בירור | שמירת סיפור מהאינטרנט לקובץ pdf
-
@משה-שמחה כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@הייתי-שמח-להבין
תודה רבה על הטרחה והמאמץ אם תוכל לערוך את הכל לקובץ pdf ולהעלות בצורה שלא יחסם בנטפרי זה מאוד יעזור.https://drive.google.com/******file/d/1Feg5cgVR-NISKegPONmc7LU1H1icWSBQ/view?usp=sharing
זה קישור לקובץ PDF של 20 העמודים הראשונים בדרייב, ניתן להורדה, להסיר כוכביות מהקישור, אם עדיין יש צורך לערוך עוד תכתוב לי.@הייתי-שמח-להבין איך עשית?
-
@הייתי-שמח-להבין איך עשית?
-
@נחמן-פלח הדפסתי ל-PDF עמוד עמוד, ומיזגתי את הכל לקובץ אחד.
@הייתי-שמח-להבין אתה צריך לשמוח.
למה?! כי השם משתמש זה הייתי שמח להבין והבנת!! ואם הבנת גם את זה אז תשמח עוד יותר -
@משה-שמחה כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@הייתי-שמח-להבין
תודה רבה על הטרחה והמאמץ אם תוכל לערוך את הכל לקובץ pdf ולהעלות בצורה שלא יחסם בנטפרי זה מאוד יעזור.https://drive.google.com/******file/d/1Feg5cgVR-NISKegPONmc7LU1H1icWSBQ/view?usp=sharing
זה קישור לקובץ PDF של 20 העמודים הראשונים בדרייב, ניתן להורדה, להסיר כוכביות מהקישור, אם עדיין יש צורך לערוך עוד תכתוב לי.@הייתי-שמח-להבין כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@משה-שמחה כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@הייתי-שמח-להבין
תודה רבה על הטרחה והמאמץ אם תוכל לערוך את הכל לקובץ pdf ולהעלות בצורה שלא יחסם בנטפרי זה מאוד יעזור.ערכתי בינתיים 2 קבצי PDF המכילים כל אחד 20 עמודים, העליתי אותם לדרייב, והם ניתנים להורדה.
קובץ 1- https://drive.google.com/******file/d/1Feg5cgVR-NISKegPONmc7LU1H1icWSBQ/view?usp=sharing
קובץ 2- https://drive.google.com/file/d/******1sXbURp416YW62Bc_3XEmMbw-7feSRh6m/view?usp=sharing
להסיר כוכביות מהקישורים, אם עדיין יש צורך לערוך עוד תכתוב לי. -
@הייתי-שמח-להבין כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@משה-שמחה כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@הייתי-שמח-להבין
תודה רבה על הטרחה והמאמץ אם תוכל לערוך את הכל לקובץ pdf ולהעלות בצורה שלא יחסם בנטפרי זה מאוד יעזור.ערכתי בינתיים 2 קבצי PDF המכילים כל אחד 20 עמודים, העליתי אותם לדרייב, והם ניתנים להורדה.
קובץ 1- https://drive.google.com/******file/d/1Feg5cgVR-NISKegPONmc7LU1H1icWSBQ/view?usp=sharing
קובץ 2- https://drive.google.com/file/d/******1sXbURp416YW62Bc_3XEmMbw-7feSRh6m/view?usp=sharing
להסיר כוכביות מהקישורים, אם עדיין יש צורך לערוך עוד תכתוב לי.@הייתי-שמח-להבין הנה קוד שיעשה במקומך את כל העבודה:
from base64 import b64decode import os import time from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.print_page_options import PrintOptions, Orientation # some tweaks to bypass bot detection options = webdriver.ChromeOptions() options.add_experimental_option("excludeSwitches", ["enable-automation"]) options.add_experimental_option('useAutomationExtension', False) options.add_argument("--disable-blink-features=AutomationControlled") options.page_load_strategy = 'normal' options.headless = True # initialise webdriver driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=options) #driver = webdriver.Chr for i in range(1,123): driver.get("https://online.fliphtml5.com/nejge/kkyl/#p="+str(i)) time.sleep(1) #save the page to disk printOptions = PrintOptions() printOptions.orientation="landscape" open(str(i)+".pdf", "wb").write(b64decode(driver.print_page(printOptions))) # after scraping all pages, merge them with pypdf from pypdf import PdfMerger files = os.listdir() pdfs = [s for s in files if '.pdf' in s] #sorting the file names by number - not alphabethic def forSorting(s)->int: s=s.split('.')[0] return int(s) pdfs.sort(key=forSorting) merger = PdfMerger() for pdf in pdfs: merger.append(pdf) merger.write("result.pdf") merger.close()והוא אכן עשה את העבודה, הנה התוצאה:
result.pdf
שים לב, @משה-שמחה
אז נעים להכיר את סלניום, מלך הבוטים... -
@הייתי-שמח-להבין כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@משה-שמחה כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@הייתי-שמח-להבין
תודה רבה על הטרחה והמאמץ אם תוכל לערוך את הכל לקובץ pdf ולהעלות בצורה שלא יחסם בנטפרי זה מאוד יעזור.ערכתי בינתיים 2 קבצי PDF המכילים כל אחד 20 עמודים, העליתי אותם לדרייב, והם ניתנים להורדה.
