שלום רב לכל משתמשי הפורום היקרים
מדהים לראות איך הפורום גדל, וממשיך להיות במה לדברים שעוזרים כ"כ הרבה, לאנשים רבים כ"כ.
יש"כ עצום לר' @שמואל ול-@אלישי ושאר המשתמשים שכותבים ועוזרים ללא הרף.
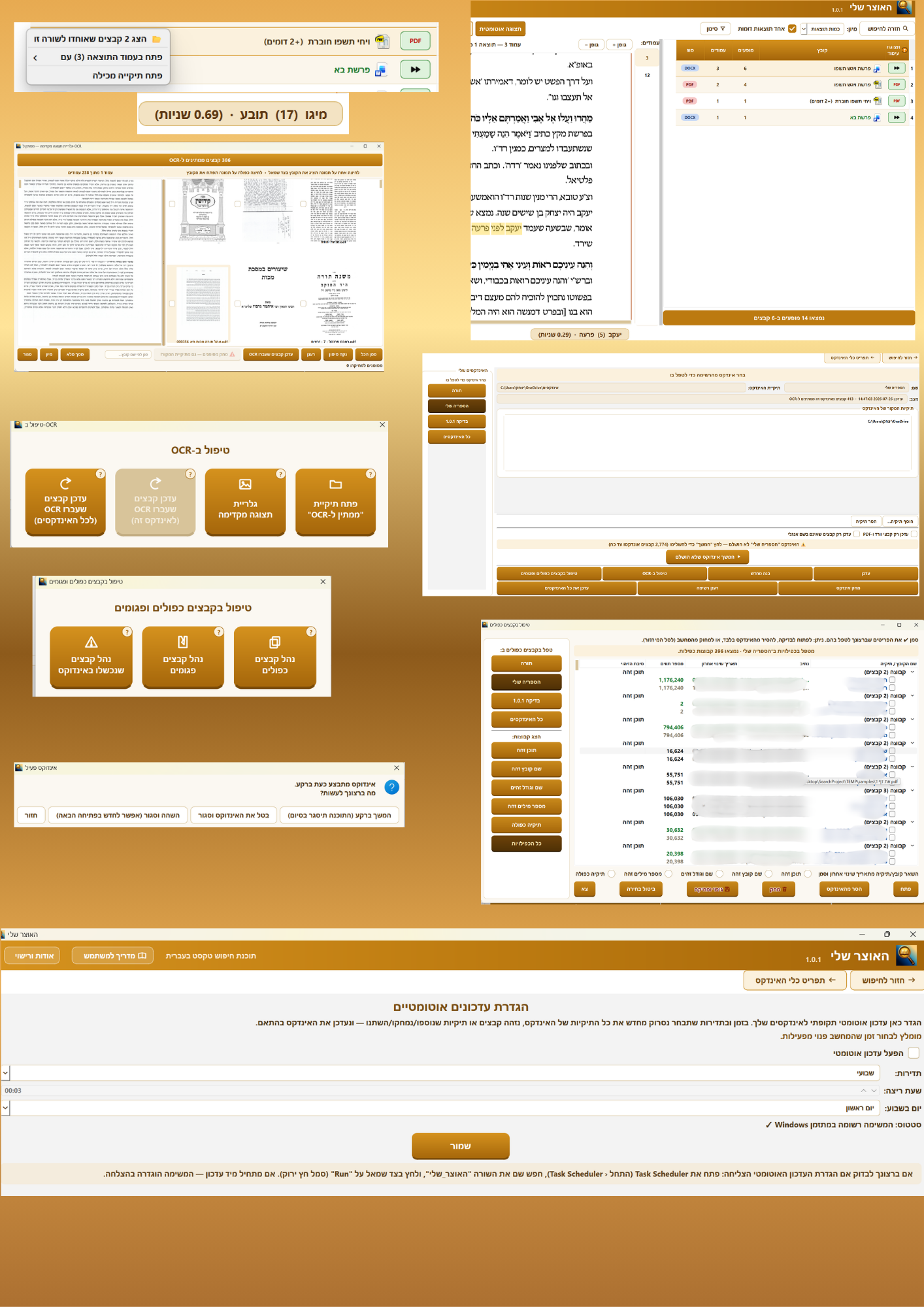
בזמנו השקעתי רבות באינדקס זה, ע"מ שיכיל את כל התוכנות שהיו אז בפורום.
כדי שהאינדקס ימשיך להיות אקטואלי, צריך לעתים תכופות לערוך, להוסיף ולגרוע וכו',
למעשה, אני כבר כמעט ולא נכנס לפורום, למעט מקרים דחופים שאני מחפש משהו מסויים וכדו'.
עקב פתיחת האפשרות בפלטפורמה, לתת הרשאת עריכה לפוסט גם למי שלא כתב את הפוסט, אני מחפש מישהו שמעוניין לערוך ולהוסיף, ולתקן וליעל את האינדקס לתועלת הכלל.
כמובן שיש צורך בהבנה מסויימת בתוכנות, ויכולת סידור וקטלוג.
מי שמעוניין נא לפנות אלי בפרטי בלבד!
תודה רבה והמון הצלחה לכולם.






 { const baseUrl = "https://www.google.co.il/search?q=site:mitmachim.top"; const m = location.pathname.match(/^\/(topic|category)\/(\d+)/); const type = m ? m[1] : null; const id = m ? m[2] : null; let searchInput; function search(path = "") { const query = searchInput.value.trim(); if (query) { window.open(`${baseUrl}${path}%20${encodeURIComponent(query)}`, "_blank"); } } let buttons = {}; buttons.searchAll = { id: "bb-search-all", label: `חיפוש ${type ? "בכל הפורום" : ""}`, className: type ? "btn-secondary" : "btn-primary", callback: () => search(), }; if (type === "topic") { buttons.searchTopic = { label: "חיפוש בנושא זה", className: "btn-primary", callback: () => search(`/topic/${id}`), }; } else if (type === "category") { buttons.searchCategory = { label: "חיפוש בקטגוריה זו", className: "btn-primary", callback: () => search(`/category/${id}`), }; } buttons.cancel = { label: "ביטול", className: "btn-default", "data-bs-dismiss": "modal" }; const dialog = bootbox.dialog({ title: '<div style="text-align:center;"><img src="/assets/uploads/files/1625950269825-mt-google.png" width="400" alt="חיפוש בגוגל"></div>', message: '<input id="bb-inp" class="bootbox-input bootbox-input-text form-control" placeholder="הקלידו כדי לחפש בגוגל" autocomplete="off"/>', buttons, backdrop: true, show: true, onEscape: true }); dialog.on("shown.bs.modal", function () { searchInput = document.getElementById("bb-inp"); if (searchInput) { searchInput.focus(); searchInput.addEventListener("keydown", function (e) { if (e.key === "Enter") { e.preventDefault(); const query = this.value.trim(); if (query) { search(); dialog.modal("hide"); } } else if (e.key === "Escape") { e.preventDefault(); dialog.modal("hide"); } }); } const searchAllButton = document.getElementById("bb-search-all"); if (searchAllButton) { searchAllButton.title = "לחצו על אנטר כדי לחפש"; } }); })(); void 0;){kind=link}