיות בעברית. processBlocks :: String -> String processBlocks s = let toks = tokenize s blocks = reassemble SegHebrew toks fixed = map (\blk -> if any isHebrew blk then reverse blk else blk) blocks in concat fixed -- Add helper function to remove invisible characters. removeInvisible :: String -> String removeInvisible = filter (\c -> isPrint c || isSpace c) -- Add helper function to trim whitespace. trim :: String -> String trim = f . f where f = reverse . dropWhile isSpace main :: IO () main = do args <- getArgs input <- if length args < 2 then getContents -- use piped input if no text argument is provided else return $ unwords $ tail args let txt = trim $ removeInvisible input -- remove invisible characters then trim whitespace flag = if null args then "" else head args case flag of "-a" -> putStr $ unlines $ map processAll $ lines txt "-b" -> putStr $ unlines $ map processBlocks $ lines txt _ -> return () -
@מתלמד-צעיר כתב בבירור | תגובה: איך לעשות שCMD יכתוב בעברית:
@נ-נח גוגל החל לזהות את זה כתוכנה חשודה
אצלי לא. אולי זה קשור לאנטיוירוס שלך (לי יש רק defender)
בכל אופן, תיקנתי את התוכנה, ועכשיו זה עובד טוב גם על כמה שורות
אפשר לדוגמא לקרוא מקובץ עם כמה שורותtype file.txt | hecho -ahecho.rar סיסמא: 123
אתה יכול כמובן לשנות את השם של התוכנה לrev אם אתה מעדיףהקוד
import System.Environment (getArgs) import Control.Monad (when) import Data.Char (isAlpha, isAsciiLower, isAsciiUpper, isSpace, isPrint) import Data.Maybe (fromMaybe) -- הגדרות לסיווג תו לפי שפה isHebrew :: Char -> Bool isHebrew c = c >= 'א' && c <= 'ת' isEnglish :: Char -> Bool isEnglish c = isAsciiLower c || isAsciiUpper c -- מחזירה Just "Hebrew" או Just "English" עבור אות, או Nothing עבור סימן פיסוק/רווח charLang :: Char -> Maybe String charLang c | isHebrew c = Just "Hebrew" | isEnglish c = Just "English" | otherwise = Nothing ------------------------------------------------------------ -- טיפוסי טוקנים: טוקן אות – כולל מחרוזת ותווית שפה; -- טוקן פיסוק/רווח data Token = Letter { content :: String, lang :: String } | Punct { content :: String } deriving (Show) -- פונקציה שמפצלת מחרוזת לרשימת טוקנים: -- קבוצות רציפות של אותיות (אותן מסווגים לפי charLang) או קבוצות של סימני פיסוק/רווח tokenize :: String -> [Token] tokenize "" = [] tokenize s@(c:_) | isAlpha c = let (letters, rest) = span (\ch -> isAlpha ch && charLang ch == charLang c) s in Letter letters (fromMaybe "" (charLang c)) : tokenize rest | otherwise = let (punct, rest) = break isAlpha s in Punct punct : tokenize rest ------------------------------------------------------------ -- מצב סגמנטציה: בשיטה זו נבצע הקצאה מחדש של סימני פיסוק בגבולות בלוקים. -- במצב SegHebrew – target היא "Hebrew" -- במצב SegEnglish – target היא "English" data SegMode = SegHebrew | SegEnglish deriving (Eq, Show) -- עוזרת: האם שפה נתונה היא target בהתאם למצב הסגמנטציה isTarget :: SegMode -> String -> Bool isTarget SegHebrew l = l == "Hebrew" isTarget SegEnglish l = l == "English" -- נרצה לאסוף טוקנים לכדי בלוקים (מחרוזות) כך שהטוקנים המקוריים לא ישתנו, -- אך סימני הפיסוק שבגבולות יועברו בהתאם לכלל הבא: -- -- נניח שיש לנו גבול בין טוקן אות (T_prev) לטוקן אות (T_next) עם טוקני פיסוק ביניהם (PunctSeq). -- אז: -- • אם T_prev ו–T_next שונות בשייכות target, נחלק את PunctSeq לשניים: -- - במצב SegHebrew (target = Hebrew): אם T_prev הוא target (Hebrew) ו–T_next אינו, נרצה שהתוצאה תהיה: -- בלוק target: T_prev בלבד, -- בלוק non-target: (PunctSeq עם הסימן האחרון