קובץ 1- https://drive.google.com/******file/d/1Feg5cgVR-NISKegPONmc7LU1H1icWSBQ/view?usp=sharing
קובץ 2- https://drive.google.com/file/d/******1sXbURp416YW62Bc_3XEmMbw-7feSRh6m/view?usp=sharing
להסיר כוכביות מהקישורים, אם עדיין יש צורך לערוך עוד תכתוב לי.@הייתי-שמח-להבין כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
ערכתי בינתיים 2 קבצי PDF המכילים כל אחד 20 עמודים, העליתי אותם לדרייב, והם ניתנים להורדה.
תודה רבה, עכשיו אני יהיה באמצע המתח.
@sivan22 כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
והוא אכן עשה את העבודה, הנה התוצאה:
result.pdfבינתיים חסום בנטפרי, שלחתי בקשה לבדיקה.
-
@הייתי-שמח-להבין הנה קוד שיעשה במקומך את כל העבודה:
from base64 import b64decode import os import time from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.print_page_options import PrintOptions, Orientation # some tweaks to bypass bot detection options = webdriver.ChromeOptions() options.add_experimental_option("excludeSwitches", ["enable-automation"]) options.add_experimental_option('useAutomationExtension', False) options.add_argument("--disable-blink-features=AutomationControlled") options.page_load_strategy = 'normal' options.headless = True # initialise webdriver driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=options) #driver = webdriver.Chr for i in range(1,123): driver.get("https://online.fliphtml5.com/nejge/kkyl/#p="+str(i)) time.sleep(1) #save the page to disk printOptions = PrintOptions() printOptions.orientation="landscape" open(str(i)+".pdf", "wb").write(b64decode(driver.print_page(printOptions))) # after scraping all pages, merge them with pypdf from pypdf import PdfMerger files = os.listdir() pdfs = [s for s in files if '.pdf' in s] #sorting the file names by number - not alphabethic def forSorting(s)->int: s=s.split('.')[0] return int(s) pdfs.sort(key=forSorting) merger = PdfMerger() for pdf in pdfs: merger.append(pdf) merger.write("result.pdf") merger.close()והוא אכן עשה את העבודה, הנה התוצאה:
result.pdf
שים לב, @משה-שמחה
אז נעים להכיר את סלניום, מלך הבוטים... -
@נחמן-פלח זה משתמש בכרום שלך, כדי לגלוש באינטרנט ולעשות כל דבר שיעלה בדעתך באמצעות קוד בפייתון (או בשפות אחרות).
תיעוד https://www.selenium.dev/documentation/webdriver/ -
@הייתי-שמח-להבין הנה קוד שיעשה במקומך את כל העבודה:
from base64 import b64decode import os import time from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.print_page_options import PrintOptions, Orientation # some tweaks to bypass bot detection options = webdriver.ChromeOptions() options.add_experimental_option("excludeSwitches", ["enable-automation"]) options.add_experimental_option('useAutomationExtension', False) options.add_argument("--disable-blink-features=AutomationControlled") options.page_load_strategy = 'normal' options.headless = True # initialise webdriver driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=options) #driver = webdriver.Chr for i in range(1,123): driver.get("https://online.fliphtml5.com/nejge/kkyl/#p="+str(i)) time.sleep(1) #save the page to disk printOptions = PrintOptions() printOptions.orientation="landscape" open(str(i)+".pdf", "wb").write(b64decode(driver.print_page(printOptions))) # after scraping all pages, merge them with pypdf from pypdf import PdfMerger files = os.listdir() pdfs = [s for s in files if '.pdf' in s] #sorting the file names by number - not alphabethic def forSorting(s)->int: s=s.split('.')[0] return int(s) pdfs.sort(key=forSorting) merger = PdfMerger() for pdf in pdfs: merger.append(pdf) merger.write("result.pdf") merger.close()והוא אכן עשה את העבודה, הנה התוצאה:
result.pdf
שים לב, @משה-שמחה
אז נעים להכיר את סלניום, מלך הבוטים...@sivan22 כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@הייתי-שמח-להבין הנה קוד שיעשה במקומך את כל העבודה:
from base64 import b64decode import os import time from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.print_page_options import PrintOptions, Orientation # some tweaks to bypass bot detection options = webdriver.ChromeOptions() options.add_experimental_option("excludeSwitches", ["enable-automation"]) options.add_experimental_option('useAutomationExtension', False) options.add_argument("--disable-blink-features=AutomationControlled") options.page_load_strategy = 'normal' options.headless = True # initialise webdriver driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=options) #driver = webdriver.Chr for i in range(1,123): driver.get("https://online.fliphtml5.com/nejge/kkyl/#p="+str(i)) time.sleep(1) #save the page to disk printOptions = PrintOptions() printOptions.orientation="landscape" open(str(i)+".pdf", "wb").write(b64decode(driver.print_page(printOptions))) # after scraping all pages, merge them with pypdf from pypdf import PdfMerger files = os.listdir() pdfs = [s for s in files if '.pdf' in s] #sorting the file names by number - not alphabethic def forSorting(s)->int: s=s.split('.')[0] return int(s) pdfs.sort(key=forSorting) merger = PdfMerger() for pdf in pdfs: merger.append(pdf) merger.write("result.pdf") merger.close()והוא אכן עשה את העבודה, הנה התוצאה:
result.pdf
שים לב, @משה-שמחה
אז נעים להכיר את סלניום, מלך הבוטים...אתה פשוט גאון, חבל שבאת רק עכשיו.
צריך בשביל להריץ את זה ספריית פייתון או משהו אחר? -
@sivan22 כתב בבירור | שמירת סיפור מהאינטרנט לקובץ pdf:
@הייתי-שמח-להבין הנה קוד שיעשה במקומך את כל העבודה:
from base64 import b64decode import os import time from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.print_page_options import PrintOptions, Orientation # some tweaks to bypass bot detection options = webdriver.ChromeOptions() options.add_experimental_option("excludeSwitches", ["enable-automation"]) options.add_experimental_option('useAutomationExtension', False) options.add_argument("--disable-blink-features=AutomationControlled") options.page_load_strategy = 'normal' options.headless = True # initialise webdriver driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=options) #driver = webdriver.Chr for i in range(1,123): driver.get("https://online.fliphtml5.com/nejge/kkyl/#p="+str(i)) time.sleep(1) #save the page to disk printOptions = PrintOptions() printOptions.orientation="landscape" open(str(i)+".pdf", "wb").write(b64decode(driver.print_page(printOptions))) # after scraping all pages, merge them with pypdf from pypdf import PdfMerger files = os.listdir() pdfs = [s for s in files if '.pdf' in s] #sorting the file names by number - not alphabethic def forSorting(s)->int: s=s.split('.')[0] return int(s) pdfs.sort(key=forSorting) merger = PdfMerger() for pdf in pdfs: merger.append(pdf) merger.write("result.pdf") merger.close()והוא אכן עשה את העבודה, הנה התוצאה:
result.pdf
שים לב, @משה-שמחה
אז נעים להכיר את סלניום, מלך הבוטים...אתה פשוט גאון, חבל שבאת רק עכשיו.
צריך בשביל להריץ את זה ספריית פייתון או משהו אחר?@הייתי-שמח-להבין @נחמן-פלח אני רואה שהתלהבתם, אז הנה דוגמה קטנה איך להשתמש בסלניום כדי לגלוש באתר מתמחים טופ.
ראשית יש להתקין פייתון כמובן. כדאי להקפיד לסמן בוי את האפשרות להגדיר PATH.
שנית יש להתקין את שתי הספריות הבאות:pip install selenium webdriver-managerהראשית היא סלניום - הספריה שנשתמש בה, והשני עוזר לנו להוריד ולהתקין אוטומטית את ה"דרייבר" - זהו בעצם החלק המקשר בין הקוד לבין הדפדפן.
נפתח קובץ פייתון חדש בשם surfMitmachimSelenium.py או כל שם מפוצץ אחר.