מופיע בסופו) <> T_next... -- - במצב SegEnglish (target = English): אם T_prev אינו target וה–T_next הוא target, אזי -- בלוק non-target: T_prev <> (PunctSeq עם הסימן הראשון בסופו), -- בלוק target: T_next... -- • במקרים בהם שני הטוקנים הם מאותה קטגוריה – פשוט מצרפים את הפיסוק לטוקן הקודם. -- -- בפועל, נממש פונקציה שמסכמת את רשימת הטוקנים ומעבירה את סימני הפיסוק בהתאם. reassemble :: SegMode -> [Token] -> [String] reassemble mode toks = mergeBlocks (assignPunct mode toks) where -- assignPunct מעבירה סימני פיסוק בגבולות לפי הכלל הפשוט הבא: assignPunct :: SegMode -> [Token] -> [Token] assignPunct _ [] = [] assignPunct _ [t] = [t] assignPunct m (t1 : Punct punc : t2 : rest) = case (t1, t2) of (Letter _ l1, Letter _ l2) | isTarget m l1 || isTarget m l2 -> -- במקרה של גבול target–non-target if isTarget m l1 && not (isTarget m l2) then -- במצב SegHebrew: אם הטוקן השמאלי הוא target, העבר את כל הפיסוק לבלוק הימני t1 : assignPunct m (Letter punc l2 : t2 : rest) else if not (isTarget m l1) && isTarget m l2 then -- במצב SegEnglish: אם הטוקן הימני הוא target, העבר את כל הפיסוק לבלוק השמאלי let newT1 = Letter (content t1 ++ punc) l1 in newT1 : assignPunct m (t2 : rest) else -- אם שני הצדדים target או שניהם non-target – צרף לפסיק ל-T_prev let newT1 = Letter (content t1 ++ punc) (lang t1) in newT1 : assignPunct m (t2 : rest) _ -> t1 : assignPunct m (Punct punc : t2 : rest) assignPunct m (t:rest) = t : assignPunct m rest -- mergeBlocks פשוט ממזג טוקנים עוקבים לשרשרת אחת (מבוסס על content) mergeBlocks :: [Token] -> [String] mergeBlocks [] = [] mergeBlocks (t:ts) = let (grp, rest) = span (sameType t) ts block = concatMap content (t:grp) in block : mergeBlocks rest where sameType :: Token -> Token -> Bool sameType (Letter _ l1) (Letter _ l2) = l1 == l2 sameType (Punct _) (Punct _) = True -- לא ממזג בין אות לפיסוק sameType _ _ = False ------------------------------------------------------------ -- פונקציות עיבוד טקסט: -- -- במצב all: -- 1. הופכים את כל הטקסט (reverse) -- 2. מפצלים לבלוקים בעזרת reassemble במצב SegEnglish -- 3. בתוך הרשימה, בלוקים ששייכים לאנגלית (target במצב SegEnglish) חוזרים הפיכה כדי לשחזר את הסדר המקורי. processAll :: String -> String processAll s = let revText = reverse s toks = tokenize revText blocks = reassemble SegEnglish toks fixed = map (\blk -> if any isEnglish blk then reverse blk else blk) blocks in concat fixed -- במצב blocks: -- מפצלים לבלוקים בעזרת reassemble במצב SegHebrew -- ואז הופכים רק את הבלוקים בהם מופיעות אותיות בעברית. processBlocks :: String -> String processBlocks s = let toks = tokenize s blocks = reassemble SegHebrew toks fixed = map (\blk -> if any isHebrew blk then reverse blk else blk) blocks in concat fixed -- Add helper function to remove invisible characters. removeInvisible :: String -> String removeInvisible = filter (\c -> isPrint c || isSpace c) -- Add helper function to trim whitespace. trim :: String -> String trim = f . f where f = reverse . dropWhile isSpace main :: IO () main = do args <- getArgs input <- if length args < 2 then getContents -- use piped input if no text argument is provided else return $ unwords $ tail args let txt = trim $ removeInvisible input -- remove invisible characters then trim whitespace flag = if null args then "" else head args case flag of "-a" -> putStr $ unlines $ map processAll $ lines txt "-b" -> putStr $ unlines $ map processBlocks $ lines txt _ -> return ()@נ-נח תודה ענקית!