נתחיל בייבוא הספריות:
from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.by import Byאחר כך נוריד אוטומטית דרייבר לדפדפן כרום:
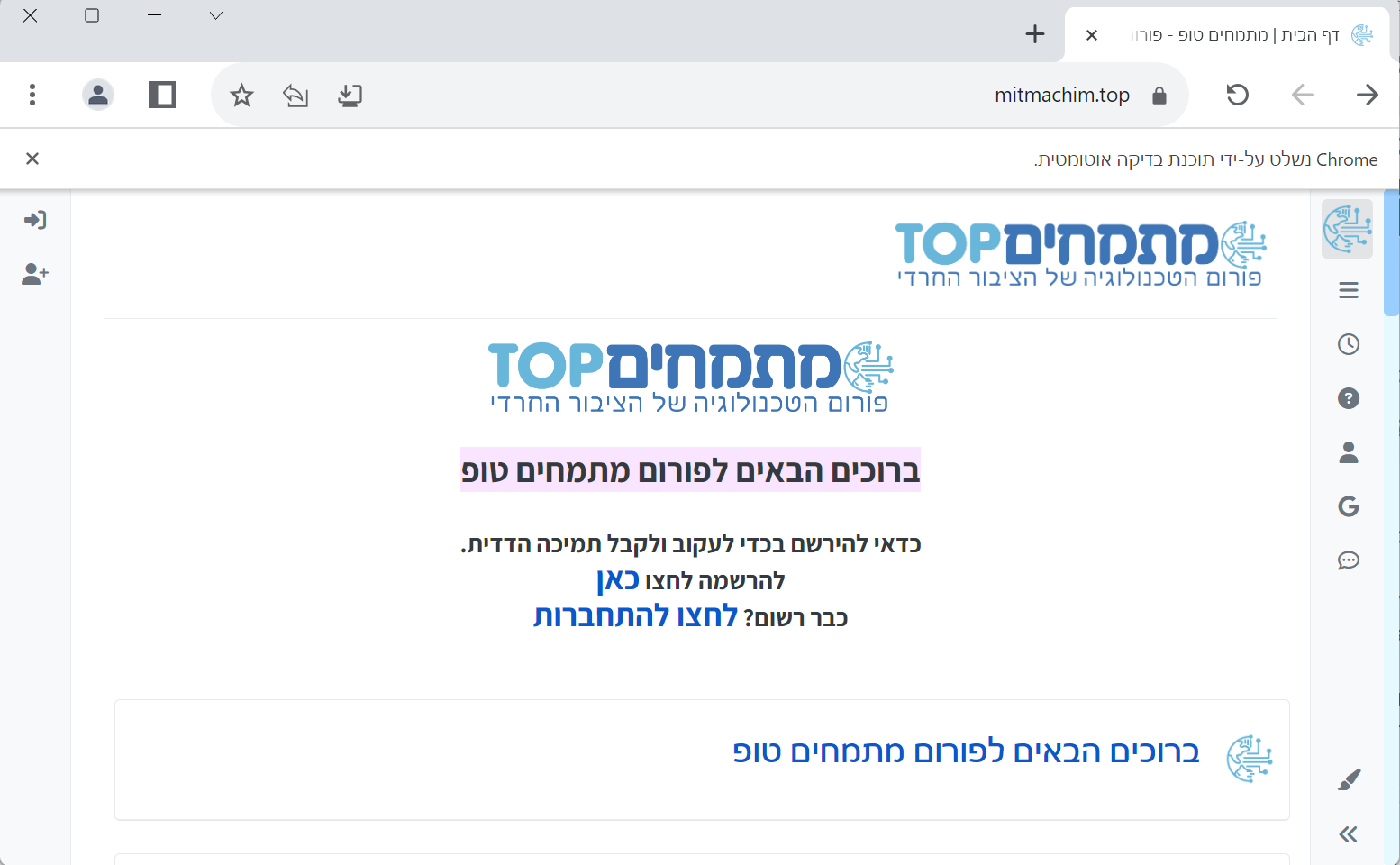
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))בתקווה שאין שגיאות (חסימה בנטפרי וכדו'), נמשיך לשורה הבאה: נגלוש באתר מתמחים.
driver.get("https://mitmachim.top/")כך נראה הדפדפן כרגע:
עכשיו דבר חשוב מאד: לפני שנלחץ על עוד אובייקט צריך לחכות לו ולא ללחוץ עליו לפני שהוא נטען. אז השורה הבאה נדרשת:
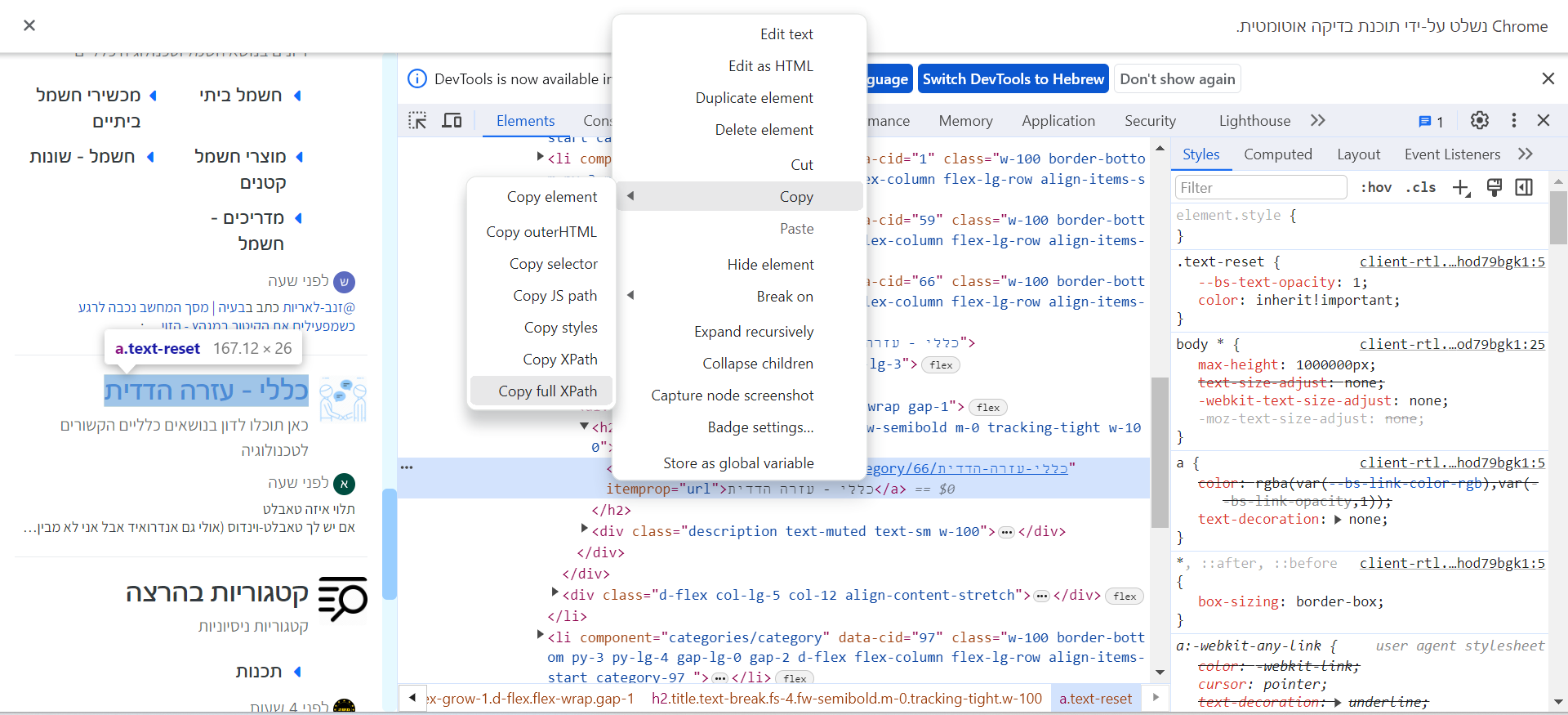
driver.implicitly_wait(2)אנחנו רוצים להיכנס לקטגוריה "כללי עזרה הדדית", אז אנחנו צריכים למצוא את הכתובת שלו במקור הדף בhtml.
אז כמובן לוחצים f12. לחיצה ימנית -> בדיקה ->לחיצה ימנית על הhtml -> העתק -> העתק נתיב xpath
צילום מסך:
יופי, עכשיו נמצא את האובייקט הדרוש לפי הכתובת שלו:
element = driver.find_element(By.XPATH,"/html/body/div[1]/main/div[2]/div/div[2]/div[1]/ul/li[9]/div[1]/div[2]/h2/a")נשים לב שהכתובת היא מה שהעתקנו מקודם.