כזה דבר עוד לא ראיתי
ואז
אחרי שהזנתי את הסיסמא הקובץ ירד חלק... -
@מתלמד-צעיר כתב בבירור | תגובה: איך לעשות שCMD יכתוב בעברית:
@נ-נח גוגל החל לזהות את זה כתוכנה חשודה
אצלי לא. אולי זה קשור לאנטיוירוס שלך (לי יש רק defender)
בכל אופן, תיקנתי את התוכנה, ועכשיו זה עובד טוב גם על כמה שורות
אפשר לדוגמא לקרוא מקובץ עם כמה שורותtype file.txt | hecho -ahecho.rar סיסמא: 123
אתה יכול כמובן לשנות את השם של התוכנה לrev אם אתה מעדיףהקוד
import System.Environment (getArgs) import Control.Monad (when) import Data.Char (isAlpha, isAsciiLower, isAsciiUpper, isSpace, isPrint) import Data.Maybe (fromMaybe) -- הגדרות לסיווג תו לפי שפה isHebrew :: Char -> Bool isHebrew c = c >= 'א' && c <= 'ת' isEnglish :: Char -> Bool isEnglish c = isAsciiLower c || isAsciiUpper c -- מחזירה Just "Hebrew" או Just "English" עבור אות, או Nothing עבור סימן פיסוק/רווח charLang :: Char -> Maybe String charLang c | isHebrew c = Just "Hebrew" | isEnglish c = Just "English" | otherwise = Nothing ------------------------------------------------------------ -- טיפוסי טוקנים: טוקן אות – כולל מחרוזת ותווית שפה; -- טוקן פיסוק/רווח data Token = Letter { content :: String, lang :: String } | Punct { content :: String } deriving (Show) -- פונקציה שמפצלת מחרוזת לרשימת טוקנים: -- קבוצות רציפות של אותיות (אותן מסווגים לפי charLang) או קבוצות של סימני פיסוק/רווח tokenize :: String -> [Token] tokenize "" = [] tokenize s@(c:_) | isAlpha c = let (letters, rest) = span (\ch -> isAlpha ch && charLang ch == charLang c) s in Letter letters (fromMaybe "" (charLang c)) : tokenize rest | otherwise = let (punct, rest) = break isAlpha s in Punct punct : tokenize rest ------------------------------------------------------------ -- מצב סגמנטציה: בשיטה זו נבצע הקצאה מחדש של סימני פיסוק בגבולות בלוקים. -- במצב SegHebrew – target היא "Hebrew" -- במצב SegEnglish – target היא "English" data SegMode = SegHebrew | SegEnglish deriving (Eq, Show) -- עוזרת: האם שפה נתונה היא target בהתאם למצב הסגמנטציה isTarget :: SegMode -> String -> Bool isTarget SegHebrew l = l == "Hebrew" isTarget SegEnglish l = l == "English" -- נרצה לאסוף טוקנים לכדי בלוקים (מחרוזות) כך שהטוקנים המקוריים לא ישתנו, -- אך סימני הפיסוק שבגבולות יועברו בהתאם לכלל הבא: -- -- נניח שיש לנו גבול בין טוקן אות (T_prev) לטוקן אות (T_next) עם טוקני פיסוק ביניהם (PunctSeq). -- אז: -- • אם T_prev ו–T_next שונות בשייכות target, נחלק את PunctSeq לשניים: -- - במצב SegHebrew (target = Hebrew): אם T_prev הוא target (Hebrew) ו–T_next אינו, נרצה שהתוצאה תהיה: -- בלוק target: T_prev בלבד, -- בלוק non-target: (PunctSeq עם הסימן האחרון מופיע בסופו) <> T_next... -- - במצב SegEnglish (target = English): אם T_prev אינו target וה–T_next הוא target, אזי -- בלוק non-target: T_prev <> (PunctSeq עם הסימן הראשון בסופו), -- בלוק target: T_next... -- • במקרים בהם שני הטוקנים הם מאותה קטגוריה – פשוט מצרפים את הפיסוק לטוקן הקודם. -- -- בפועל, נממש פונקציה שמסכמת את רשימת הטוקנים ומעבירה את סימני הפיסוק בהתאם. reassemble :: SegMode -> [Token] -> [String] reassemble mode toks = mergeBlocks (assignPunct mode toks) where -- assignPunct מעבירה סימני פיסוק בגבולות לפי הכלל הפשוט הבא: assignPunct :: SegMode -> [Token] -> [Token] assignPunct _ [] = [] assignPunct _ [t] = [t] assignPunct m (t1 : Punct punc : t2 : rest) = case (t1, t2) of (Letter _ l1, Letter _ l2) | isTarget m l1 || isTarget m l2 -> -- במקרה של גבול target–non-target if isTarget m l1 && not (isTarget m l2) then -- במצב SegHebrew: אם הטוקן השמאלי הוא target, העבר את כל הפיסוק לבלוק הימני t1 : assignPunct m (Letter punc l2 : t2 : rest) else if not (isTarget m l1) && isTarget m l2 then -- במצב SegEnglish: אם הטוקן הימני הוא target, העבר את כל הפיסוק לבלוק השמאלי let newT1 = Letter (content t1 ++ punc) l1 in newT1 : assignPunct m (t2 : rest) else -- אם שני הצדדים target או שניהם non-target – צרף לפסיק ל-T_prev let newT1 = Letter (content t1 ++ punc) (lang t1) in newT1 : assignPunct m (t2 : rest) _ -> t1 : assignPunct m (Punct punc : t2 : rest) assignPunct m (t:rest) = t : assignPunct m rest -- mergeBlocks פשוט ממזג טוקנים עוקבים לשרשרת אחת (מבוסס על content) mergeBlocks :: [Token] -> [String] mergeBlocks [] = [] mergeBlocks (t:ts) = let (grp, rest) = span (sameType t) ts block = concatMap content (t:grp) in block : mergeBlocks rest where sameType :: Token -> Token -> Bool sameType (Letter _ l1) (Letter _ l2) = l1 == l2 sameType (Punct _) (Punct _) = True -- לא ממזג בין אות לפיסוק sameType _ _ = False ------------------------------------------------------------ -- פונקציות עיבוד טקסט: -- -- במצב all: -- 1. הופכים את כל הטקסט (reverse) -- 2. מפצלים לבלוקים בעזרת reassemble במצב SegEnglish -- 3. בתוך הרשימה, בלוקים ששייכים לאנגלית (target במצב SegEnglish) חוזרים הפיכה כדי לשחזר את הסדר המקורי. processAll :: String -> String processAll s = let revText = reverse s toks = tokenize revText blocks = reassemble SegEnglish toks fixed = map (\blk -> if any isEnglish blk then reverse blk else blk) blocks in concat fixed -- במצב blocks: -- מפצלים לבלוקים בעזרת reassemble במצב SegHebrew -- ואז הופכים רק את הבלוקים בהם מופיעות אותיות בעברית. processBlocks :: String -> String processBlocks s = let toks = tokenize s blocks = reassemble SegHebrew toks fixed = map (\blk -> if any isHebrew blk then reverse