נלחץ על השורה שמצאנו:element.click()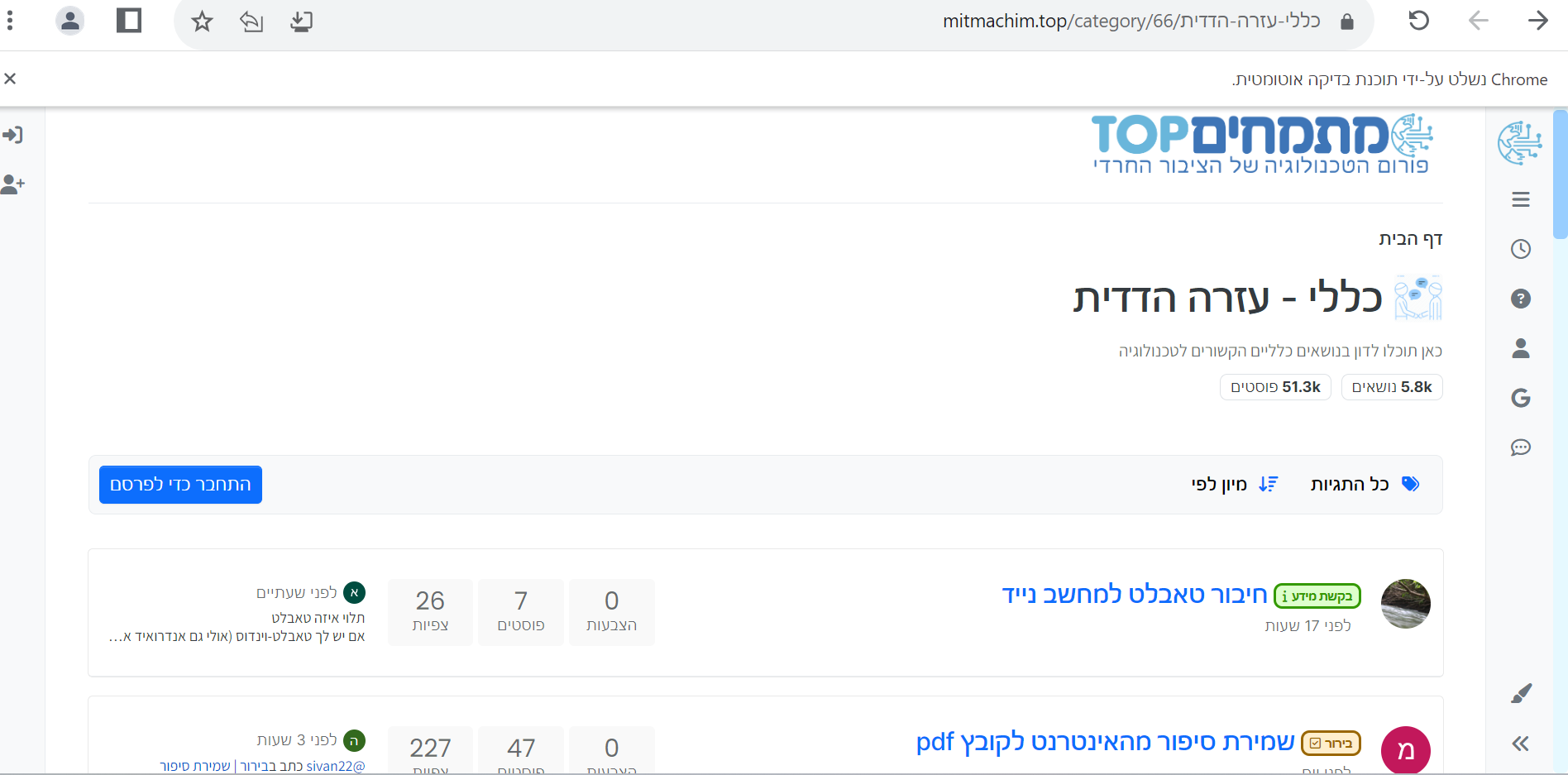
עכשיו נחפש אלמנט בדרך אחרת, לא לפי כתובת אלא לפי חלק מהמחרוזת המופיעה בלינק. ונלחץ עליו:
element = driver.find_element(By.PARTIAL_LINK_TEXT,"pdf") element.click()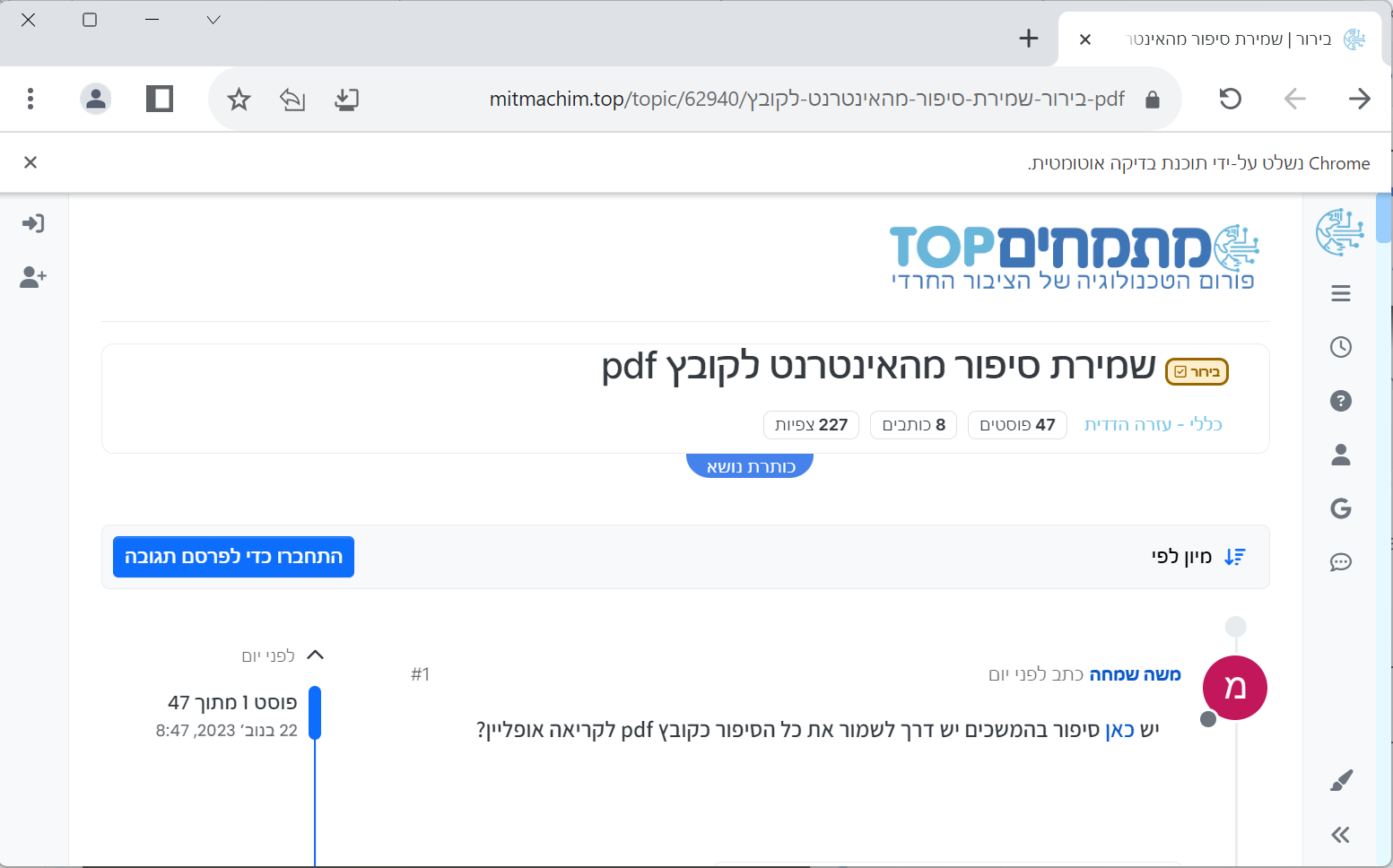
זהו לבינתיים, בהצלחה ענקית.
-
@הייתי-שמח-להבין @נחמן-פלח אני רואה שהתלהבתם, אז הנה דוגמה קטנה איך להשתמש בסלניום כדי לגלוש באתר מתמחים טופ.
ראשית יש להתקין פייתון כמובן. כדאי להקפיד לסמן בוי את האפשרות להגדיר PATH.
שנית יש להתקין את שתי הספריות הבאות:pip install selenium webdriver-managerהראשית היא סלניום - הספריה שנשתמש בה, והשני עוזר לנו להוריד ולהתקין אוטומטית את ה"דרייבר" - זהו בעצם החלק המקשר בין הקוד לבין הדפדפן.
נפתח קובץ פייתון חדש בשם surfMitmachimSelenium.py או כל שם מפוצץ אחר.
נתחיל בייבוא הספריות:
from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.by import Byאחר כך נוריד אוטומטית דרייבר לדפדפן כרום:
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))בתקווה שאין שגיאות (חסימה בנטפרי וכדו'), נמשיך לשורה הבאה: נגלוש באתר מתמחים.
driver.get("https://mitmachim.top/")כך נראה הדפדפן כרגע:
עכשיו דבר חשוב מאד: לפני שנלחץ על עוד אובייקט צריך לחכות לו ולא ללחוץ עליו לפני שהוא נטען. אז השורה הבאה נדרשת:
driver.implicitly_wait(2)אנחנו רוצים להיכנס לקטגוריה "כללי עזרה הדדית", אז אנחנו צריכים למצוא את הכתובת שלו במקור הדף בhtml.
אז כמובן לוחצים f12. לחיצה ימנית -> בדיקה ->לחיצה ימנית על הhtml -> העתק -> העתק נתיב xpath
צילום מסך:
יופי, עכשיו נמצא את האובייקט הדרוש לפי הכתובת שלו:
element = driver.find_element(By.XPATH,"/html/body/div[1]/main/div[2]/div/div[2]/div[1]/ul/li[9]/div[1]/div[2]/h2/a")נשים לב שהכתובת היא מה שהעתקנו מקודם.
נלחץ על השורה שמצאנו:element.click()עכשיו נחפש אלמנט בדרך אחרת, לא לפי כתובת אלא לפי חלק מהמחרוזת המופיעה בלינק. ונלחץ עליו:
element = driver.find_element(By.PARTIAL_LINK_TEXT,"pdf") element.click()זהו לבינתיים, בהצלחה ענקית.
-
@sivan22 לא זכיתי להבין למה ההדגמה הנ"ל משמשת, מה המטרה? להגיע למתמחים טופ אפשר ישירות עם הדפדפן.
@הייתי-שמח-להבין לא הבנתי את השאלה, ברור שזו רק הדגמה וקח את זה מכאן לאיפה שתרצה.
-
@הייתי-שמח-להבין לא הבנתי את השאלה, ברור שזו רק הדגמה וקח את זה מכאן לאיפה שתרצה.
-
@sivan22 למה ההדגמה, ל-איך אפשר לשלוף מידע מאפוא? סליחה על הבורות.
@הייתי-שמח-להבין למשל להשיג תור לדרכון ישראלי, או לבדוק אם ירד המחיר של אוזניות מסוימות, או אפילו לקנות את כל הסטוק מתחת למחיר מסויים. מה בשום פנים ואופן לא?! לחבר chatGPT בקצה השני ולהטריל את כל הפורום פה להנאתך עם איזה משתמש פיקטיבי.
-
@הייתי-שמח-להבין למשל להשיג תור לדרכון ישראלי, או לבדוק אם ירד המחיר של אוזניות מסוימות, או אפילו לקנות את כל הסטוק מתחת למחיר מסויים. מה בשום פנים ואופן לא?! לחבר chatGPT בקצה השני ולהטריל את כל הפורום פה להנאתך עם איזה משתמש פיקטיבי.
-
@הייתי-שמח-להבין למשל להשיג תור לדרכון ישראלי, או לבדוק אם ירד המחיר של אוזניות מסוימות, או אפילו לקנות את כל הסטוק מתחת למחיר מסויים. מה בשום פנים ואופן לא?! לחבר chatGPT בקצה השני ולהטריל את כל הפורום פה להנאתך עם איזה משתמש פיקטיבי.
-
@sivan22 אני חושב שהבנתי את הפוטנציאל של זה, הוא יכול לדלות נתונים על פי נוסחה קבועה מראש ולהביא אותם אוטומטית אלייך, בגדול זה גם יכול לעקוף מגבלות כניסה לאתרים, רק צריך שזה יהיה פתוח בהרצה הראשונה כמדומני.
@הייתי-שמח-להבין כמובן יש כלים נוספים לכריית נתונים, כמו beutifulsoup ואחרים, אבל זה הכי דומה לבן אדם, ולכן יכול לעשות כמעט כל דבר בלי להחסם.
-
@הייתי-שמח-להבין כמובן יש כלים נוספים לכריית נתונים, כמו beutifulsoup ואחרים, אבל זה הכי דומה לבן אדם, ולכן יכול לעשות כמעט כל דבר בלי להחסם.
@sivan22 תודה לך על ההסבר, אתה ממריץ אותי להתחיל להשקיע ברצינות יותר בלימודי פייתון.
שלום! נראה שהשיחה הזו מעניינת אותך, אבל עדיין אין לך חשבון.
נמאס לכם לגלול בין אותם הפוסטים בכל ביקור? כשנרשמים לחשבון, תמיד תחזרו בדיוק למקום שבו הייתם קודם, ותוכלו לבחור לקבל התראות על תגובות חדשות (בין אם במייל, ובין אם בהתראת פוש). תוכלו גם לשמור סימניות ולפרגן ב-upvote לפוסטים כדי להביע הערכה לחברי קהילה אחרים.
בעזרת התרומה שלך, הפוסט הזה יכול להיות אפילו טוב יותר 💗
הרשמה התחברות { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}