blk else blk) blocks in concat fixed -- Add helper function to remove invisible characters. removeInvisible :: String -> String removeInvisible = filter (\c -> isPrint c || isSpace c) -- Add helper function to trim whitespace. trim :: String -> String trim = f . f where f = reverse . dropWhile isSpace main :: IO () main = do args <- getArgs input <- if length args < 2 then getContents -- use piped input if no text argument is provided else return $ unwords $ tail args let txt = trim $ removeInvisible input -- remove invisible characters then trim whitespace flag = if null args then "" else head args case flag of "-a" -> putStr $ unlines $ map processAll $ lines txt "-b" -> putStr $ unlines $ map processBlocks $ lines txt _ -> return () -
@נ-נח ישנה עוד בעיה שאי אפשר להדפיס מקובץ PowerShell משא"כ ב-rev
powershell -ExecutionPolicy Bypass -File "script.ps1" |rev powershell -ExecutionPolicy Bypass -File "script.ps1" |hechoהשורה הראשונה תדפיס היטב והשניה לא תדפיס כלל
-
@מתלמד-צעיר תנסה עם ארגומנט:
powershell -ExecutionPolicy Bypass -File "script.ps1" |hecho -aאו
powershell -ExecutionPolicy Bypass -File "script.ps1" |hecho -b -
@נ-נח צודק טעות שלי
אפשר להציע לך עוד שיפור? -
@מתלמד-צעיר בוודאי!
-
@נ-נח הקוד מדפיס ככה

זה קריא וברור אבל...
-
@מתלמד-צעיר מה היה הקלט?
ובאיזה ארגומנט השתמשת, -a או -b?
הבעיה היא רק הגרשיים? -
@נ-נח
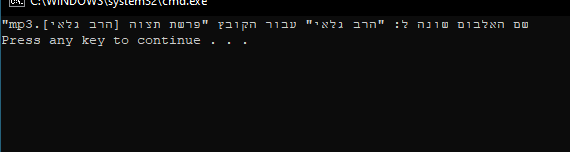
batpowershell -ExecutionPolicy Bypass -File "בדיקת שמות אלבום-הורדות.ps1" |hecho -bPowerShell
Write-Host "שם האלבום שונה ל: `"$newAlbumName`" עבור הקובץ `"$($file.Name)`""@מתלמד-צעיר
עכשיו התוכנה אמורה לפתור את זה
hecho.exepowershell -ExecutionPolicy Bypass -File "בדיקת שמות אלבום-הורדות.ps1" |hecho -a(התיקון הוא למקרה הספציפי הזה, ואולי במצבים אחרים זה רק יקלקל...)
-
@מתלמד-צעיר
עכשיו התוכנה אמורה לפתור את זה
hecho.exepowershell -ExecutionPolicy Bypass -File "בדיקת שמות אלבום-הורדות.ps1" |hecho -a(התיקון הוא למקרה הספציפי הזה, ואולי במצבים אחרים זה רק יקלקל...)
@נ-נח כתב בבירור | תגובה: איך לעשות שCMD יכתוב בעברית:
עכשיו התוכנה אמורה לפתור את זה
מתנצל שאני נכנס באמצע....
מה התוכנה פותרת? היא נותנת לראות את הCMD נורמלי? או שלא הבנתי כלום?גאה להיות חלק:
otzaria.org -
@נ-נח כתב בבירור | תגובה: איך לעשות שCMD יכתוב בעברית:
עכשיו התוכנה אמורה לפתור את זה
מתנצל שאני נכנס באמצע....
מה התוכנה פותרת? היא נותנת לראות את הCMD נורמלי? או שלא הבנתי כלום? -
@מתלמד-צעיר
עכשיו התוכנה אמורה לפתור את זה
hecho.exepowershell -ExecutionPolicy Bypass -File "בדיקת שמות אלבום-הורדות.ps1" |hecho -a(התיקון הוא למקרה הספציפי הזה, ואולי במצבים אחרים זה רק יקלקל...)
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}